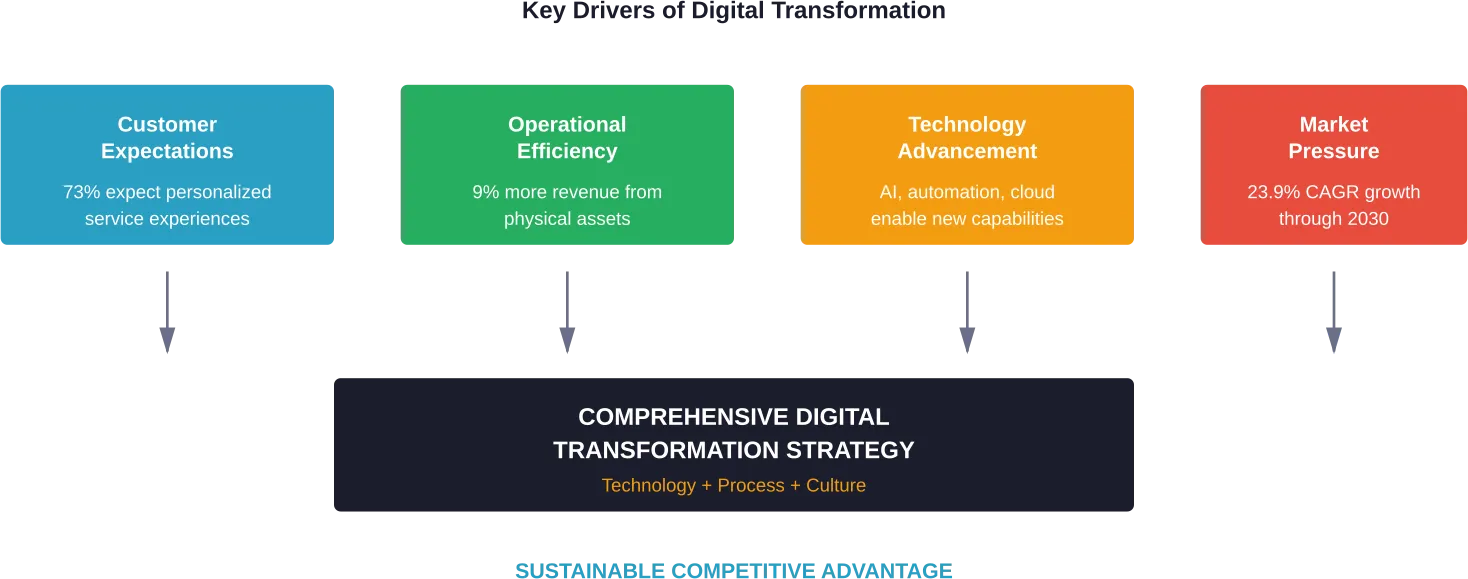
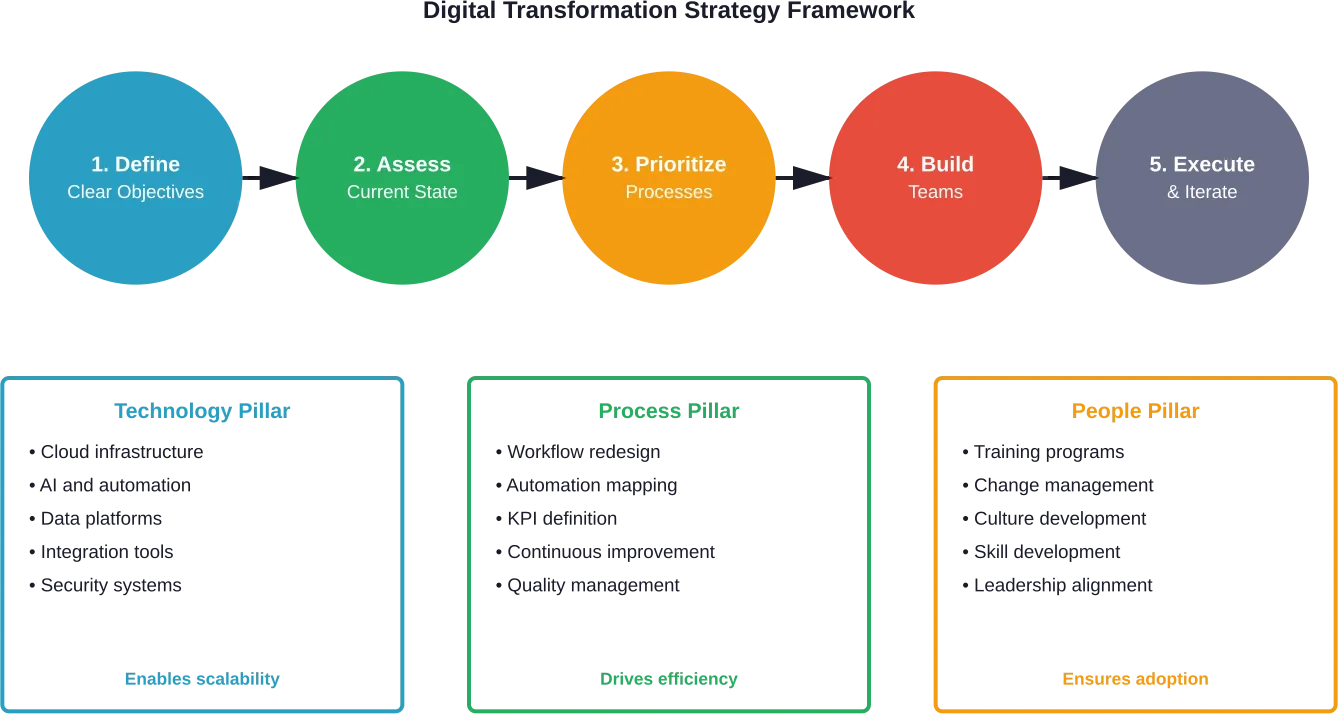
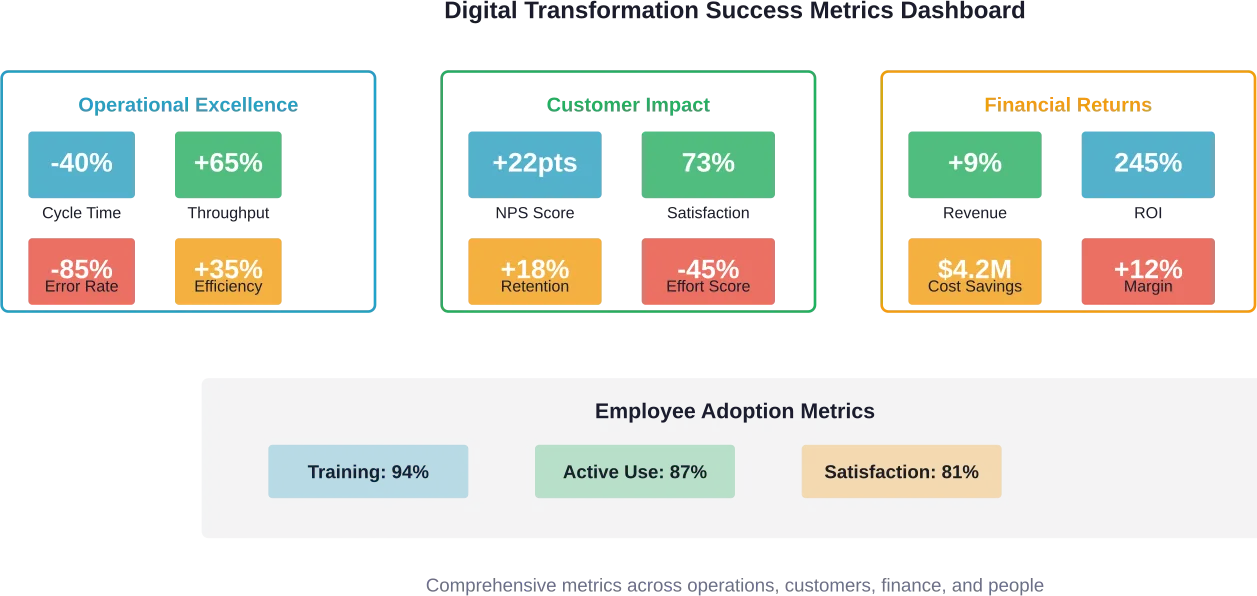
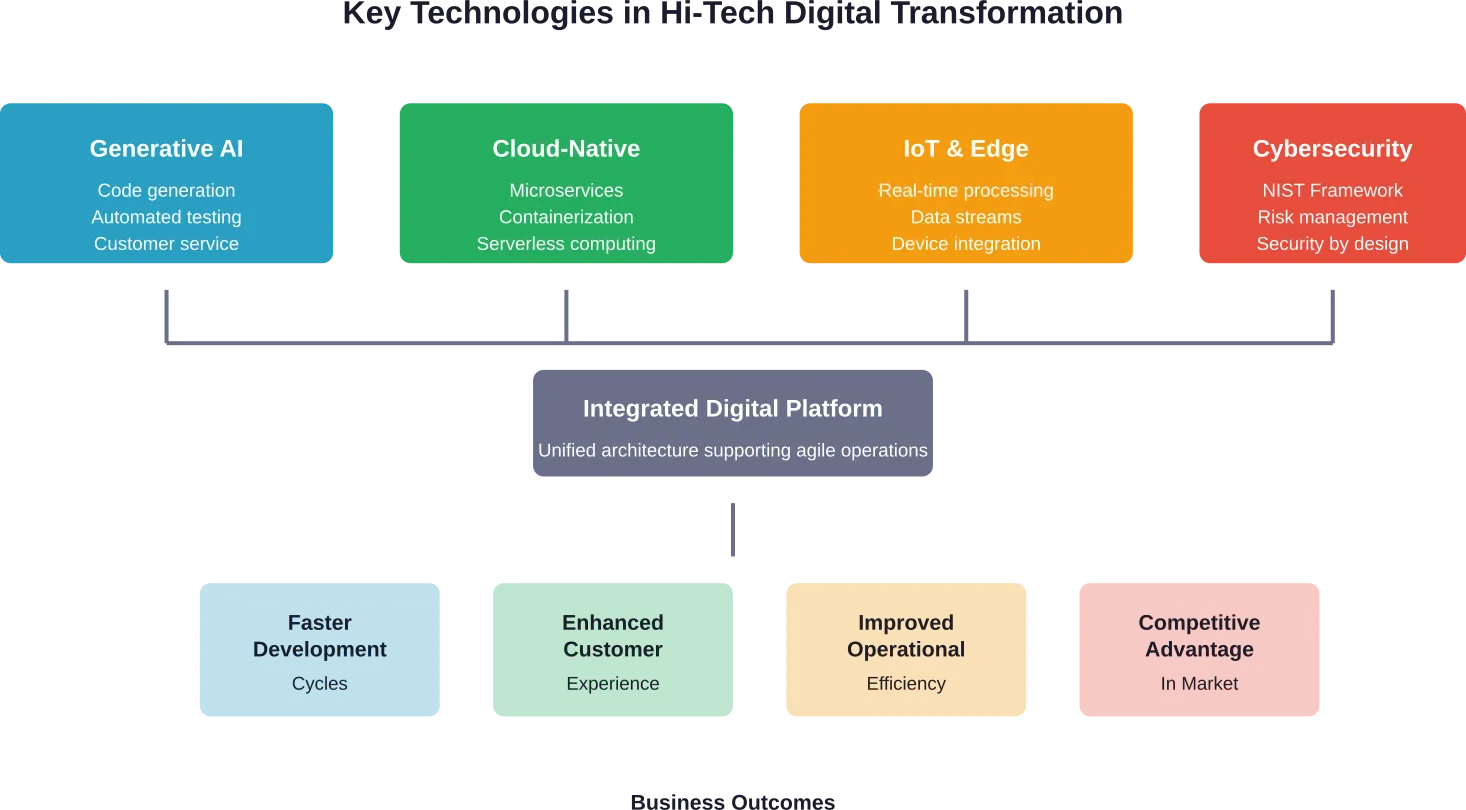
Choosing the right frontend development company can make or break your digital project. Whether you’re building a sleek website or a feature-packed app, you need a team that not only gets the job done but makes the whole process easier. In this article, we’re diving into what makes a great frontend company and who’s currently leading the pack.

