Kurze Zusammenfassung: AI agent frameworks provide the foundational infrastructure for building autonomous AI systems that can perceive, reason, and act. Leading frameworks like LangGraph, CrewAI, and Microsoft Agent Framework offer different architectures—from stateful graph-based orchestration to multi-agent collaboration systems—each suited for specific use cases ranging from simple task automation to complex enterprise workflows.
The shift from traditional large language models to autonomous AI agents represents one of the most significant transformations in artificial intelligence. But here’s the thing—building agents that actually work in production requires more than just stringing together a few API calls.
Agent frameworks emerged to solve this exact problem. They provide the architectural patterns, orchestration tools, and integration capabilities needed to transform experimental prototypes into reliable systems. According to research published on arXiv, these frameworks function as an “operating system” for agents, reducing hallucination rates by transforming unstructured chat into rigorous workflows.
The landscape has evolved dramatically. What started with experimental projects like AutoGPT has matured into enterprise-grade platforms supporting everything from customer service automation to complex multi-agent supply chain systems. And the differences between frameworks matter more than most developers initially realize.
This guide cuts through the hype. No fluff, no invented benchmarks—just practical analysis based on what actually ships to production.
What Makes AI Agent Frameworks Different
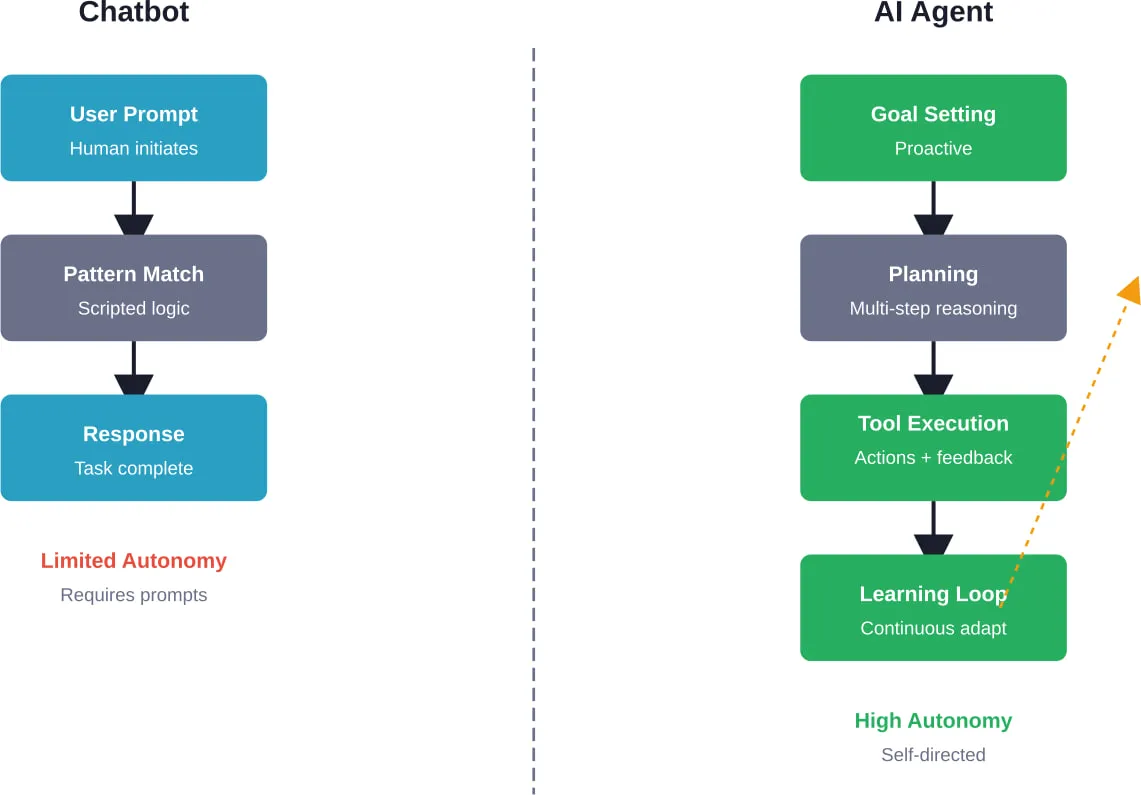
Traditional LLM applications follow a simple pattern: input goes in, response comes out. Agents break that model entirely.
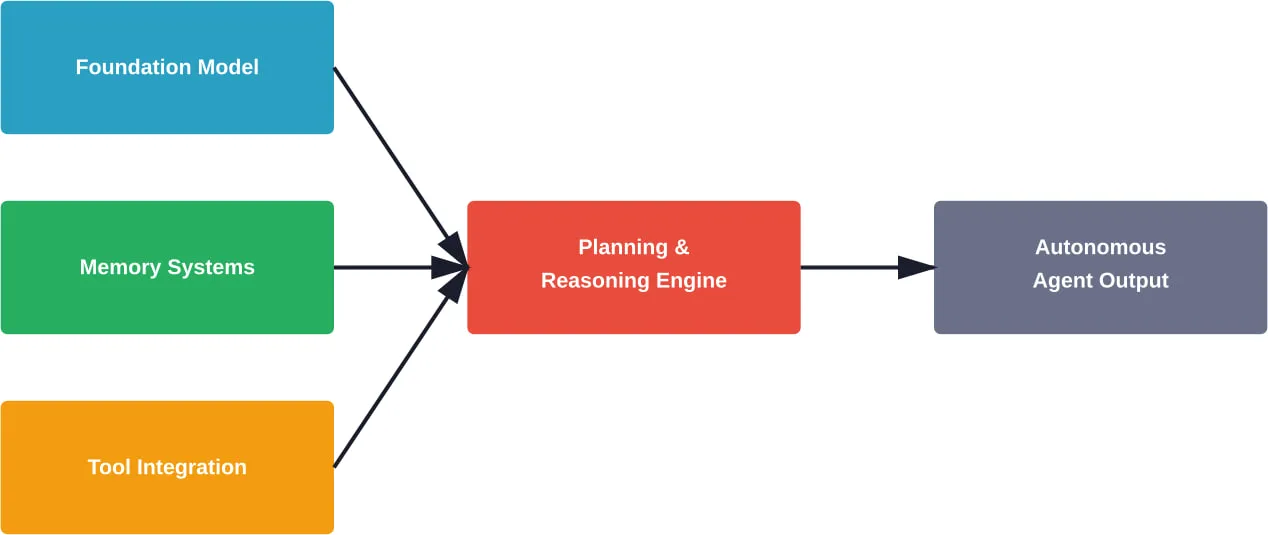
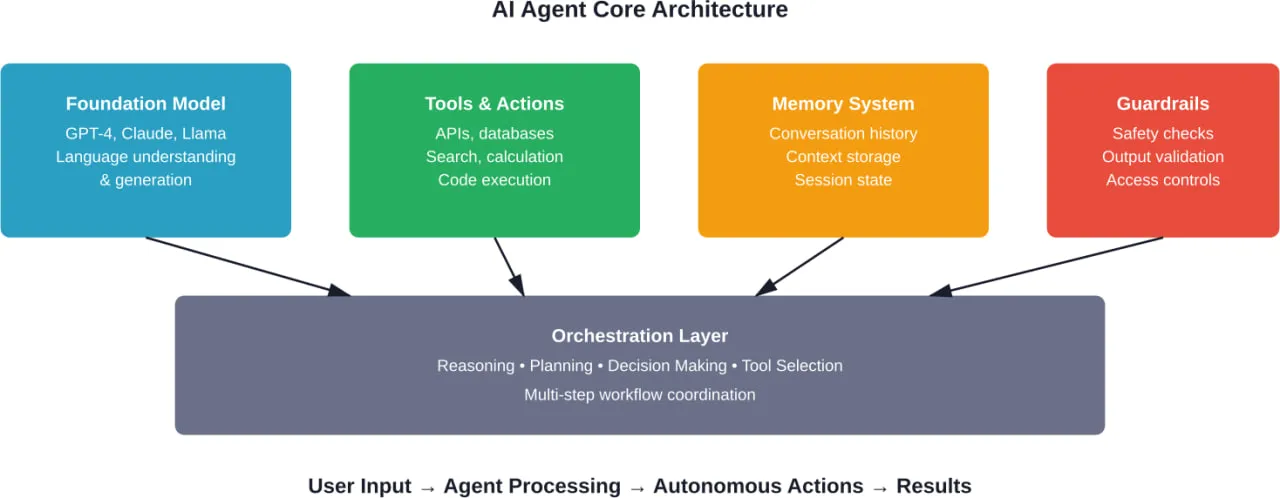
An AI agent framework provides the infrastructure for systems that can perceive their environment, make autonomous decisions, use tools, maintain state across interactions, and execute multi-step workflows. According to arXiv research distinguishing AI Agents from Agentic AI, these frameworks are “modular systems driven by LLMs” with fundamentally different design philosophies than simple chatbots.
