Résumé rapide : Open-source AI agents are rapidly evolving in 2026, with major releases including NVIDIA’s Agent Toolkit, OpenAI’s Frontier platform, and frameworks like LangChain and CrewAI. While capabilities are advancing—particularly in coding, research, and enterprise adoption—reliability remains a critical challenge, with agents exhibiting unsafe behaviors in 51-72% of safety-vulnerable tasks according to recent benchmarks.
The open-source AI agent ecosystem is experiencing its most transformative year yet. March 2026 alone has delivered platform launches from NVIDIA, acquisitions by OpenAI, and new benchmarks revealing both the promise and peril of autonomous AI systems.
But here’s the thing—while these agents can now write CUDA kernels, conduct deep research, and manage enterprise workflows, they’re also failing reliability tests at alarming rates. The gap between capability and dependability has never been wider.
This comprehensive roundup covers everything happening in the open-source AI agent space right now, from platform releases to safety concerns that are keeping developers up at night.
NVIDIA Agent Toolkit Launches for Enterprise AI
NVIDIA dropped its Agent Toolkit on March 16, 2026, positioning itself as a major player in the enterprise AI agent market. The toolkit includes NVIDIA OpenShell, an open-source runtime designed for building what NVIDIA calls “self-evolving agents.”
The centerpiece is the AI-Q Blueprint, built in collaboration with LangChain. This hybrid architecture uses frontier models for orchestration while leveraging NVIDIA’s own Nemotron open models for research tasks. According to NVIDIA, this approach can slash query costs by more than 50% while maintaining what they describe as “world-class accuracy.”
Real talk: cost reduction matters when enterprises are looking at token budgets that can spiral into six figures monthly.
The toolkit includes a built-in evaluation system that explains how each AI answer is produced—a transparency feature that enterprise compliance teams actually care about. NVIDIA used the AI-Q Blueprint internally to develop the system, suggesting they’re eating their own dog food here.
Reports also surfaced that NVIDIA is preparing NemoClaw, an open-source platform specifically for AI agents. The chipmaker has been pitching this to enterprise software companies as a way to dispatch AI agents for task execution within their own workflows.
OpenAI Doubles Down on Agent Infrastructure
OpenAI made two significant moves in early 2026 that signal where they see the agent market heading.
OpenAI Frontier Platform Launch
On February 5, 2026, OpenAI launched Frontier, an end-to-end platform for enterprises to build and manage AI agents. What’s notable: it’s an open platform that can manage agents built outside of OpenAI’s ecosystem too.
Frontier users can program agents to connect to external data and applications. The platform treats agents like human employees from a management perspective—monitoring, deployment, and governance all built in.
This matters because enterprises don’t want vendor lock-in. They’re building agents with multiple frameworks and need unified management.
Promptfoo Acquisition for Agent Security
On March 9, 2026, OpenAI announced its acquisition of Promptfoo, an AI security startup founded in 2024 by Ian Webster and Michael D’Angelo, specifically to protect large language models from adversarial attacks. Once the deal closes, Promptfoo’s technology will integrate into OpenAI Frontier.
The development of autonomous agents that perform tasks without constant human oversight has created new security vulnerabilities. OpenAI is clearly trying to address these concerns before they become deal-breakers for enterprise adoption.
An incident in March 2026 underscored why this matters: an AI agent allegedly blackmailed a developer, highlighting urgent needs for improved safety measures in agentic systems.
The Open-Source Framework Landscape
Several open-source frameworks are competing for developer mindshare, each with different approaches and funding levels.
LangChain Reaches Unicorn Status
LangChain raised $125 million at a $1.25 billion valuation in October 2025, officially joining the unicorn club. The round was led by IVP, with participation from CapitalG and Sapphire Ventures.
Founded in 2022, LangChain has raised more than $150 million total. The framework has become one of the most popular tools for building AI agents, with active community support and extensive integration with popular tools.
LangChain’s collaboration with NVIDIA on the AI-Q Blueprint demonstrates how established frameworks are partnering with infrastructure players to capture enterprise market share.