1. A-listware
At A-listware, we specialize in helping businesses build and scale frontend solutions that work smoothly and look great. Our focus is on creating dedicated development teams that integrate seamlessly with our clients’ workflows. From the first stages of understanding a project to delivering code in regular sprints, we aim to make the development process feel straightforward and stress-free.
We work closely with clients across industries, making sure every solution we build matches real user needs and business goals. Whether it’s crafting clean interfaces, writing efficient code, or setting up reliable backend support, we handle each part of the process with care and clarity. Our approach centers on open communication, solid planning, and ongoing improvement.
Key Highlights:
- Over 20 years of experience in software development
- Strong focus on long-term partnerships
- Transparent communication throughout the project
- Agile delivery with sprint-based planning
- Trusted by global brands in various industries
Key Services:
- Frontend and Backend Development
- Web and Mobile App Development
- UI/UX Design
- QA and Testing
- IT Support and Consulting
- Data Analytics and Security Solutions
Contact and Social Media Information:
- Website: a-listware.com
- Phone: +1 (888) 337 93 73
- Email: info@a-listware.com
- Address: North Bergen, NJ 07047, USA
- LinkedIn: www.linkedin.com/company/a-listware/mycompany
- Facebook: www.facebook.com/alistware

2. Technext
Technext is a software development company that builds custom digital products for startups and small to mid-sized businesses. They manage the full development cycle for both web and mobile applications, using agile practices to stay flexible and responsive throughout a project. Their team supports everything from early-stage planning to launch, focusing on usability and long-term scalability.
They have worked across a wide range of industries, including travel, finance, education, and events. Their experience includes creating no-code platforms, internal business tools, and AI-driven applications. In addition to development, they offer design and consulting services to support clients through every stage of the product lifecycle.
Key Highlights:
- Over 12 years of experience in software development
- More than 400 completed projects
- Long-term focus on startups and SMBs
- Proven experience with AI integration and legacy system updates
Key Services:
- Frontend and Backend Development
- Web and Mobile Application Development
- UI/UX Design
- Dedicated Development Teams
- AI, Machine Learning, and IoT Integration
- Product Prototyping and Startup Support
Contact and Social Media Information:
- Website: technext.it
- Phone: +1 302 433 6002
- Email: reza@technext.it
- Address: 2810 N Church St, PMB 38894 Wilmington, DE, US 19802-4447
- LinkedIn: www.linkedin.com/company/technextlimited
- Facebook: www.facebook.com/TechnextLimited
- Instagram: www.instagram.com/technext.limited
- Twitter: x.com/TechnextLimited

3. Scopic
Scopic is a software development company that provides custom digital solutions for businesses across various industries. They offer services in web, mobile, and desktop application development, as well as UI/UX design, digital marketing, and cloud consulting. With a fully remote team, Scopic has completed over 1,000 projects since its founding in 2006, serving clients in sectors such as healthcare, finance, manufacturing, and entertainment.
Their approach involves collaborating closely with clients to understand their unique needs and delivering tailored software solutions. Scopic’s expertise extends to emerging technologies, including artificial intelligence, machine learning, and blockchain, enabling them to develop innovative applications that address complex business challenges.
Key Highlights:
- Established in 2006 with a fully remote, global team
- Completed over 1,000 projects across diverse industries
- Expertise in emerging technologies like AI, ML, and blockchain
- Offers end-to-end services from development to digital marketing
- Experience in sectors including healthcare, finance, and entertainment
Key Services:
- Custom Web, Mobile, and Desktop Application Development
- UI/UX Design
- Digital Marketing Services (SEO, PPC, Social Media)
- Cloud Consulting and Application Hosting
- AI and Machine Learning Solutions
- Blockchain Development
- Software Integration and Legacy System Modernization
Contact and Social Media Information:
- Website: scopicsoftware.com
- Phone: +1 (508) 886-3240
- Email: sales@scopicsoftware.com
- Address: Scopic Software, 11 Apex Dr Ste 300A PMB 2021, Marlborough MA 01752 US
- LinkedIn: www.linkedin.com/company/scopic-software
- Facebook: www.facebook.com/scopicsoftware
- Instagram: www.instagram.com/scopic_software
- Twitter: x.com/scopicsoftware