The core components typically include:
- Orchestration engines that manage agent lifecycles and task execution
- Memory systems for short-term and long-term state persistence
- Tool integration layers that let agents interact with external systems
- Reasoning loops that enable planning and self-correction
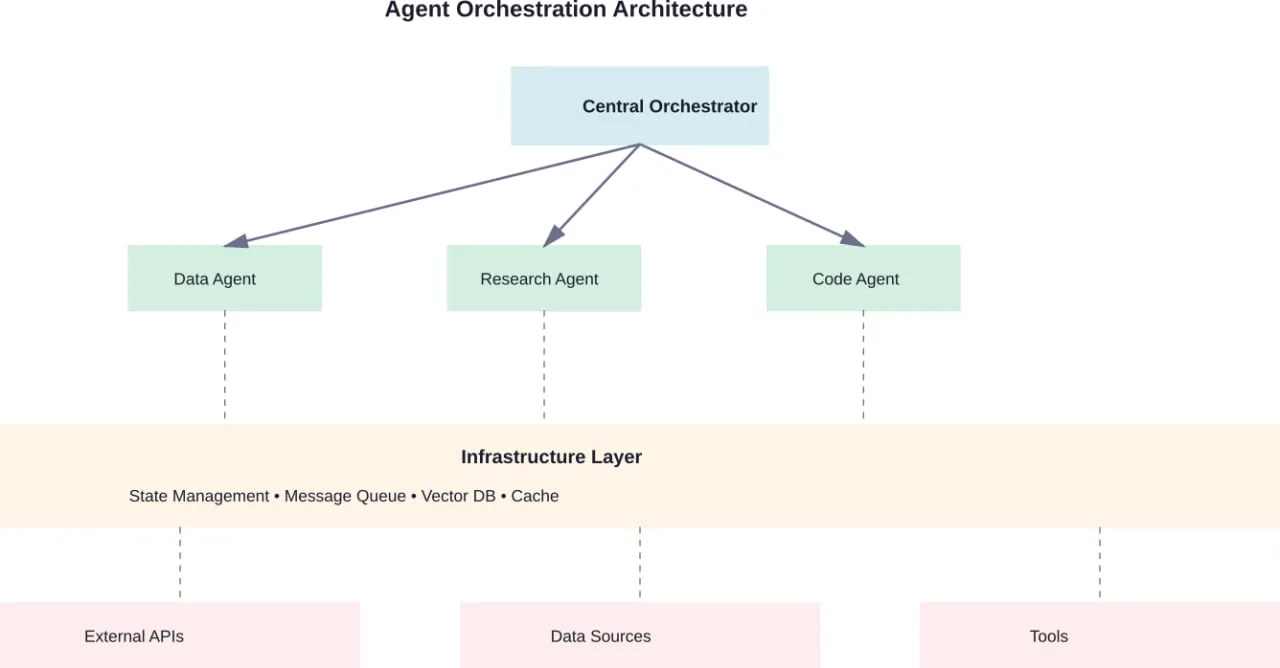
- Multi-agent coordination protocols for collaborative workflows
But not all frameworks implement these components the same way. Some prioritize graph-based state management, others focus on conversational flows, and some specialize in multi-agent orchestration.
The Architecture Question That Defines Everything
According to arXiv’s taxonomy of architecture options for foundation model-based agents, the fundamental architectural choice determines everything downstream. Frameworks generally fall into three categories:
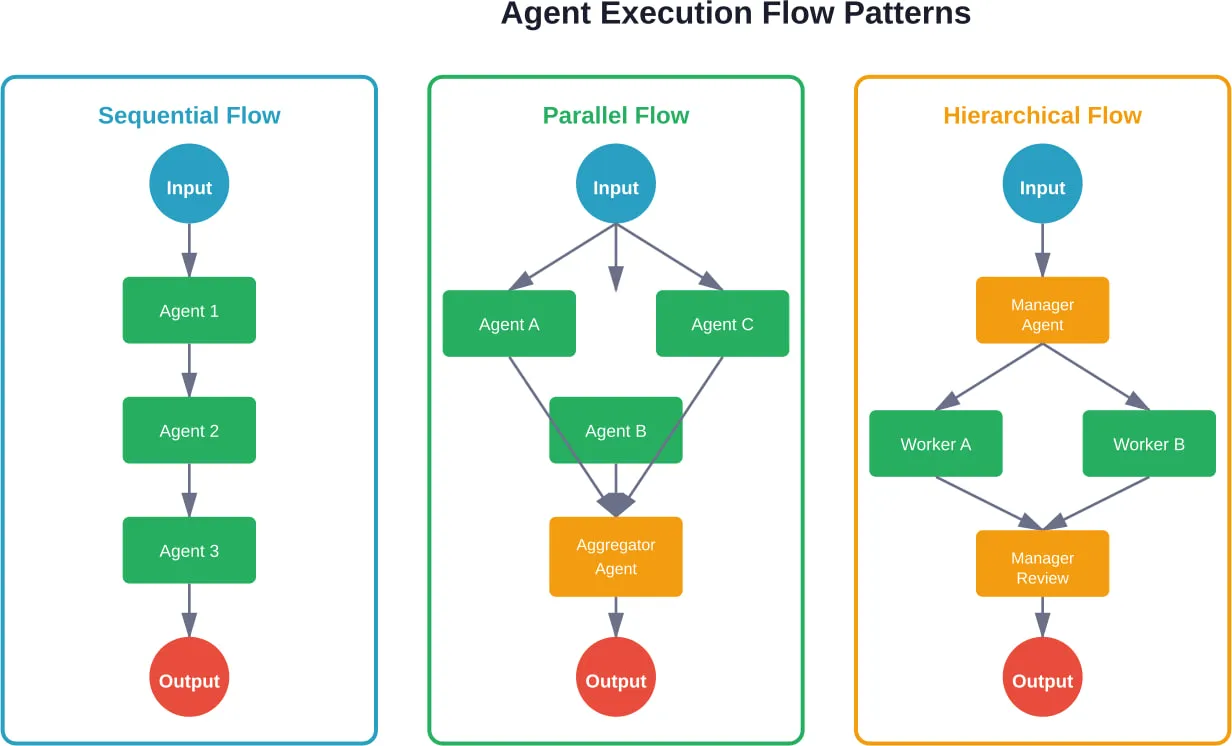
- Stateful graph-based systems treat agent execution as a directed graph where nodes represent states or actions. This approach excels at complex workflows with conditional branching, parallel execution, and explicit state management.