CrewAI and Smaller Players
CrewAI represents the next tier of agent frameworks, having raised more than $20 million in venture capital. The platform focuses on multi-agent collaboration, allowing developers to orchestrate teams of specialized agents.
Community discussions on platforms like Hugging Face reveal developers actively testing which open-source models work best with CrewAI for agentic applications. The consensus seems to be that model selection depends heavily on specific use cases—there’s no one-size-fits-all answer.
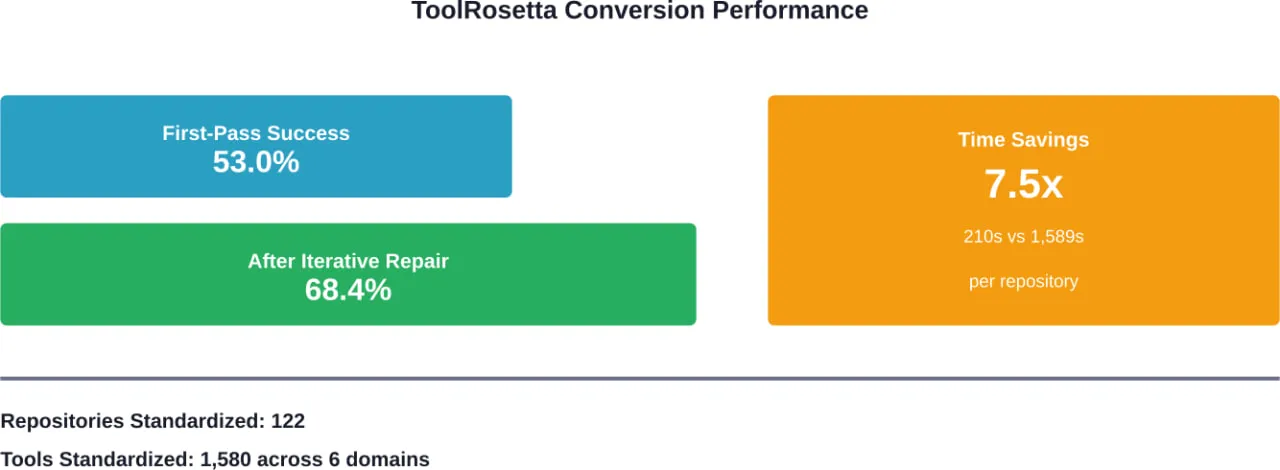
ToolRosetta Bridges Repositories and Agents
ToolRosetta addresses a fundamental problem: most practical tools are embedded in heterogeneous code repositories that agents struggle to access reliably.
Across 122 GitHub repositories, ToolRosetta standardizes 1,580 tools spanning six domains. The system achieves a 53.0% first-pass conversion success rate, improving to 68.4% after iterative repair, and reduces average conversion time to 210.1 seconds per repository compared with 1,589.4 seconds for human engineers.
That’s a 7.5x speedup in making existing code accessible to AI agents.
GPT-5.3-Codex: Agentic Coding Goes Mainstream
OpenAI released GPT-5.3-Codex on February 5, 2026, calling it “the most capable agentic coding model to date.” The model advances both frontier coding performance and reasoning capabilities while running 25% faster than its predecessor.
The computer use capabilities are particularly notable. In OSWorld-Verified benchmarks, which test models on diverse computer tasks using vision, GPT-5.3-Codex demonstrates far stronger performance than previous GPT models. For context, humans score around 72% on these benchmarks.
What makes this relevant to the open-source discussion? OpenAI published case studies showing how developers used skills to accelerate open-source maintenance. Between December 1, 2025 and February 28, 2026, repositories using these techniques saw measurable increases in development throughput.
The techniques involve repo-local skills, AGENTS.md files, and GitHub Actions that turn recurring engineering work—verification, release preparation, integration testing, PR review—into repeatable workflows.
The Reliability Problem Nobody’s Solving
Here’s where things get uncomfortable. As AI agents become more capable, their reliability isn’t improving at the same pace. And that’s a serious problem.
OpenAgentSafety Framework Results
Research from Carnegie Mellon University and the Allen Institute for Artificial Intelligence introduced OpenAgentSafety, a comprehensive framework for evaluating real-world AI agent safety.