4. Plego Technologies
Plego Technologies is a software development company that offers a wide range of digital solutions tailored to various business needs. Their services encompass web design and development, mobile app creation, custom software solutions, and eCommerce platforms. With a focus on integrating advanced technologies, they provide services in artificial intelligence, machine learning, and data analytics. Their approach includes developing interactive digital experiences, such as virtual events and touchscreen applications, to enhance user engagement.
In addition to development services, Plego Technologies offers cloud operations and migration support, ensuring seamless transitions to platforms like AWS, Azure, and Google Cloud. They also provide quality assurance testing, digital marketing strategies, and creative services, including UI/UX design and branding. Their comprehensive service offerings are designed to support businesses from initial concept through to deployment and ongoing maintenance.
Key Highlights:
- Expertise in integrating advanced technologies like AI and machine learning
- Experience with clients across various industries, including healthcare, finance, and entertainment
- Offers end-to-end services from development to digital marketing
Key Services:
- Web Design and Development
- Mobile App Development
- Custom Software Solutions
- eCommerce Platform Development
- Artificial Intelligence and Machine Learning Integration
- Data Analytics and Business Intelligence
- Cloud Operations and Migration Support
- UI/UX Design and Branding
- Quality Assurance Testing
- Digital Marketing Strategies
Contact and Social Media Information:
- Website: plego.com
- Phone: 630-541-7929
- Email: sales@plego.com
- Address: 4949 Forest Ave, First Floor, Downers Grove, IL, 60515
- LinkedIn: www.linkedin.com/company/plego-technologies
- Facebook: www.facebook.com/plegotech
- Twitter: x.com/plegotech

5. Emergent Software
Emergent Software is a technology services company that delivers solutions across custom software development, website design, database management, and cloud consulting. They specialize in Microsoft technologies, including .NET, C#, SQL Server, Azure, and Power BI, offering end-to-end support for digital product development and infrastructure needs. Their team is composed of developers, database administrators, designers, and architects who work together to support projects from initial planning through to post-launch maintenance.
They provide long-term support for the applications and systems they build, aiming to establish lasting partnerships with their clients. Their work spans industries such as healthcare, finance, manufacturing, and professional services. Through a combination of technical expertise and structured project management, they help businesses design and maintain scalable software solutions.
Key Highlights:
- Founded in 2015 as a continuation of an earlier IT services company
- Focused expertise in Microsoft technologies
- Offers ongoing maintenance and support for built solutions
- Experience across a wide range of industries
- Emphasis on long-term client relationships
Key Services:
- Custom Software Development
- Website Design and Development
- Database Management and Analytics
- Azure Cloud Consulting
- DevOps and Infrastructure Services
- Technical Staffing and Augmentation
Contact and Social Media Information:
- Website: www.emergentsoftware.net
- Phone: 612-217-0747
- Email: hello@emergentsoftware.net
- Address: 1317 Marshall St NE, Minneapolis, MN 55413
- LinkedIn: www.linkedin.com/company/emergent-software
- Facebook: www.facebook.com/emergentsw
- Instagram: www.instagram.com/emergentsoftware
- Twitter: x.com/emergentsw

6. Bilberrry
Bilberrry is a digital innovation agency that designs and develops custom websites, applications, and digital experiences. They collaborate with clients to create tailored solutions that align with specific business goals. Their approach involves understanding client objectives and using their expertise to develop impactful digital products.
With a team of approximately 55 employees, Bilberrry has worked with a diverse range of organizations, including startups, nonprofits, and large enterprises. Their services encompass digital transformation, headless commerce development, custom software development, and website design. They also offer application modernization services to update legacy systems with modern technologies.
Key Highlights:
- Established in 2009
- Team of around 55 employees
- Experience with startups, nonprofits, and large enterprises
- Services include digital transformation and application modernization
Key Services:
- Digital Transformation
- Headless Commerce Development
- Custom Software Development
- Website Design & Development
- Application Modernization
Contact and Social Media Information:
- Website: bilberrry.com
- Phone: 206-818-7436
- Email: info@bilberrry.com
- Address: 600 1st Ave, Suite 413, Seattle, WA 98104

7. Savas Labs
Savas Labs is a digital agency that focuses on the design and development of custom websites, applications, and APIs. Their team works closely with clients to deliver digital products that are built around real user needs. With a strong emphasis on strategy, design, and engineering, they aim to create solutions that support specific business and organizational goals.
They offer services across several disciplines, including user experience design, technical consulting, and software development. Their portfolio spans a variety of industries such as higher education, healthcare, nonprofits, and technology. Through their internal innovation program, they also explore emerging technologies and concepts to stay ahead in the digital space.
Key Highlights:
- Focus on user-centered design and custom development
- Experience in education, healthcare, nonprofit, and tech sectors
- Integrated services combining strategy, design, and engineering
- Team-based collaboration across disciplines
- Active internal innovation initiatives
Key Services:
- Strategy and Technical Consulting
- UX and Visual Design
- Frontend and Backend Development
- API Design and Development
- Mobile App Development
- E-commerce Solutions
- Systems Integration
Contact and Social Media Information:
- Website: savaslabs.com
- Email: info@savaslabs.com
- LinkedIn: www.linkedin.com/company/savas-labs
- Instagram: www.instagram.com/savaslabs
- Twitter: x.com/savaslabs