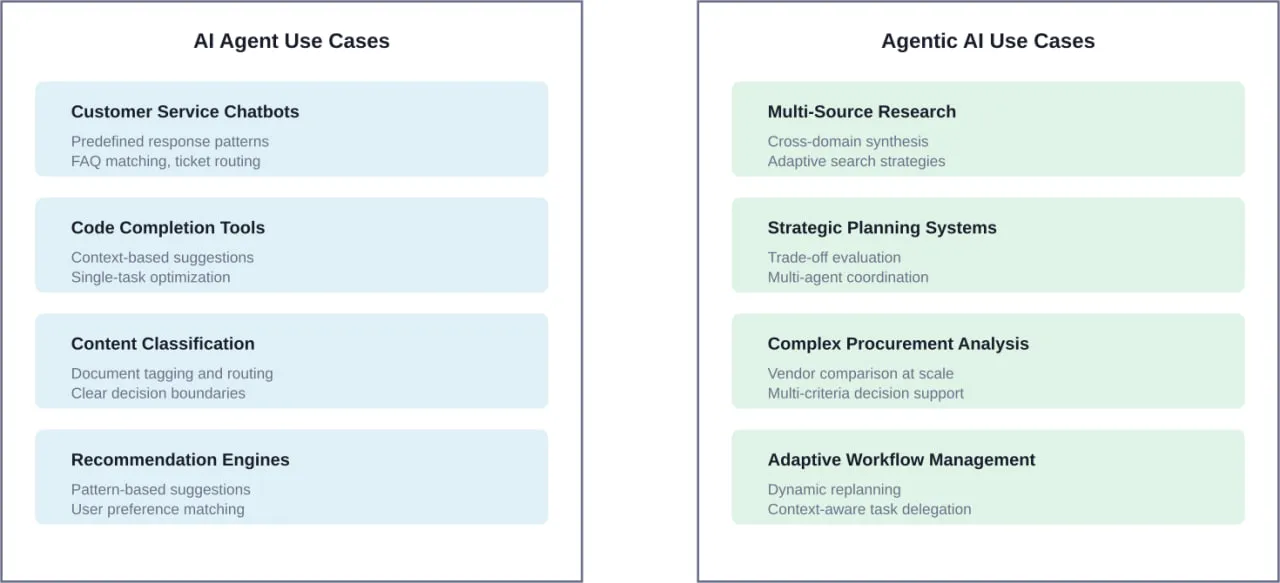
- Conversational frameworks model agents as enhanced chatbots with tool access. They work well for customer-facing applications where natural dialogue matters more than complex orchestration.
- Multi-agent systems distribute tasks across specialized agents that communicate and collaborate. Research shows this pattern works particularly well for simulating organizational structures—like ChatDev, which simulates an entire software company where agents self-organize into design, coding, and testing roles.
The architecture choice isn’t just technical preference. It fundamentally constrains what types of applications become natural versus painful to build.
The Production-Grade Frameworks Worth Considering
Plenty of agent frameworks exist. Most don’t survive contact with production requirements. Here are the ones that do, based on actual deployment experience documented across the ecosystem.
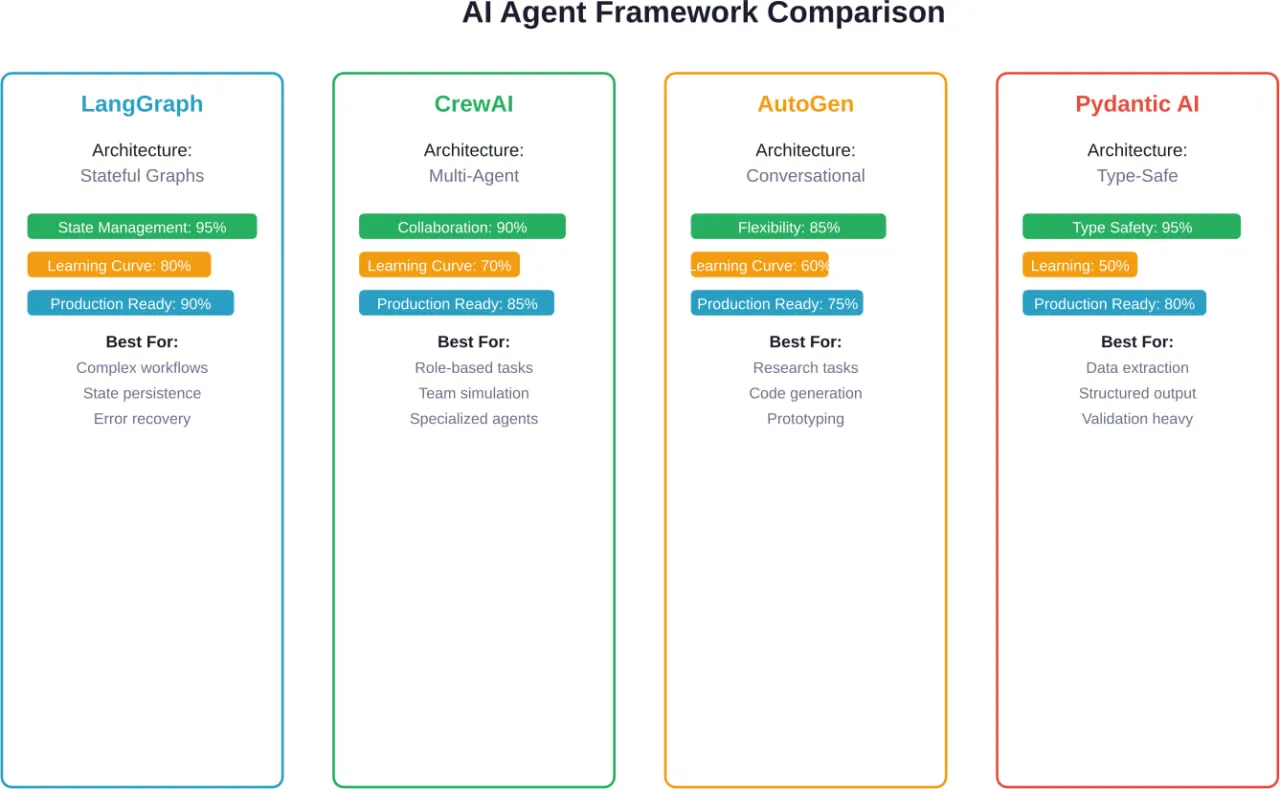
LangGraph: When State Management Matters
LangGraph approaches agent orchestration through stateful graphs. Each node represents a function, edges define transitions, and state flows through the graph with explicit persistence.