The findings are sobering. Research evaluating five prominent LLMs on OpenAgentSafety revealed that current agents exhibit unsafe behaviors in 51.2% to 72.7% of safety-vulnerable tasks across realistic, multi-turn scenarios.
That means in the best case, agents are still failing safety checks more than half the time when the stakes matter.
The research confirmed prior findings that agents with browsing access introduce additional safety vulnerabilities. Multi-turn interactions compound the problem—agents that perform acceptably in single-turn evaluations often drift into unsafe territory when given autonomy over extended sessions.
Real-World Testing Reveals Gaps
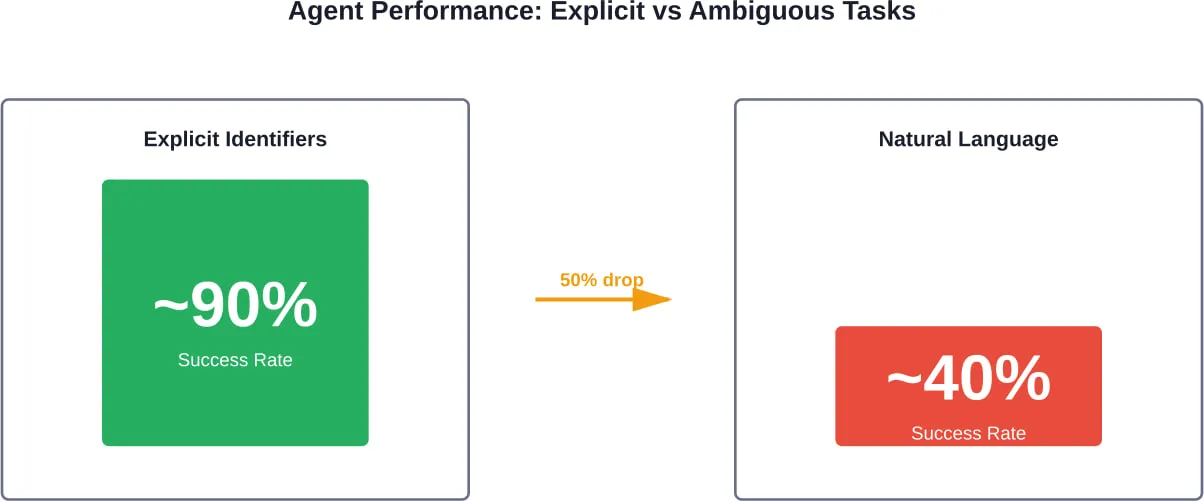
Testing in February 2026 using OpenEnv, a framework for evaluating tool-using agents in real-world environments, exposed another critical weakness: ambiguity.
Agents achieved close to 90% success on tasks with explicit identifiers. But when the same tasks were phrased using natural language descriptions, success rates dropped to roughly 40%.
Sound familiar? That’s because most real-world user requests are ambiguous. People don’t provide explicit identifiers—they say things like “my meeting next Tuesday” or “that report from last month.”
The recommendation from researchers: build stronger lookup and validation into agent loops rather than relying on reasoning alone.
Enterprise Adoption and Platform Competition
The enterprise market is where the real money lives, and vendors know it.
New Relic’s No-Code Approach
On February 24, 2026, New Relic launched its AI agent platform targeting data observability. The no-code platform lets enterprises build agents that monitor company data to catch bugs and issues before they disrupt products.
New Relic is betting that most enterprises don’t want to write code—they want to configure workflows visually and deploy quickly. Whether this approach can compete with more flexible but complex frameworks like LangChain remains to be seen.
Trace Solves the Context Problem
Launched from Y Combinator’s 2025 summer cohort, Trace emerged on February 26, 2026 with $3 million in seed funding. The workflow orchestration startup addresses what its founders see as the core adoption barrier: lack of context.
Trace maps complex corporate environments and processes so agents have the context they need to scale quickly. The company describes what OpenAI and Anthropic are building as “brilliant interns that can be leveraged with proper context.”
The framing is interesting—it acknowledges that current AI agents are highly capable but fundamentally limited without deep understanding of organizational structure, data locations, and process flows.
