Résumé rapide : Building AI agents requires understanding core architectural components like large language models, memory systems, tool integration, and planning mechanisms. Effective agent design emphasizes composable patterns over complex frameworks, with reliability shaped by how components interact. Successful implementations balance autonomy with transparency, enabling agents to reason, plan, and execute tasks while maintaining human oversight.
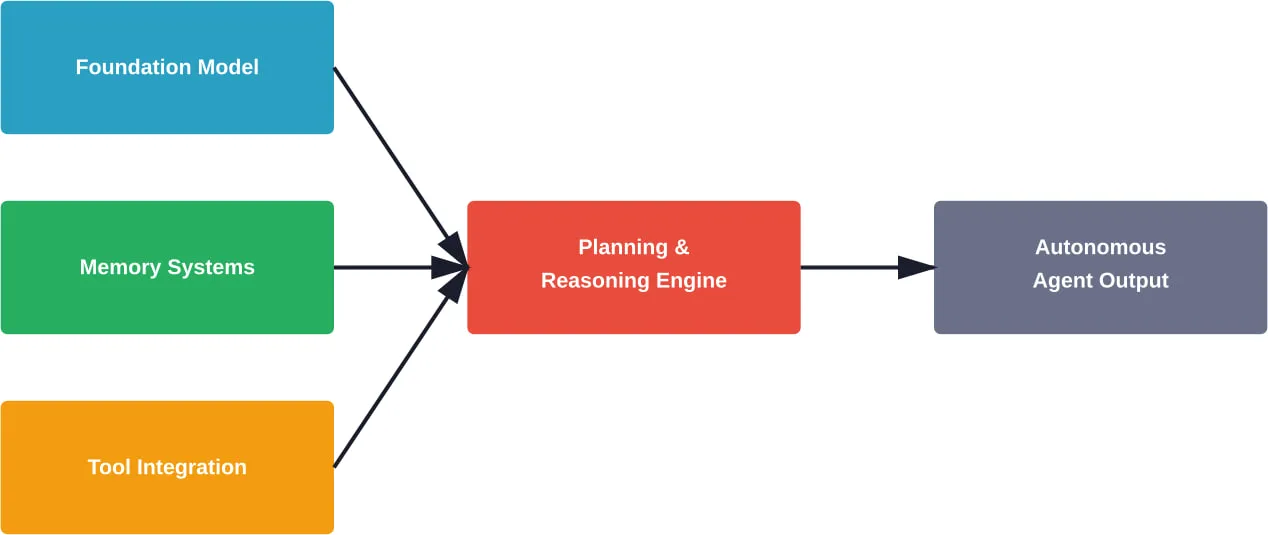
AI agents represent a shift from systems that simply respond to prompts toward autonomous systems that pursue goals independently. These aren’t just chatbots with better responses—they’re systems that combine foundation models with reasoning, planning, memory, and tool use to accomplish complex tasks.
But here’s the thing: building effective agents isn’t about deploying the most complex framework you can find. According to Anthropic, the most successful implementations across dozens of industries use simple, composable patterns rather than specialized libraries or convoluted architectures.
What Makes an AI Agent Different
An AI agent goes beyond basic language model interactions. While standard LLM applications respond to single queries, agents maintain context, make decisions, and execute multi-step workflows autonomously.
Think of it this way: when you ask a language model to “reduce customer churn,” it might provide suggestions. An agent actually analyzes data, identifies patterns, formulates strategies, and potentially implements solutions—then explains its reasoning at each step.
Research defines AI agent systems as those combining foundation models with reasoning, planning, memory, and tool use to accomplish complex tasks.
Composants architecturaux de base
Every effective agent system relies on several foundational building blocks working together.
The Foundation Model Layer
Large language models serve as the reasoning engine. The model interprets goals, generates plans, and decides which actions to take next. But the model alone isn’t the agent—it’s just one component.