The framework has 24.8k GitHub stars and sees 34.5 million monthly downloads—numbers that reflect genuine production adoption, not just experimental interest. According to analysis from practitioners who’ve shipped with multiple frameworks, LangGraph sits in the top tier for systems that survive production.
Key capabilities include:
- Explicit state management with configurable persistence backends
- Human-in-the-loop workflows with approval gates
- Support for both single-agent and multi-agent architectures
- Time-travel debugging through state snapshots
- Native streaming support for real-time updates
The trade-off? LangGraph requires more upfront architectural thinking. Developers need to explicitly model state transitions rather than relying on implicit conversational flow. For complex enterprise workflows with branching logic and error recovery requirements, that explicitness becomes an advantage.
Real talk: LangGraph works best when the problem domain has clear states and transitions. Customer support escalation workflows, multi-step approval processes, and research pipelines with conditional branching all map naturally to its graph paradigm.
CrewAI: Multi-Agent Collaboration Made Practical
CrewAI specializes in coordinating multiple agents working toward shared goals. The framework models agents as team members with defined roles, responsibilities, and communication patterns.
The core abstraction centers on “crews”—groups of agents that collaborate on tasks. Each agent has a role, a goal, tools they can use, and a backstory that influences their behavior. Tasks get assigned to agents based on their capabilities, and the framework handles inter-agent communication.
This approach shines for problems that naturally decompose into specialized roles. Content creation workflows might have a researcher agent, a writer agent, and an editor agent. Financial analysis might involve data collection agents, analysis agents, and reporting agents.
CrewAI supports multiple collaboration patterns:
- Sequential execution where agents work one after another
- Hierarchical structures with manager agents delegating to specialists
- Consensus mechanisms where multiple agents vote on decisions
The framework appears frequently in rankings of top agent frameworks for 2026, particularly for use cases requiring domain expertise segregation. But it carries more orchestration overhead than single-agent systems—appropriate for complex workflows, overkill for simple automation.
Microsoft Agent Framework: Enterprise Integration First
Microsoft’s Agent Framework takes a different approach, prioritizing enterprise requirements like security, compliance, and integration with existing Microsoft ecosystems.
According to official documentation, Microsoft Agent Framework supports building agents and multi-agent workflows in both .NET and Python. It includes built-in integration with Azure OpenAI, OpenAI, Anthropic, and Ollama, plus native support for Model Context Protocol (MCP) servers.
Key enterprise features include:
| Merkmal | Beschreibung |
|---|
| Agents | Individual agents using LLMs to process inputs, call tools and MCP servers, generate responses |
| Workflows | Multi-agent orchestration with defined task dependencies |
| MCP Support | Native integration with Model Context Protocol for standardized tool access |
| Sicherheit | Enterprise-grade authentication, authorization, and audit logging |
The framework targets organizations already invested in Microsoft’s ecosystem. For teams running Azure infrastructure and using Microsoft’s AI services, the integration friction drops significantly. For everyone else, the vendor lock-in concerns require careful evaluation.
AutoGen: Research Meets Production
Originally from Microsoft Research, AutoGen focuses on conversational multi-agent systems. The framework enables agents to have conversations with each other to solve tasks collaboratively.
AutoGen’s distinctive feature is its conversational paradigm. Rather than explicitly modeling workflows or state transitions, developers define agents with capabilities and let them negotiate task execution through dialogue. This works particularly well for open-ended problems where the solution path isn’t predetermined.
The framework supports:
- Automated code generation and execution
- Tool use through function calling
- Human-in-the-loop interaction patterns
- Configurable conversation patterns and termination conditions
According to practitioners who have shipped with multiple frameworks, AutoGen works well for prototyping. The conversational approach can make debugging complex workflows challenging when agents make unexpected decisions.
Pydantic AI: Type Safety for Agent Development
Pydantic AI brings the type safety and validation capabilities of Pydantic to agent development. For teams already using Pydantic for data validation in Python applications, this framework provides familiar patterns.
The core value proposition centers on structured outputs. Developers define Pydantic schemas describing expected agent responses, and the framework handles validation and type coercion. This reduces the hallucination problem by constraining outputs to match expected structures.
Works well for:
- Data extraction tasks with defined output schemas
- Classification and categorization workflows
- Structured report generation
- Any use case where output format matters as much as content
The limitation? Pydantic AI remains primarily focused on single-agent scenarios with structured outputs. Complex multi-agent orchestration or workflows requiring sophisticated state management need additional tooling.
Firecrawl: Web Data Collection as an Agent
Firecrawl takes a specialized approach, focusing specifically on web data collection through an agentic interface. Rather than building general-purpose agents, it optimizes for the common pattern of searching, navigating, and extracting structured data from websites.
According to the project documentation, developers describe what they want in plain text, optionally pass a Pydantic schema, and the agent searches, navigates, and returns structured results. Firecrawl offers multiple models with different performance-cost trade-offs for straightforward versus complex extractions.
This specialized focus means Firecrawl excels at one thing—web data collection—rather than trying to support every possible agent use case. For teams building research agents, competitive intelligence systems, or market monitoring tools, that specialization provides significant value.

Framework Selection Criteria That Actually Matter
Choosing an agent framework based on GitHub stars or hype cycles leads to expensive rewrites. The frameworks that work in production get selected based on different criteria.
Architecture Alignment With Problem Domain
The first question isn’t “which framework is best?” It’s “does this framework’s architecture match how this problem naturally decomposes?”
Problems with clear state transitions, conditional branching, and error recovery requirements map naturally to graph-based frameworks like LangGraph. The explicit state management matches the problem structure.
Tasks requiring specialized expertise in different domains—content creation, financial analysis, customer research—work well with multi-agent frameworks like CrewAI. The role-based agent model mirrors how human teams tackle these problems.
Open-ended research tasks or code generation workflows often fit conversational frameworks like AutoGen better. The solution path emerges through dialogue rather than predetermined workflows.