8. 3 Media Web
3 Media Web is a digital agency that specializes in building and optimizing websites for growing organizations. They focus on creating scalable, user-friendly digital experiences that evolve alongside their clients’ business needs. Their team includes designers, developers, and digital strategists who work collaboratively to deliver tailored solutions.
Their services cover the full lifecycle of digital projects, from strategy and design to development and ongoing optimization. They have experience working with clients across various industries, including healthcare, education, and technology. Their approach emphasizes continuous improvement, ensuring that websites remain effective tools for achieving business objectives.
Key Highlights:
- Founded in 2001
- Specializes in WordPress-based solutions
- Experience across multiple industries
- Emphasis on long-term client relationships
Key Services:
- Web Strategy and Consulting
- Custom Web Design and Development
- Software Integrations
- Website Accessibility Compliance
- SEO Strategy and Content Marketing
- Paid Media Management and Lead Generation
- Technical Support and Hosting
Contact and Social Media Information:
- Website: www.3mediaweb.com
- Phone: +1 (877) 325-1131
- Email: sales@3mediaweb.com
- Address: 3 Media Web, 68 Harrison Ave Ste 605, PMB 74556, Boston, MA 02111-1929
- LinkedIn: www.linkedin.com/company/3-media-web-solutions-inc-

9. 247 Labs
247 Labs is a software development company that offers custom digital solutions for businesses across various industries. Their services include web and mobile application development, artificial intelligence integration, and IT consulting. They focus on delivering tailored solutions that address specific business challenges, such as digital transformation, business automation, and scaling talent.
With a team of experienced professionals, 247 Labs has completed numerous projects, emphasizing quality and innovation. They serve clients in sectors like healthcare, education, insurance, and retail, providing services that range from proof of concept development to full-scale application deployment.
Key Highlights:
- Over 10 years of experience in software development
- Completed more than 1,500 projects
- Team of over 70 experts
- Focus on industries such as healthcare, education, insurance, and retail
- Emphasis on ethical projects, avoiding sectors like gambling and adult content
Key Services:
- Custom Web Development
- Mobile App Development
- Artificial Intelligence and Machine Learning Solutions
- E-commerce Development
- Cybersecurity Services
- DevOps Support
- Staff Augmentation
- IT Consulting
Contact and Social Media Information:
- Website: 247labs.com
- Phone: 1-877-247-7421
- Email: hello@247labs.com
- Address: Toronto, 600 – 170 University Ave, Toronto, Ontario, M5H 3B3

10. Plank
Plank is a web design and development agency that collaborates with mission-driven organizations to create digital experiences. They focus on building websites that align with ethical principles, emphasizing accessibility, privacy, responsible development, and environmental impact. Their approach includes user-centered design and scalable development practices that prioritize clean, maintainable frontend code.
Founded in 1998, Plank has worked with clients across arts, education, and nonprofit sectors. Their services include frontend development with modern frameworks, responsive design, and accessibility compliance. The team emphasizes performance and usability, ensuring that each interface not only looks good but also works reliably across devices and platforms.
Key Highlights:
- Founded in 1998
- Certified B Corporation
- Strong focus on ethical design and development practices
- Experience with arts, education, and nonprofit clients
- Remote-first team model
Key Services:
- Custom Web Design and Development
- Frontend Development
- UX/UI Design
- Digital Strategy and Consulting
- WordPress Development
- Accessibility and Inclusion Services
- Privacy and Security Consulting
Contact and Social Media Information:
- Website: plank.co
- Phone: +1 514 875 0003
- Email: info@plank.co
- Address: 372 Ste-Catherine O, 101 Montreal, QC H3B1A2
- LinkedIn: www.linkedin.com/company/plank-multimedia
- Facebook: www.facebook.com/plankmtl
- Instagram: www.instagram.com/plankdesign

11. Monterail
Monterail is a software development company that specializes in building custom web and mobile applications. They offer end-to-end services, including product design, development, and maintenance, tailored to meet the specific needs of their clients. Their team comprises developers, designers, and project managers who collaborate to deliver scalable and user-friendly digital solutions.
With a focus on modern technologies, Monterail has experience working across various industries, such as healthcare, finance, and education. They emphasize a user-centered approach, ensuring that the applications they develop are both functional and intuitive. Their commitment to quality and continuous improvement is reflected in their development processes and client relationships.
Key Highlights:
- Over a decade of experience in software development
- Expertise in modern technologies and frameworks
- Collaborative approach with cross-functional teams
- Experience across multiple industries
- Emphasis on user-centered design and development
Key Services:
- Custom Web Application Development
- Mobile Application Development
- Product Design and UX/UI
- Frontend Development
- Backend Development and API Integration
- Quality Assurance and Testing
- Maintenance and Support Services
Contact and Social Media Information:
- Website: www.monterail.com
- Phone: +48 533 600 136
- Email: hello@monterail.com
- Address: Monterail Sp. z o.o., ul. Oławska 27-29, 50-123 Wrocław
- LinkedIn: www.linkedin.com/company/monterail
- Facebook: www.facebook.com/monterail

12. eLuminous Technologies
eLuminous Technologies is a software development company that offers a range of digital solutions tailored to businesses of various sizes. Their services encompass web and mobile application development, frontend development, and IT staff augmentation. With over two decades of experience, they have collaborated with clients across industries such as healthcare, finance, education, and retail.
Their team comprises certified developers skilled in technologies like Angular, React, and Vue.js, focusing on creating responsive and user-friendly interfaces. eLuminous Technologies emphasizes a client-centric approach, aiming to deliver solutions that align with specific business objectives and user needs.
Key Highlights:
- Established in 2002 with over 20 years of industry experience
- Team of 150+ certified developers
- Experience across multiple industries, including healthcare, finance, and education
- Emphasis on responsive and user-friendly frontend development
Key Services:
- Frontend Development (Angular, React, Vue.js)
- Web Application Development
- Mobile App Development
- IT Staff Augmentation
- AI and Machine Learning Solutions
- Data Analytics and Business Intelligence
- Quality Assurance and Testing Services
Contact and Social Media Information:
- Website: eluminoustechnologies.com
- Phone: +1 484 401 9147
- Email: sales@eluminoustechnologies.com
- Address: 708 3rd Ave, New York, NY, 10017
- LinkedIn: www.linkedin.com/company/eluminous-technologies
- Facebook: www.facebook.com/eluminoustech
- Instagram: www.instagram.com/eluminoustech
- Twitter: x.com/eluminoustech