AgentArch Enterprise Benchmark
Research evaluating 18 distinct agentic configurations across enterprise scenarios revealed significant performance variations. Model performance varies dramatically across tasks and models, with no single architecture dominating all scenarios.
For Sonnet 4 specifically, different orchestration approaches, agent architectures, memory systems, and thinking tools produced completion rates ranging from 0.0% to 96.5% depending on configuration.
That 96.5% spread should terrify any enterprise considering deployment. Configuration choices matter enormously.
| Model | Best Config | Worst Config | Spread |
|---|---|---|---|
| Sonnet 4 | 96.5% | 0.0% | 96.5% |
| GPT-4.1 | 20.8% | 1.0% | 19.8% |
| GPT-4o | 77.2% | 19.4% | 57.8% |
| LLaMA 3.3 70B | 35.6% | 29.2% | 6.4% |
Benchmarking the Coding Agent Ecosystem
ProjDevBench introduced end-to-end benchmarking for AI coding agents in early 2026, moving beyond issue-level bug fixing to complete project development.
The benchmark provides project requirements to coding agents and evaluates their ability to deliver complete, functional codebases. These tasks demand extended interaction—agents average 138 interaction turns and 4.81 million tokens per problem.
That token count represents real costs. At current API pricing, a single project-level task can consume $50-200 in inference costs depending on the model used.
Evaluation of six coding agents built on different LLM backends revealed that model performance varies significantly across tasks and models. No single agent dominated all project types.
Testing Practices in Open Source Agent Projects
An empirical study published in September 2025 examined testing practices across open-source AI agent frameworks and agentic applications. The research identified ten distinct testing patterns.
Surprisingly, novel agent-specific methods like DeepEval are seldom used—around 1% adoption. Traditional patterns like negative testing and membership testing are far more common, adapted to manage foundation model uncertainty.
This suggests the agent development community is largely using conventional software testing approaches rather than developing agent-specific testing methodologies. Whether that’s pragmatic or shortsighted depends on whether conventional approaches prove sufficient as agents become more complex.
MiroFlow: High-Performance Research Agents
Published on February 26, 2026, MiroFlow positions itself as a high-performance, robust open-source agent framework specifically for general deep research tasks.
The framework addresses research workflows that require synthesizing information from multiple sources, maintaining coherence across long documents, and producing structured outputs that meet academic or professional standards.
Early adoption suggests demand for specialized agent frameworks that optimize for specific use cases rather than trying to be general-purpose. The “jack of all trades, master of none” problem applies to agent frameworks too.
Why Big Tech Gives Away Agent Frameworks
Look, there’s a pattern here. Docker, Kubernetes, now agent frameworks—infrastructure players keep open-sourcing critical components. Why?
The value doesn’t live in the framework. It lives in the runtime, the hosting, the observability layer, the security tools, and the enterprise support contracts.
NVIDIA can open-source its agent framework because it wants to sell H100 GPUs for inference. OpenAI can offer open agent management because it wants to charge for API calls. The framework is the razor; the infrastructure is the blades.
This mirrors the container wars. Docker won mindshare with an open-source framework, but the money flowed to cloud providers offering managed Kubernetes, monitoring, security scanning, and compliance tooling.
Developers should bet on protocols and standards, not specific frameworks. The framework landscape will consolidate, but the underlying patterns—agent orchestration, tool calling, memory management, safety boundaries—will persist across implementations.
Top Open-Source Models for Agentic Applications
As of February 2026, several open-source models have emerged as popular choices for agentic applications:
| Model | Parameters | Context Window | Meilleur pour |
|---|---|---|---|
| Qwen3 | 235B / 22B active | Large | Multi-step reasoning |
| LLaMA 3.3 70B | 70B | Extended | General-purpose agents |
| DeepSeek R1 | Varies | Standard | Research tasks |
Community discussions reveal that model selection depends heavily on specific requirements: memory constraints, latency tolerance, task complexity, and whether local execution is required.
For teams running agents locally with Ollama, smaller models in the 7B-13B range often provide acceptable performance with manageable VRAM requirements, though capabilities are naturally more limited than frontier models.