Data extraction and structured output generation align with type-safe frameworks like Pydantic AI. The schema-first approach reduces hallucinations for tasks where format matters.
According to arXiv research on architecture options for foundation model-based agents, this alignment between problem domain and architectural paradigm represents the most significant factor in long-term success.
Production Requirements Beyond Basic Functionality
Experimental prototypes and production systems have fundamentally different requirements. Frameworks need to support:
- Observability: Can developers see what agents are doing, why they made decisions, and where failures occur? Production systems require detailed logging, tracing, and debugging capabilities.
- Error handling: How does the framework handle API failures, rate limits, timeouts, and invalid tool outputs? Robust error recovery separates toys from tools.
- State persistence: Can agent state survive process restarts? Do conversations persist across sessions? Production systems need durable state management.
- Cost control: Does the framework provide mechanisms to limit token usage, cap API calls, and prevent runaway execution? Uncontrolled agents get expensive fast.
- Security boundaries: How does the framework handle authentication, authorization, and sandboxing? Agents with tool access need security controls.
These requirements don’t show up in framework comparisons focused on features. But they determine whether agents survive in production.
Integration Ecosystem and Tool Support
Agents derive value from tool access. The framework needs to integrate with the specific tools and services the application requires.
Some frameworks provide extensive pre-built integrations. Others offer flexible tool definition mechanisms but require custom integration code. The trade-off between convenience and flexibility depends on whether needed integrations already exist.
According to arXiv research on agentic AI frameworks, the Model Context Protocol (MCP) is emerging as a standardization layer for tool access. Frameworks with native MCP support gain access to a growing ecosystem of compatible tools without custom integration work.
Team Skills and Learning Curve
Different frameworks require different mental models. Graph-based systems require thinking about state machines and transitions. Multi-agent systems need understanding of communication protocols and coordination patterns. Conversational frameworks need different debugging approaches.
The learning curve matters less for new projects than for teams maintaining existing systems. Switching frameworks mid-project rarely makes sense, regardless of which framework looks better. The migration cost usually exceeds the benefit.
For teams already invested in specific ecosystems—Microsoft Azure, LangChain, Pydantic data validation—frameworks that align with existing skills reduce friction significantly.
Standardization Efforts Reshaping the Landscape
The proliferation of incompatible agent frameworks creates fragmentation problems. Standards efforts aim to address this.
NIST AI Agent Standards Initiative
On February 17, 2026, the National Institute of Standards and Technology (NIST) announced the AI Agent Standards Initiative for ensuring trusted, interoperable, and secure agentic AI systems. According to the official announcement, the initiative will “ensure that the next generation of AI is widely adopted with confidence, can function securely on behalf of its users, and can interoperate smoothly across the digital ecosystem.”
This represents the first major government effort to establish standards for agent architectures, security protocols, and interoperability mechanisms. The initiative addresses concerns about agent systems operating without consistent safety frameworks or interoperability standards.
IEEE Standards for Agent Benchmarking
The IEEE P3777 standard establishes a unified framework for benchmarking AI agents, including autonomous, collaborative, and task-specific agents. It defines core performance metrics, evaluation protocols, and reporting requirements to enable transparent, reproducible, and comparable assessment of agent capacities and capabilities.
Separately, IEEE P3154.1 provides a recommended practice for a framework when applying AI agents for talent services, describing architectural frameworks and application domains with protocols for interaction and communication mechanisms.
These standardization efforts remain in active development. But they signal industry recognition that framework fragmentation creates problems for production deployment and enterprise adoption.
Understanding Agent Architectures and Design Patterns
Beyond specific frameworks, recurring architectural patterns appear across successful agent implementations. Understanding these patterns helps evaluate frameworks and design custom solutions.
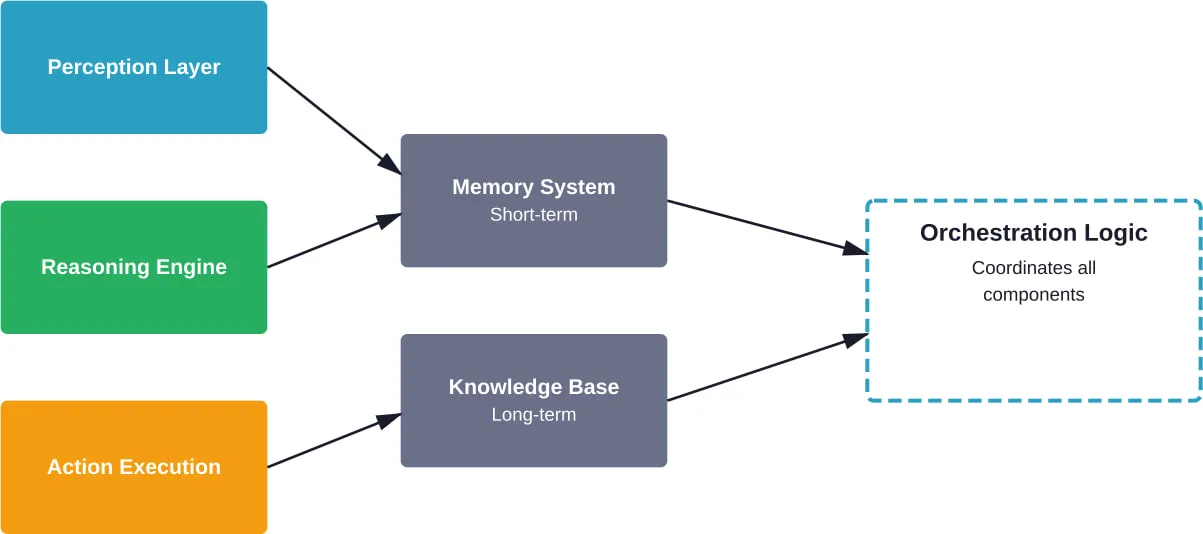
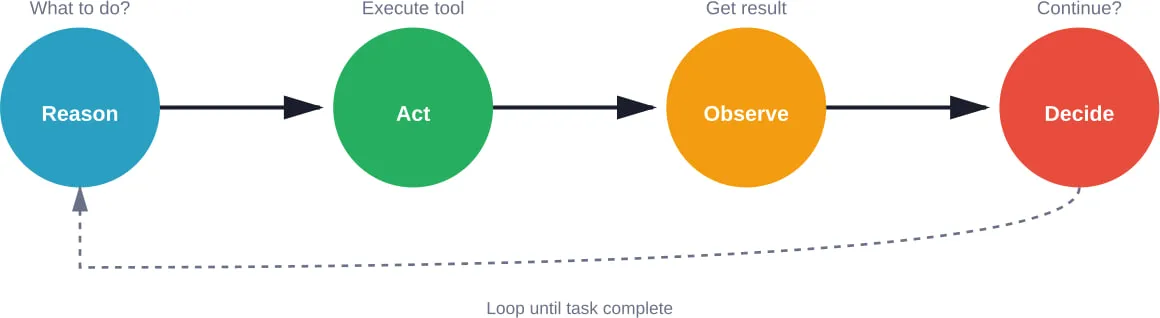
The Perception-Cognition-Action Loop
According to arXiv research distinguishing AI Agents from Agentic AI, agents fundamentally operate through perception-cognition-action cycles. Perception involves gathering information from the environment. Cognition encompasses reasoning, planning, and decision-making. Action executes decisions through tool use or communication.