13. MentorMate
MentorMate is a software development company that delivers custom digital solutions for businesses across various industries. With over two decades of experience, they offer services ranging from strategy and design to development and support. Their team comprises designers, developers, and consultants who collaborate to create scalable and user-friendly applications.
They have experience working with clients in sectors such as healthcare, finance, manufacturing, agriculture, and education. MentorMate emphasizes a user-centered approach, ensuring that the applications they develop align with clients’ business goals and provide intuitive user experiences.
Key Highlights:
- Founded in 2001 with over 20 years of industry experience
- Team of over 1,000 professionals across multiple countries
- Experience across various industries, including healthcare, finance, and education
- Emphasis on user-centered design and development
Key Services:
- Custom Web and Mobile Application Development
- UI/UX Design
- Cloud and DevOps Services
- Data Analytics and Business Intelligence
- Quality Assurance and Testing Services
- Support and Maintenance Services
Contact and Social Media Information:
- Website: mentormate.com
- Phone: +1 612 823 4000
- Email: accelerate@mentormate.com
- Address: 1350 Lagoon Ave, Suite 800, Minneapolis, MN 55408
- LinkedIn: www.linkedin.com/company/mentormate
- Facebook: www.facebook.com/MentorMate
- Instagram: www.instagram.com/mentormate

14. Netguru
Netguru is a digital consultancy that provides end-to-end support for building and scaling software products. Their services span product strategy, web and mobile development, cloud solutions, and design. They work with startups, enterprises, and innovation teams to create digital products that solve real problems and support business growth.
Their frontend development services are part of a broader software offering that includes both custom application development and ongoing product maintenance. They use modern technologies and frameworks to build responsive, accessible, and scalable user interfaces, focusing on user-centered design and performance optimization throughout the development process.
Key Highlights:
- Offers full-cycle digital product development
- Works with startups and large organizations across various industries
- Emphasizes collaboration, agility, and modern tech stacks
- Provides dedicated teams and flexible cooperation models
- Combines software development with strategic consulting
Key Services:
- Frontend Development
- Web and Mobile App Development
- Product Strategy and UX Design
- Cloud and DevOps Consulting
- AI and Data Engineering
- Quality Assurance and Maintenance
- Staff Augmentation and Team Extension
Contact and Social Media Information:
- Website: www.netguru.com
- Email: hello@netguru.com
- Address: Nowe Garbary Office Center, ul. Małe Garbary 9, 61-756 Poznań, Poland
- LinkedIn: www.linkedin.com/company/netguru
- Facebook: www.facebook.com/netguru
- Twitter: x.com/netguru

15. Experion Technologies
Experion Technologies provides digital product engineering and software development services. Their work spans several areas including application modernization, cloud engineering, platform development, and UI/UX design. Their teams support the development of user-centric digital solutions, from ideation through launch and maintenance.
Their frontend development services are part of a broader software offering, with capabilities in experience design that focus on human-centered UI and UX. They use established frontend technologies to develop interfaces that support larger product strategies. Their clients operate in industries such as healthcare, banking, logistics, education, and retail.
Key Highlights:
- Operating for over 19 years
- Team of more than 1,650 professionals
- Clients in over 37 countries
- Services delivered across multiple industries
- Works across product lifecycle from planning to support
Key Services:
- Frontend Development
- UI/UX Experience Design
- Custom Software Development
- Application Modernization
- Cloud Engineering and DevSecOps
- Platform and Embedded Engineering
- Data and AI Integration
- Cybersecurity Services
Contact and Social Media Information:
- Website: experionglobal.com
- Phone: (214)-983-8181
- Email: info@experionglobal.com
- Address: 6860 N Dallas Parkway, Suite 200, Plano, Texas 75024-4253
- LinkedIn: www.linkedin.com/company/experion-technologies
- Facebook: www.facebook.com/experiontechnologies
- Instagram: www.instagram.com/experion_technologies
- Twitter: x.com/experionglobal

16. Inoxoft
Inoxoft is a software development company that provides custom digital solutions across various industries. Their services encompass the entire software development lifecycle, including discovery, design, development, and ongoing support. Inoxoft’s team comprises developers, designers, and consultants who collaborate to deliver tailored solutions that align with clients’ business objectives.
In the realm of frontend development, Inoxoft offers services that focus on creating responsive and user-friendly interfaces. Their approach includes UI/UX design services aimed at enhancing user engagement and ensuring consistency across different platforms. These services are integrated with backend development and cloud solutions to provide comprehensive digital products.
Key Highlights:
- Established in 2014
- Team of over 170 professionals
- Experience across multiple industries, including healthcare, education, fintech, logistics
- Partnerships with Microsoft, Google Cloud, and ISTQB
Key Services:
- Frontend Development
- UI/UX Design
- Custom Web and Mobile Application Development
- Cloud Engineering and DevOps
- Data Analytics and AI Solutions
- Quality Assurance and Testing
- Dedicated Development Teams and Staff Augmentation
Contact and Social Media Information:
- Website: inoxoft.com
- Phone: (267) 310-2646
- Email: contact@inoxoft.com
- Address: 1601 Market Street, 19th Floor, Philadelphia, PA 19103
- LinkedIn: www.linkedin.com/company/inoxoft
- Facebook: www.facebook.com/inoxoft
- Instagram: www.instagram.com/inoxoft_team
- Twitter: x.com/InoXoft_Inc