Modern agent architectures support multiple models working together. One model might handle high-level coordination while specialized models tackle specific technical work.
Memory Systems
Agents need memory to maintain context across interactions. This includes short-term memory for immediate task context and long-term memory for learned patterns and historical information.
Memory architecture directly impacts agent effectiveness. Without proper memory management, agents lose track of their goals, repeat failed approaches, or ignore relevant past experiences.
Intégration des outils
Tools extend agent capabilities beyond text generation. An agent might use search engines to gather information, APIs to retrieve data, code interpreters to perform calculations, or specialized services to complete domain-specific tasks.
According to Anthropic’s engineering team, agents are only as effective as the tools provided to them. Tool design matters enormously—well-designed tools with clear documentation and appropriate response formats dramatically improve agent performance.
Reliability Through Architecture
Research from Halmstad University emphasizes that reliability isn’t something you add after building an agent—it’s determined by architectural choices from the start.
How components interact shapes whether agents behave predictably. A well-designed architecture creates natural guardrails that prevent common failure modes.
Transparency and Explainability
Users need to understand what agents are doing and why. Without transparency, an agent’s actions can seem baffling or even concerning.
Anthropic’s research on safe agent development highlights this with a clear example: without transparency design, a human asking an agent to “reduce customer churn” might be confused when the agent contacts facilities about office layouts. But with proper transparency, the agent explains its logic—it found that customers assigned to sales reps in noisy open offices had higher churn rates.
Error Handling and Recovery
Agents will encounter failures. Tools return errors, external services go down, plans don’t work as expected. Robust architectures anticipate these failures and include recovery mechanisms.
The pattern here? Don’t assume success. Build agents that verify results, detect anomalies, and adjust strategies when initial approaches fail.
Patterns That Actually Work
Real-world implementations converge on several proven patterns.
Hierarchical Multi-Agent Systems
For complex tasks, a single agent often isn’t optimal. Multi-agent systems use specialization: a main agent coordinates high-level planning while subagents handle specific technical work or information gathering.
According to Anthropic’s engineering documentation, each subagent might explore extensively using tens of thousands of tokens, but returns only a condensed, distilled summary of its work to the main agent. This approach balances depth with manageable context.
Internal evaluations show that multi-agent research systems excel especially for breadth-first queries involving multiple independent directions simultaneously.
Context Engineering Over Prompt Engineering
As agent systems mature, effective context management becomes more critical than finding perfect prompt phrasing. Context is a finite resource—agents have token limits and performance degrades with excessive context.
Strategies for effective context engineering include dynamic context pruning, hierarchical summarization, and selective information retrieval rather than loading everything upfront.
Standards and Safety Considerations
As agent systems become more capable, standardization efforts have accelerated. NIST announced the AI Agent Standards Initiative in February 2026 to ensure that agentic AI can function securely, interoperate across systems, and be adopted with confidence.
The initiative addresses critical challenges: How do agents prove they’re acting on behalf of authorized users? How can different agent systems communicate? What transparency mechanisms should be standard?
IEEE standards work emphasizes four conditions for trusted AI systems: effectiveness, competence, accountability, and transparency. These aren’t just theoretical ideals—they’re practical requirements for agent deployment in regulated industries.
Real-World Performance
Practical deployments show measurable results. According to research, Vodafone implemented an AI agent-based support system that handles over 70% of customer inquiries without human intervention, significantly reducing operational costs while improving response times.
But effectiveness varies dramatically based on implementation quality. The same research shows agents with poorly designed tools or inadequate context management often perform worse than simpler, non-agentic approaches.
Get Engineering Support for Your AI Agent Systems
Principles of building AI agents often focus on autonomy, modularity, and coordination. In practice, these ideas depend on how well the surrounding system is built – APIs, data pipelines, backend services, and infrastructure that keep everything stable over time. This is where many projects start to break down, not at the concept level, but during implementation.