Different frameworks implement this loop differently:
- Graph-based frameworks make the loop explicit through state transitions
- Conversational frameworks embed the loop in dialogue turns
- Multi-agent systems distribute the loop across specialized agents
The implementation choice affects debuggability, performance characteristics, and failure modes. Explicit loops are easier to debug but require more upfront design. Implicit loops reduce boilerplate but make control flow harder to trace.
Memory Architectures for Agent State
Agents need memory to maintain context across interactions. Memory architectures typically include:
- Working memory: Short-term context for the current task or conversation
- Episodic memory: Records of past interactions and their outcomes
- Semantic memory: General knowledge and learned facts
- Procedural memory: How to perform tasks and use tools
Production frameworks need to persist memory across sessions and handle memory limits gracefully. As conversations grow, agents must summarize, forget irrelevant details, or retrieve relevant historical context.
Some frameworks provide built-in memory management. Others leave it to developers to implement persistence and retrieval mechanisms.
Tool Use and Function Calling Patterns
Tool access transforms agents from chatbots into action-taking systems. Common patterns include:
- Direct function calling: The LLM generates structured function calls with parameters, the framework executes them, and results return to the agent. This works well for deterministic tools with clear schemas.
- Natural language tool descriptions: Tools expose natural language descriptions of capabilities. The agent decides when and how to use them based on descriptions rather than rigid schemas. More flexible but less reliable.
- Chained tool execution: Agents can use tool outputs as inputs to subsequent tools. Enables complex workflows like “search for X, read the top result, summarize it, then translate to French.”
- Parallel tool invocation: Execute multiple independent tools concurrently. Reduces latency for tasks requiring information from multiple sources.
Different frameworks support these patterns with varying levels of native support versus custom implementation.

Multi-Agent Communication Protocols
When multiple agents collaborate, communication protocols determine efficiency and reliability. According to arXiv research on agentic AI frameworks, common protocols include:
- Message passing: Agents communicate through explicit messages with defined schemas. Provides clear audit trails but requires upfront protocol design.
- Shared state: Agents read and write to shared memory or databases. Simple to implement but creates potential race conditions and conflicts.
- Event-driven: Agents publish events and subscribe to events from other agents. Decouples agents but makes overall behavior harder to predict.
- Hierarchical delegation: Manager agents assign tasks to worker agents and aggregate results. Clear control flow but creates bottlenecks at manager nodes.
The protocol choice affects debugging complexity, failure recovery, and scalability characteristics. Production systems often need multiple protocols for different interaction patterns.
Enterprise Considerations and Production Deployment
Getting agents from prototype to production involves challenges beyond framework selection. Enterprise deployment requires addressing operational, security, and governance concerns.
Cost Management and Token Economics
Agents with tool access and multi-step reasoning consume significantly more tokens than simple chatbots. A customer support agent might use 10,000+ tokens per interaction when searching knowledge bases, checking order status, and generating responses.
Production systems need:
- Token budgets per interaction to prevent runaway costs
- Caching strategies for repeated queries or common workflows
- Model selection logic that uses cheaper models for simple tasks
- Monitoring and alerting when costs exceed thresholds
Some frameworks provide built-in cost controls. Others require custom implementation of budget enforcement and model routing.
Security Boundaries and Access Control
Agents with tool access operate on behalf of users. Security failures can expose sensitive data or enable unauthorized actions.
Critical security requirements include:
- Authentication to verify agent identity and user authorization
- Authorization to limit which tools agents can access for specific users
- Input validation to prevent prompt injection attacks
- Output filtering to prevent leaking sensitive information
- Audit logging of all agent actions and tool invocations
- Sandboxing to isolate agent execution from critical systems
According to NIST’s AI Agent Standards Initiative, standardized security protocols for agents remain under development. Current frameworks implement security with varying levels of sophistication.
Observability and Debugging
When agents fail, understanding why requires detailed observability. Unlike traditional software where stack traces reveal problems, agent failures often involve semantic issues—the agent misunderstood intent, retrieved wrong information, or made poor tool choices.
Production observability requires:
- Detailed logging of agent reasoning and decision points
- Tracing of tool calls with inputs, outputs, and latencies
- Session replay capabilities to reproduce failures
- Metrics on success rates, latencies, and cost per interaction
- Integration with existing monitoring infrastructure
Frameworks differ significantly in observability support. Some provide rich debugging tools and integration with observability platforms. Others leave instrumentation to developers.
Evaluation and Quality Assurance
Traditional software testing doesn’t translate directly to agents. Deterministic unit tests can’t validate systems that use LLMs for reasoning.
According to research from the AutoChain framework, evaluation requires automated testing frameworks that assess agent ability under different user scenarios. This involves:
- Scenario-based testing with realistic user inputs
- Evaluator LLMs that assess output quality
- Regression testing to catch capability degradation
- A/B testing for comparing agent configurations
- Human evaluation for subjective quality assessment
Few frameworks provide comprehensive evaluation tooling. Most production systems require custom test harnesses.
Emerging Trends and Future Directions
The agent framework landscape continues evolving rapidly. Several trends shape where the ecosystem is heading.
Model Context Protocol Adoption
The Model Context Protocol (MCP) aims to standardize how agents access tools and external systems. Rather than each framework implementing custom tool integration, MCP provides a common protocol.
Frameworks with native MCP support gain access to a growing ecosystem of compatible tools without framework-specific integration work. This reduces one major source of framework lock-in—moving between frameworks becomes easier when tool integrations are protocol-based rather than framework-specific.
Specialized Frameworks for Vertical Domains
General-purpose frameworks like LangGraph and CrewAI work across domains. But specialized frameworks targeting specific verticals are emerging.
Firecrawl’s focus on web data collection represents this trend. Rather than supporting every possible agent use case, it optimizes for one domain and does it well.
Expect more vertical-specific frameworks for domains like customer support, data analysis, content creation, and software development. Specialized frameworks can make opinionated architectural choices that improve developer experience for their target domain.
Better Evaluation and Benchmarking
According to the IEEE P3777 standard effort, the industry recognizes the need for standardized agent benchmarking. Current evaluation approaches remain ad-hoc and inconsistent.
Improved evaluation methodologies will enable:
- Objective comparison between frameworks
- Regression detection when framework updates affect capabilities
- Performance optimization based on measurable metrics
- Compliance verification for regulated industries
Frameworks that integrate standardized evaluation tooling will likely see faster enterprise adoption.
Integration With Traditional Software Engineering
Currently, agent development often feels separate from traditional software engineering. Different tools, different testing approaches, different deployment patterns.