17. Cheesecake Labs
Cheesecake Labs is a nearshore software design and development company that offers end-to-end digital product solutions. Since 2013, they have delivered over 300 projects, including mobile apps, web platforms, and emerging technology integrations. Their team includes engineers, designers, and product strategists who work with clients ranging from startups to large enterprises.
Their frontend development services utilize frameworks such as ReactJS, React Native, and Flutter to build responsive and scalable user interfaces. These services are integrated into their broader offerings, which include product strategy, UI/UX design, backend development, and cloud infrastructure. Cheesecake Labs provides flexible collaboration models, including dedicated teams and staff augmentation, to support various project needs.
Key Highlights:
- Team of over 100 professionals
- Completed more than 300 projects
- Experience across industries such as fintech, e-commerce, healthcare, and IoT
- Nearshore development model with teams operating in Latin America
Key Services:
- Frontend Development (ReactJS, React Native, Flutter)
- Mobile and Web Application Development
- UI/UX Design
- Backend Development (Python, Node.js, Go)
- Cloud Architecture and DevOps (AWS, Google Cloud, Azure)
- Emerging Technologies (Blockchain, AI, IoT)
- Staff Augmentation and Dedicated Teams
Contact and Social Media Information:
- Website: cheesecakelabs.com
- Phone: (415) 766 8860
- Email: info@cheesecakelabs.com
- Address: San Francisco, 391 Sutter St, Suite 704
- LinkedIn: www.linkedin.com/company/cheesecake-labs
- Facebook: www.facebook.com/cheesecakelabs
- Instagram: www.instagram.com/cheesecakelabs
- Twitter: x.com/cheesecakelabs

18. Unified Infotech
Unified Infotech is a digital product engineering company that offers a range of software development services, including frontend development. Their frontend development services utilize technologies such as JavaScript, React, Angular, and Vue.js to create responsive and user-friendly interfaces. These services are integrated with backend development, UI/UX design, and cloud solutions to provide comprehensive digital products.
They have experience working with clients across various industries, including healthcare, finance, education, and retail. Their approach includes a focus on user-centered design, ensuring that the applications they develop align with clients’ business objectives and provide intuitive user experiences.
Key Highlights:
- Offers comprehensive software development services
- Experience across multiple industries
- Emphasis on user-centered design and development
- Utilizes modern frontend technologies
- Provides integrated solutions combining frontend and backend development
Key Services:
- Frontend Development (JavaScript, React, Angular, Vue.js)
- UI/UX Design
- Backend Development
- Web and Mobile Application Development
- Cloud Engineering and DevOps
- Quality Assurance and Testing
- Custom Software Development
Contact and Social Media Information:
- Website: www.unifiedinfotech.net
- Phone: +1 929-240-9456
- Email: hello@unifiedinfotech.net
- Address: 79 Madison Avenue, #207, New York, NY 10016
- LinkedIn: www.linkedin.com/company/unifiedinfotech
- Facebook: www.facebook.com/unifiedinfotech
- Instagram: www.instagram.com/unified.infotech
- Twitter: x.com/unified_infotec

19. Kwanso
Kwanso is a software development company that provides custom digital solutions across various industries. Their services encompass the entire software development lifecycle, including strategy, design, development, and ongoing support. Kwanso’s team comprises developers, designers, and consultants who collaborate to deliver tailored solutions that align with clients’ business objectives.
In the realm of frontend development, Kwanso offers services that focus on creating responsive and user-friendly interfaces. Their approach includes UI/UX design services aimed at enhancing user engagement and ensuring consistency across different platforms. These services are integrated with backend development and cloud solutions to provide comprehensive digital products.
Key Highlights:
- Provides end-to-end software development services
- Experience across multiple industries
- Emphasis on user-centered design and development
- Utilizes modern frontend technologies
- Offers flexible engagement models
Key Services:
- Artificial Intelligence Solutions
- Application Development
- Cloud and Database Services
- Compliance Solutions
Contact and Social Media Information:
- Website: kwanso.com
- Phone: +1 (415) 689-8565
- Email: hello@kwanso.com
- Address: 2261 Market Street #4829, San Francisco, California 94114, United States
- LinkedIn: www.linkedin.com/company/kwanso
- Facebook: www.facebook.com/teamkwanso
- Instagram: www.instagram.com/lifeatkwanso
- Twitter: x.com/teamkwanso

20. Miquido
Miquido is a digital product development company that delivers end-to-end software solutions, from idea to deployment. Their services span product strategy, UX/UI design, web and mobile development, artificial intelligence, and cloud services. They work with organizations in sectors such as fintech, healthcare, entertainment, and eCommerce, providing tailored solutions for each use case.
Their frontend development offerings are part of a broader suite of web and mobile services. Miquido uses technologies like Angular and React to build responsive, scalable user interfaces that integrate with backend systems and cloud environments. Their design and development teams collaborate closely to ensure consistent and efficient product delivery across platforms.
Key Highlights:
- Covers the full digital product lifecycle from strategy to launch
- Works across multiple industries, including travel, banking, healthcare, and entertainment
- Offers specialized AI capabilities integrated into development processes
- Uses cross-functional teams for design, development, and deployment
- Supports modernization and optimization of legacy systems
Key Services:
- Product Strategy and Market Research
- UX Design, UI Design, and UX Audit
- Web and Mobile App Development
- Frontend Development (React, Angular)
- AI Solutions (Machine Learning, Computer Vision, Chatbots)
- Cloud Services and Legacy App Modernisation
- Project Takeover and Ongoing Optimization
Contact and Social Media Information:
- Website: www.miquido.com
- Phone: +48 536 083 559
- Email: hello@miquido.com
- Address: Zabłocie 43a, 30-701 Kraków, VAT-UE: 9452138173
- LinkedIn: www.linkedin.com/company/miquido
- Facebook: www.facebook.com/miquido
- Instagram: www.instagram.com/miquido
- Twitter: x.com/miquido