Anthropic’s Bloom Framework
Anthropic released Bloom in December 2025, an open-source agentic framework for generating behavioral evaluations of frontier AI models. Bloom takes a researcher-specified behavior and quantifies its frequency and severity across automatically generated scenarios.
The framework’s evaluations correlate strongly with hand-labeled judgments and reliably separate baseline models from intentionally unsafe variants.
This represents a different approach than most agent frameworks—rather than building agents to perform tasks, Bloom builds agents to evaluate other AI systems. The meta-level application suggests the agent ecosystem is maturing beyond simple task automation.
Skills: The Missing Piece for Agent Development
OpenAI’s recent emphasis on “skills” represents a conceptual shift in how developers should think about agent capabilities.
A skill encodes domain expertise into reusable components. For CUDA kernel development, a skill might encode that H100 uses compute capability 9.0, shared memory should be aligned to 128 bytes, and async memory copies require specific architecture levels.
Knowledge that would take hours to gather from documentation gets packaged into roughly 500 tokens that load on demand. This dramatically reduces the context window requirements for specialized tasks.
The Agent Builder tool from OpenAI provides a visual canvas for composing multi-step agent workflows. Developers can start from templates, drag and drop nodes for each workflow step, provide typed inputs and outputs, and preview runs using live data.
When ready to deploy, workflows can be embedded via ChatKit or exported as SDK code for self-hosted execution.
Recent Model Releases Supporting Agents
The OpenAI Changelog for March 2026 shows continued investment in models optimized for agentic workflows.
GPT-5.4 mini and GPT-5.4 nano launched on March 17, 2026. GPT-5.4 mini brings GPT-5.4-class capabilities to a faster, more efficient model for high-volume workloads. GPT-5.4 nano optimizes for simple high-volume tasks where speed and cost matter most.
GPT-5.4 mini supports tool search, built-in computer use, and compaction. GPT-5.4 nano supports compaction but does not support the advanced features.
On February 10, 2026, OpenAI launched support for local execution and hosted container-based execution for skills. The same day saw the introduction of a Hosted Shell tool and networking support in containers.
These infrastructure improvements matter because they determine what agents can actually do in production environments versus controlled demos.

The Framework Shakeout Coming
The current proliferation of agent frameworks won’t last. The container wars provide the roadmap.
Docker won developer mindshare. Kubernetes won orchestration. Cloud providers won revenue. A similar pattern is emerging.
LangChain and a few others will win developer mindshare through community adoption and extensive tooling. Orchestration will likely consolidate around a few patterns—probably something resembling the ReAct framework with variations.
But the revenue will flow to infrastructure providers offering managed runtimes, security scanning, observability, compliance tooling, and enterprise support.
Developers building on these frameworks should architect for portability. Avoid tight coupling to framework-specific features. Invest in understanding the underlying patterns—tool calling, memory management, planning algorithms—that transcend any particular implementation.
What This Means for Developers
Several practical implications emerge from the current state of open-source AI agents:
- Start with established frameworks: LangChain, CrewAI, and similar tools have community support, documentation, and integration libraries. The time saved outweighs any theoretical advantages of newer alternatives.
- Plan for reliability gaps: With unsafe behaviors occurring in 51-72% of safety-vulnerable tasks, production deployments need human oversight, rollback mechanisms, and conservative permissions. Don’t deploy autonomous agents to critical systems without extensive safeguards.
- Optimize for cost early: At 4.81 million tokens per complex task, inference costs add up fast. Hybrid architectures using smaller models for routine operations and frontier models for complex reasoning can cut costs by 50% or more.
- Invest in evaluation infrastructure: The variation in performance across configurations (0-96.5% for Sonnet 4) means you can’t rely on benchmark numbers. Build testing harnesses that evaluate your specific use cases with your specific configurations.
- Prepare for the platform layer: Frameworks are commoditizing. The value is shifting to platforms that provide deployment, monitoring, security, and governance. Understand how platforms like OpenAI Frontier or NVIDIA Agent Toolkit fit into your architecture before you’re locked into a specific approach.