The trend moves toward integration. Agents as components within larger systems rather than standalone applications. This requires:
- Agent frameworks that integrate with existing CI/CD pipelines
- Testing frameworks compatible with standard test runners
- Deployment patterns that work with container orchestration platforms
- Monitoring that integrates with existing observability stacks
Frameworks that reduce the impedance mismatch between agent development and traditional software engineering will gain traction in enterprise environments.
Practical Framework Selection Strategy
Given the complexity and rapid evolution, how should teams actually choose frameworks? Here’s a practical decision process.
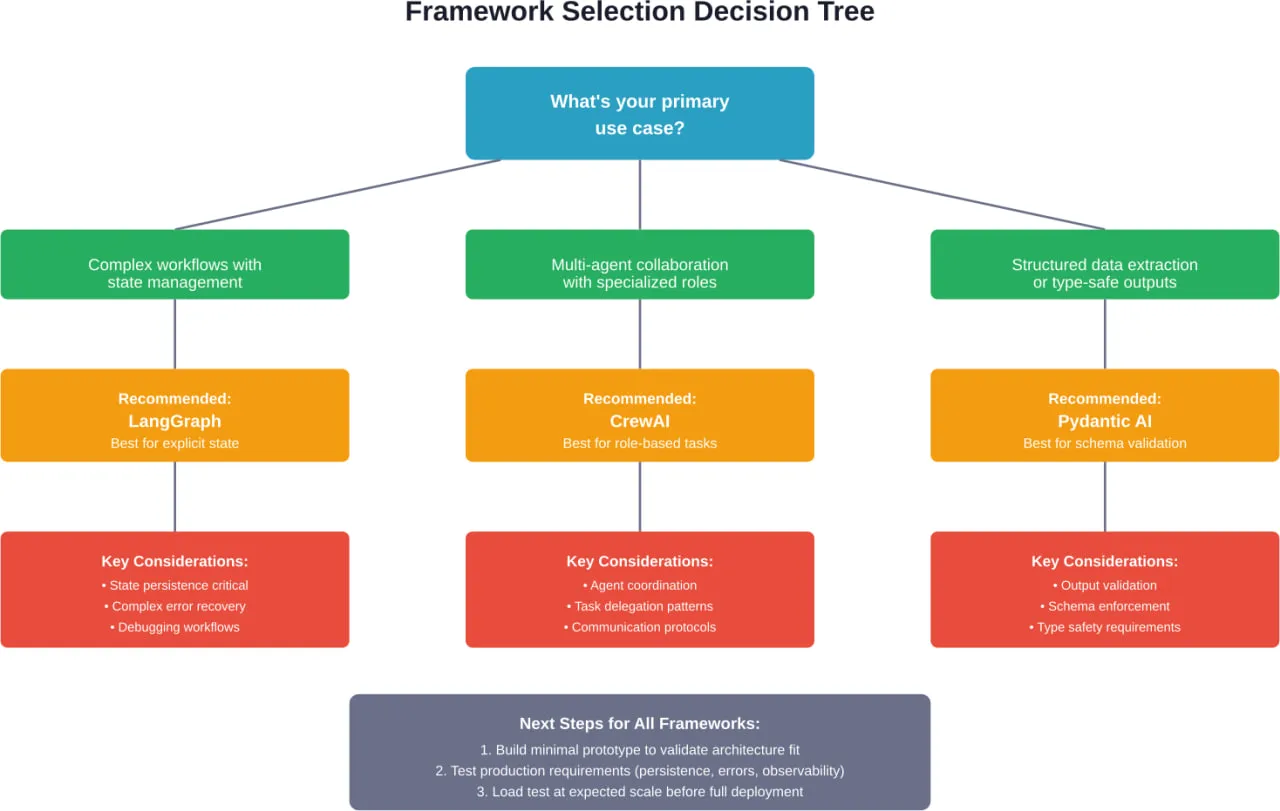
Start With Use Case Architecture Analysis
Before evaluating frameworks, map the use case to architectural patterns:
- Does the problem involve complex state management with conditional branching? Consider graph-based frameworks.
- Does it require multiple specialized agents collaborating? Consider multi-agent frameworks.
- Is it primarily conversational with tool access? Consider conversational frameworks.
- Does output structure matter as much as content? Consider type-safe frameworks.
- Is it focused on web data collection? Consider specialized frameworks.
This narrows the field significantly before evaluating specific frameworks.
Prototype With Minimal Complexity
Build the simplest possible version that tests the core architectural assumption. Don’t add features, integrations, or polish. Just validate that the framework’s architecture fits the problem.
For a customer support agent, prototype the simplest interaction: user question, knowledge base search, response generation. Skip authentication, logging, error handling, edge cases.
This reveals whether the framework’s mental model matches the problem before investing in production features.
Evaluate Production Readiness
Once architectural fit is validated, evaluate production requirements:
| Requirement | Warum es wichtig ist | How to Evaluate |
|---|
| State Persistence | Agents must survive restarts | Test session resumption after process restart |
| Error Recovery | Tool failures happen constantly | Inject API failures and timeouts, verify graceful handling |
| Observability | Debugging requires visibility | Examine logs for failed interactions, assess debuggability |
| Cost Control | Runaway token usage gets expensive | Verify budget enforcement and caching mechanisms |
| Sicherheit | Agents access sensitive systems | Review authentication, authorization, and sandboxing |
Frameworks that fail these evaluations create technical debt that becomes expensive to fix later.
Consider Ecosystem Lock-In
Some frameworks create more lock-in than others. Evaluate:
- Does the framework use standard protocols (MCP) or custom integrations?
- Can agent logic be extracted and ported to other frameworks?
- Does the framework tie to specific LLM providers or cloud platforms?
- Is the framework open source with active community development?
Lock-in isn’t necessarily bad if the framework provides sufficient value. But the decision should be deliberate rather than accidental.
Test at Expected Scale
Performance characteristics change dramatically at scale. An agent framework that works well for 10 requests per minute might fail at 100.
Load test with realistic traffic patterns before committing to production deployment. Measure:
- Latency percentiles (p50, p95, p99)
- Throughput limits and bottlenecks
- Memory usage and resource requirements
- Cost per interaction at scale
- Error rates under load
Scale testing reveals problems that don’t appear in development.

Häufige Fallstricke und wie man sie vermeidet
Teams building agents make predictable mistakes. Recognizing these patterns helps avoid expensive rewrites.
Over-Engineering Initial Implementations
The temptation to build sophisticated multi-agent systems with complex orchestration from day one kills projects. Start simple. Single agent, basic tools, minimal state management.
Add complexity only when simpler approaches fail. A single well-designed agent often outperforms three poorly coordinated specialized agents.
Ignoring Token Economics Until Production
Development environments with unlimited API budgets hide cost problems. Production environments with real traffic reveal them painfully.
Implement token budgets and monitoring from the start. Make cost visible during development, not after deployment.