21. Lengreo
Lengreo is a digital agency that combines frontend web development with SaaS-focused digital marketing services. The company works with B2B SaaS, software development, fintech, AI, and healthcare companies, helping them build and optimize websites that support lead generation and business growth.
Their frontend development services include custom website development, UI-focused web design, and optimization of digital experiences for conversion and usability. Alongside development, Lengreo also provides SEO, AI-driven SEO strategies, and digital marketing services tailored for SaaS businesses.
Key Highlights:
- Focus on SaaS and B2B digital platforms
- Experience with custom web development and frontend optimization
- Works with AI, fintech, healthcare, and software companies
- Combines development services with digital marketing expertise
Services:
- Frontend Development
- Custom Website Development
- UI/UX-Focused Web Design
- SEO and AI-SEO Services
- SaaS Digital Marketing Strategy
Contact Information:
- Website: lengreo.com
- Email: hi@lengreo.com
- LinkedIn: www.linkedin.com/company/lengreo
- Instagram: www.instagram.com/lengreo.agency
- Twitter: x.com/Lengreo
- Address: Vrijstraat 9 C/D, 5611 AT Eindhoven, Netherlands
- Phone: +31 686 147 566

22. Mobian
Mobian is a software development company that builds frontend-driven digital platforms and enterprise applications for healthcare and technology businesses. Their solutions focus on usability, accessibility, and seamless integration with cloud services, APIs, and external systems.
The company develops responsive web and mobile interfaces for telemedicine systems, remote patient monitoring platforms, and enterprise tools. Mobian combines frontend engineering with scalable backend infrastructure to deliver secure and high-performance digital products.
Key Highlights:
- Focus on frontend solutions for healthcare and enterprise platforms
- Experience with responsive and accessibility-oriented interfaces
- Works with cloud integrations and connected systems
- Builds scalable web and mobile applications
Services:
- Frontend Development
- Web and Mobile Application Development
- UI/UX Design
- Cloud and API Integrations
- Healthcare Platform Development
Contact Information:
- Website: mobian.studio
- Email: info@mobian.studio
- LinkedIn: www.linkedin.com/company/mobian-studio
- Address: Harju maakond, Tallinn, Kesklinna linnaosa, Masina tn 22, 10

23. Gilzor
Gilzor is a software development company that creates custom web applications and frontend solutions for startups, SMBs, and product companies. The company focuses on building modern digital products with responsive interfaces, scalable architectures, and user-centered experiences.
Their frontend development services include React-based web applications, UI/UX design implementation, and full-cycle product development. Gilzor also supports businesses with ongoing maintenance, quality assurance, and optimization of digital platforms.
Key Highlights:
- Focus on frontend and custom web application development
- Experience working with startups and SMBs
- Full-cycle software product development services
- Emphasis on responsive UI and user experience
Services:
- Frontend Development
- Web Application Development
- UI/UX Design
- Quality Assurance and Testing
- Support and Maintenance
Contact Information:
- Website: www.gilzor.com
- Email: contacts@gilzor.com
- LinkedIn: www.linkedin.com/company/gilzor-softwaredevelopment
- Address: Office 58, street Adama Mickiewicza 37, 01-625, Warsaw, Poland

24. Oski Solutions
Oski Solutions is a software development company that delivers frontend and enterprise web solutions for businesses across industries such as fintech, healthcare, logistics, and e-commerce. The company focuses on building responsive, scalable, and user-friendly interfaces using modern frontend technologies and cloud-based architectures.
Their frontend development services include web application engineering, UI/UX implementation, React and Angular development, and integration with backend and cloud systems. Oski Solutions also works with DevOps and CI/CD processes to ensure performance, scalability, and smooth deployment workflows.
Key Highlights:
- Focus on responsive and scalable frontend solutions
- Experience with cloud-based enterprise applications
- Works with fintech, healthcare, and logistics companies
- Uses modern frontend frameworks and DevOps practices
Services:
- Frontend Development
- Web Application Development
- UI/UX Implementation
- Cloud and API Integrations
- DevOps and CI/CD Services
Contact Information:
- Website: oski.site
- Email: contact@oski.site
- LinkedIn: www.linkedin.com/company/oski-solutions
- Address: Kaupmehe tn 7-120, Tallinn, Estonia
- Phone: +48571282759
Conclusion
Choosing the right frontend development company can have a big impact on how your digital product performs and evolves. Whether you’re building from scratch or improving an existing platform, partnering with a team that understands your goals and brings the right technical skills to the table is essential. The companies featured in this article each bring their own strengths, from user-focused design to expertise in modern frontend frameworks, making them solid options for a range of projects and industries.
As frontend technologies continue to advance, the demand for clean, responsive, and accessible interfaces will only grow. Businesses that prioritize the user experience and stay aligned with modern development practices are more likely to stand out and succeed. Working with a trusted frontend development company not only helps bring your ideas to life but also ensures that your product remains scalable and adaptable as needs change over time.