A-listware supports this execution layer by providing dedicated development teams and software engineering support. The company works across the full development lifecycle – from architecture setup to integration and maintenance – and helps teams build reliable systems around AI-driven products rather than the agents themselves.
If your AI agent principles are defined but not yet working in production, this is usually the right time to bring in external engineering support. Contact Logiciel de liste A to help implement, integrate, and scale your system.
Étapes pratiques de mise en œuvre
So how do you actually start building agents?
Start simple. Don’t begin with a multi-agent orchestration system. Build a single agent that does one task well. Understand how prompting, tools, and memory interact before adding complexity.
Design tools carefully. Each tool should have clear documentation, well-defined inputs and outputs, and appropriate response formats. Anthropic recommends exposing a response format parameter that lets agents control whether tools return concise or detailed responses.
Implement evaluation from day one. Without systematic testing, it’s impossible to know whether changes improve or degrade performance. Build evaluation datasets that represent real use cases.
And iterate based on actual usage patterns. Agents reveal unexpected behaviors in production that never surface in testing.
| Phase de mise en œuvre | Key Focus | Les pièges à éviter |
|---|---|---|
| Fondation | Single agent, one clear task | Over-engineering with frameworks |
| Tool Design | Clear documentation, flexible formats | Vague tool descriptions, rigid outputs |
| Memory Integration | Relevant context retrieval | Loading excessive context |
| L'évaluation | Real-world test cases | Only testing happy paths |
| Production | Monitoring, error recovery | Assuming agents will always succeed |
Questions fréquemment posées
- What’s the difference between an AI agent and a standard LLM application?
Standard LLM applications respond to single prompts, while AI agents pursue goals autonomously across multiple steps. Agents maintain memory, plan action sequences, use tools, and make decisions about how to accomplish objectives without requiring human input for each step.
- Do I need a specialized framework to build AI agents?
No. Research and practical experience show that simple, composable patterns consistently outperform complex frameworks. Most successful implementations use straightforward combinations of language models, tool APIs, and memory systems rather than specialized agent libraries.
- How do multi-agent systems improve performance?
Multi-agent architectures allow specialization—a coordinating agent handles high-level planning while specialized subagents tackle specific technical work or research. This approach manages context more efficiently and enables parallel exploration of different solution paths.
- What are the biggest challenges in agent reliability?
The main challenges include unpredictable behavior when agents encounter unexpected situations, difficulty debugging multi-step reasoning processes, context management as tasks grow complex, and ensuring agents fail gracefully rather than producing harmful outputs when tools return errors.
- How important is tool design for agent effectiveness?
Extremely important. According to Anthropic’s engineering teams, agents are only as effective as the tools they’re given. Well-designed tools with clear documentation and appropriate response formats dramatically improve performance, while poorly designed tools cause agents to struggle even on straightforward tasks.
- What role do standards play in agent development?
Standards ensure agents can interoperate across systems, prove authorization, and function securely. NIST’s AI Agent Standards Initiative launched in 2026 focuses on creating frameworks for trust, security, and interoperability as agents become more widely deployed across industries.
- Should agents always explain their reasoning?
Yes, for most applications. Transparency about why agents take specific actions builds user trust, enables debugging, and helps identify when agents are pursuing unintended strategies. Without explainability, agent decisions can seem arbitrary or concerning, limiting practical adoption.
Moving Forward with Agent Development
Building effective AI agents requires understanding that architecture determines reliability, simplicity beats complexity, and tools matter as much as models.
The field continues evolving rapidly. Standards initiatives are establishing frameworks for safe deployment. Research clarifies which architectural patterns actually work in production. And practical experience shows that the most successful implementations start simple and add complexity only when clearly justified.
For teams ready to build agent systems, the path forward is clear: focus on composable components, design tools carefully, implement transparency from the start, and evaluate relentlessly against real-world use cases. The principles matter more than the frameworks.