Treating Agents Like Traditional Software
Traditional testing, debugging, and deployment patterns don’t translate directly. Teams that try to force agents into existing processes create friction.
Invest in agent-specific tooling for evaluation, observability, and deployment. The upfront cost pays off in reduced debugging time and faster iterations.
Choosing Frameworks Based on Hype
GitHub stars and newsletter mentions don’t predict production success. Frameworks that survive production have different characteristics than frameworks that generate hype.
Evaluate based on architectural fit and production readiness, not popularity metrics.
Underestimating Debugging Complexity
When agents fail, the failure mode often involves semantic misunderstanding rather than code bugs. Traditional debugging approaches don’t work.
Plan for significant investment in observability tooling, logging, and session replay capabilities. Debugging agents requires different tools than debugging traditional software.
Turn Your AI Agent Framework Into a Working System
Choosing a framework is the easy part. Most challenges come from integration – APIs, data flow, backend logic, and making everything run reliably in production.
A-listware provides development teams to handle that layer. The company supports backend, integrations, and infrastructure around AI systems, helping teams move from selected frameworks to stable deployments. If your framework is chosen but not implemented, contact A-listware to support integration and rollout.
Häufig gestellte Fragen
- What is the difference between an AI agent framework and a regular LLM API?
LLM APIs provide text generation capabilities—input text goes in, output text comes out. AI agent frameworks add orchestration, state management, tool integration, and multi-step reasoning on top of LLMs. They enable agents to perceive environments, make decisions, use tools, and execute workflows autonomously rather than just generating text responses.
- Which AI agent framework is best for beginners?
Pydantic AI offers the lowest learning curve for developers already familiar with Python and Pydantic. It provides type safety and structured outputs without requiring deep understanding of agent orchestration patterns. For teams new to both agents and Python, conversational frameworks like AutoGen have gentler onboarding than graph-based systems like LangGraph.
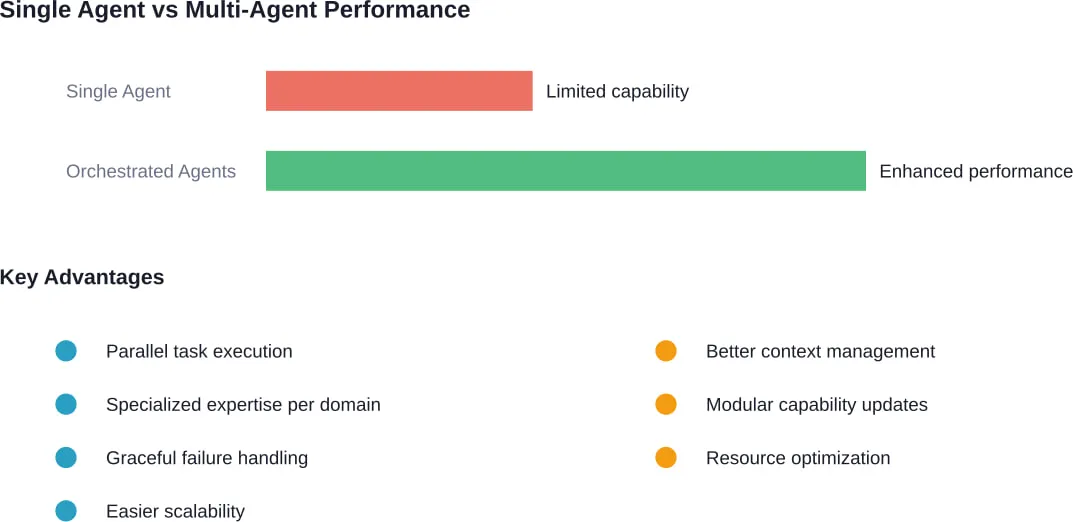
- Do I need a multi-agent framework or is a single agent sufficient?
Start with single-agent architectures unless the problem clearly requires specialized expertise in multiple domains. Multi-agent systems add coordination overhead, debugging complexity, and cost. They make sense when tasks naturally decompose into distinct roles with different knowledge requirements—like research, analysis, and reporting—but most use cases work fine with a single well-designed agent.
- How do I handle framework lock-in concerns?
Prioritize frameworks with standard protocol support like Model Context Protocol (MCP) for tool integration. Keep business logic separate from framework-specific orchestration code. Use abstraction layers for LLM provider access so switching providers doesn’t require framework changes. Evaluate whether framework benefits justify lock-in costs before committing—sometimes lock-in is acceptable if the framework provides sufficient value.
- What are the typical costs of running AI agents in production?
Costs vary dramatically based on agent complexity, token usage per interaction, traffic volume, and model selection. A simple customer support agent might use 5,000-15,000 tokens per conversation. With GPT-4 pricing, that’s $0.15-$0.45 per interaction. Complex research agents with extensive tool use can exceed 50,000 tokens per task. Production costs require careful monitoring, caching strategies, and model routing to optimize the cost-quality trade-off.
- How do NIST standards affect AI agent framework selection?
According to the AI Agent Standards Initiative announced in February 2026, NIST is developing standards for agent security, interoperability, and trustworthiness. While these standards remain in development, frameworks that align with emerging standards around authentication protocols, audit logging, and interoperability mechanisms will likely have easier enterprise adoption paths. For regulated industries, framework compliance with eventual NIST standards may become a hard requirement.
- Can I switch frameworks after building a production agent?
Technically yes, but migration costs are significant. Framework-specific orchestration patterns, state management approaches, and tool integrations don’t port directly. Expect to rewrite substantial portions of agent logic during migration. The decision to switch should be based on clear technical limitations that justify the migration cost, not minor feature differences or hype around newer frameworks.
Making the Framework Decision
No single framework dominates all use cases. LangGraph excels at complex workflows with explicit state management. CrewAI shines for multi-agent collaboration with role specialization. Microsoft Agent Framework optimizes for enterprise integration. Pydantic AI provides type safety for structured outputs. Specialized frameworks like Firecrawl optimize for specific domains.
The right choice depends on architectural alignment between problem domain and framework paradigm, production requirements around state persistence and error recovery, integration ecosystem and tool support needs, and team skills and learning curve considerations.
According to arXiv research on agentic AI frameworks, this architectural alignment represents the most significant success factor. Frameworks that match how problems naturally decompose lead to cleaner implementations, easier debugging, and more maintainable systems.
Start simple. Validate architectural fit with minimal prototypes before building production features. Test at expected scale before committing to deployment. Invest in observability and evaluation tooling from the start.
The agent framework landscape continues evolving. Standards efforts from NIST and IEEE signal industry maturation. Model Context Protocol adoption reduces framework lock-in. Specialized vertical frameworks emerge for specific domains.
But the fundamentals remain constant: understand the problem architecture, choose frameworks that match that architecture, and validate production readiness before deployment. Teams that follow this approach ship agents that survive production. Those that chase hype cycles end up rewriting.
Ready to build your first production agent? Start with the framework that matches your problem’s natural architecture. Build the simplest version that proves the concept. Then iterate based on what production teaches you.