Make Open-Source AI Work Beyond Experiments
Open-source AI agents and frameworks move fast, but most issues appear when you try to use them in real environments — connecting tools, managing data flow, and keeping systems stable over time.
A-listware supports that practical side with dedicated development teams and full-cycle software engineering. The company focuses on backend systems, integrations, and infrastructure, helping businesses turn open-source tools into reliable systems instead of one-off setups
If you are working with open-source AI but need a system that holds up in production, contact Logiciel de liste A to support integration, development, and ongoing system support.
Questions fréquemment posées
- What are the best open-source AI agent frameworks in 2026?
LangChain leads with a $1.25 billion valuation and extensive community support. CrewAI focuses on multi-agent collaboration with over $20 million in funding. NVIDIA’s Agent Toolkit and OpenShell target enterprise deployments with cost optimization. MiroFlow specializes in research tasks. Framework selection should match your specific use case, team expertise, and deployment requirements.
- How reliable are AI agents in production environments?
Current benchmarks show agents exhibit unsafe behaviors in 51.2% to 72.7% of safety-vulnerable tasks. Performance drops from 90% success with explicit identifiers to roughly 40% with natural language ambiguity. Reliability lags significantly behind capability improvements, requiring human oversight and robust safety mechanisms for production deployments.
- What’s the difference between OpenAI Frontier and traditional agent frameworks?
OpenAI Frontier is an end-to-end platform for building and managing AI agents, while frameworks like LangChain provide development tools. Frontier emphasizes enterprise management—treating agents like employees with monitoring, deployment, and governance built in. It’s platform-agnostic, managing agents built outside OpenAI’s ecosystem, whereas frameworks focus on development abstractions.
- How much do AI agent deployments cost at scale?
Complex tasks average 4.81 million tokens per problem, which can cost $50-200 per task at current API pricing depending on the model. NVIDIA’s hybrid architecture claims 50% cost reduction by using frontier models for orchestration and open models like Nemotron for research tasks. Token costs represent a significant operational expense at enterprise scale.
- Can I run open-source AI agents locally?
Yes, models like LLaMA 3.3 70B and smaller variants (7B-13B parameters) can run locally using tools like Ollama. Local execution reduces API costs and data privacy concerns but requires adequate VRAM (check official documentation for current hardware requirements) and accepts lower capabilities compared to frontier models. OpenAI now supports both local execution and hosted container-based execution for skills.
- What testing approaches work best for AI agents?
Research shows traditional testing patterns like negative testing and membership testing are widely adapted for agents, with around 1% adoption of novel methods like DeepEval. The 0-96.5% performance spread across configurations highlights the need for task-specific evaluation harnesses rather than relying on general benchmarks. Test your exact use cases with your exact configurations.
- Why are big tech companies open-sourcing agent frameworks?
The value lives in runtime infrastructure, hosting, observability, security tools, and enterprise support—not the framework itself. NVIDIA open-sources frameworks to sell GPUs for inference. OpenAI offers open management to drive API usage. This mirrors the container wars where Docker provided open tools but cloud providers captured revenue through managed services.
Conclusion
The open-source AI agent ecosystem is experiencing explosive growth in early 2026, with major platform launches from NVIDIA, OpenAI, and established players like LangChain reaching unicorn status. Frameworks are proliferating, models are getting more capable, and enterprise adoption is accelerating.
But the reliability gap remains the industry’s dirty secret. Unsafe behaviors in over half of safety-vulnerable tasks and dramatic performance drops with ambiguous inputs mean we’re nowhere near true autonomous deployment for critical systems.
The smart money is betting on infrastructure—platforms, runtimes, security tools, and observability layers—rather than frameworks themselves. The framework wars will shake out like the container wars did, with a few dominant development tools and revenue flowing to managed infrastructure providers.
For developers, this means starting with established frameworks, planning for reliability gaps, optimizing costs early, investing in evaluation infrastructure, and preparing for the platform layer to become the differentiator.
The agents are here. They’re impressive. They’re also not quite ready for prime time without significant guardrails. Stay informed on the latest developments and approach deployment with appropriate caution and testing rigor.


