Résumé rapide : La création d'un agent d'IA implique de définir son objectif et ses tâches, de sélectionner un cadre approprié (comme LangChain, AgentKit d'OpenAI ou des plateformes sans code comme n8n), de le connecter à des outils et des sources de données pertinents et de tester ses performances de manière itérative. Selon le guide pratique 2026 d'OpenAI, les agents performants utilisent des modèles simples et composables plutôt que des cadres complexes, avec une orchestration claire et des garde-fous robustes.
Les agents d'intelligence artificielle sont passés du stade de prototypes expérimentaux à celui de systèmes de production transformant le mode de fonctionnement des organisations. Mais voilà, la plupart des équipes qui abordent le développement d'agents pour la première fois ne savent pas par où commencer.
Le paysage a changé radicalement à la fin de l'année 2024 et au début de l'année 2025. Selon l'équipe d'ingénieurs d'Anthropic, les implémentations d'agents les plus réussies n'utilisent pas de cadres complexes ou de bibliothèques spécialisées. Au contraire, elles sont construites avec des modèles simples et composables qui privilégient le contrôle et la fiabilité à l'automatisation.
Ce guide présente le processus pratique de création d'un agent d'IA, du concept initial au déploiement, sur la base des cadres publiés par OpenAI, Anthropic et LangChain en 2025-2026.
Comprendre ce que sont les agents d'intelligence artificielle
Avant de plonger dans les étapes de création, il est important de clarifier les définitions. L'OpenAI définit les agents comme des “systèmes qui accomplissent intelligemment des tâches, qu'il s'agisse d'objectifs simples ou de flux de travail complexes et ouverts”.”
La principale distinction ? Les agents se distinguent des applications LLM standard par leur capacité à prendre des décisions séquentielles, à utiliser des outils et à maintenir le contexte à travers plusieurs étapes.
Selon une étude publiée sur arXiv en janvier 2026 (article 2601.16648), les agents autonomes efficaces nécessitent un cadre cognitif inspiré des processus décisionnels humains. Ce cadre comprend la perception, le raisonnement, la planification et l'exécution d'actions en tant que composantes distinctes.
Agents ou flux de travail : Quelle est la place de votre cas d'utilisation ?
La documentation sur le cadre de LangChain d'avril 2025 présente un spectre utile. À une extrémité se trouvent des flux de travail déterministes où chaque étape est prédéfinie. À l'autre extrémité, on trouve des agents entièrement autonomes qui prennent des décisions indépendantes à chaque étape.
La plupart des systèmes de production se situent quelque part entre les deux. En réalité, les agents entièrement autonomes semblent passionnants, mais ils posent des problèmes de fiabilité que de nombreuses équipes ne sont pas prêtes à gérer.
| Caractéristique | Flux de travail | Agent |
|---|---|---|
| Prise de décision | Séquence prédéterminée | Dynamique, axé sur le contexte |
| Prévisibilité | Haut | Variable |
| Utilisation des outils | Points d'intégration fixes | Sélection des outils d'exécution |
| Gestion des erreurs | Chemins explicites définis | Des stratégies de relance sont nécessaires |
| Meilleur pour | Processus définis | Tâches ouvertes |
Étape 1 : Définir l'objectif et le champ d'application de l'agent
Le guide d'OpenAI de mars 2026 insiste sur la nécessité de commencer par une définition claire et réaliste de la tâche. Il ne s'agit pas d'une vision ambitieuse de ce que les agents pourraient faire un jour, mais de déterminer quel problème spécifique doit être résolu dès maintenant.
Selon le blog de LangChain (publié le 10 juillet 2025), les équipes devraient d'abord construire un MVP. L'équipe a illustré son propos en donnant l'exemple d'un agent de messagerie. Elle n'a pas commencé par “automatiser tout le courrier électronique”. Ils ont défini : “Rédiger des réponses aux demandes de renseignements des clients sur l'état de leur commande à l'aide de notre base de données d'expédition”.”
Questions à se poser avant de construire
Quelle tâche spécifique l'agent doit-il accomplir ? Qui sont les utilisateurs finaux ? À quelles sources de données doit-il accéder ? Quelles actions peut-il entreprendre ? Quels sont les modes de défaillance et quel est leur degré de criticité ?
Selon une étude de MIT Press (publiée le 30 janvier 2026), les entreprises qui mettent en œuvre des architectures centrées sur les agents enregistrent des gains de productivité de 2 à 10 fois. Celles qui obtiennent des gains de productivité importants grâce aux agents commencent par des cas d'utilisation étroits et bien définis. Une entreprise industrielle internationale a réduit de 92% le temps nécessaire à l'établissement des rapports d'audit en affectant un agent à des flux de travail spécifiques d'analyse de documents.
La réponse courte ? Commencer modestement. Développez vos activités une fois que les fondations se sont avérées fiables.
Étape 2 : Choisir l'approche de développement
Il existe trois voies principales pour construire des agents en 2026 : les cadres basés sur le code, les plateformes à faible code et les outils sans code.
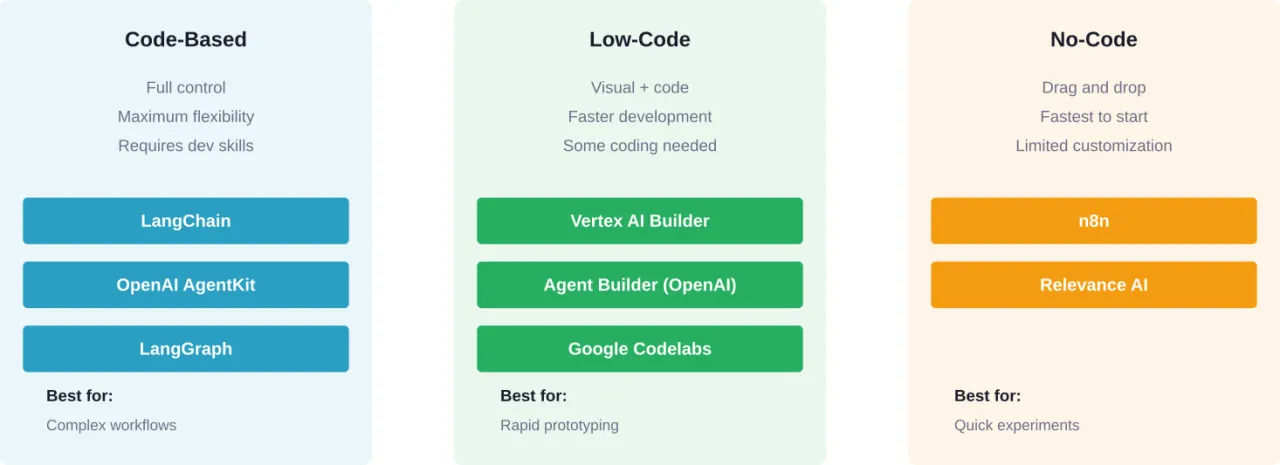
Cadres basés sur le code : Un contrôle maximal
LangChain reste le cadre open-source le plus largement adopté pour le développement d'agents. Selon la documentation de LangChain, le cadre fournit des architectures d'agents préconstruites avec plus de 1000 intégrations pour les modèles et les outils.
La fonction create_agent du cadre met en œuvre un modèle ReAct (Reasoning + Acting) éprouvé sur le runtime durable de LangGraph. Ce modèle permet aux agents de raisonner sur ce qu'il faut faire, d'agir, d'observer le résultat et de répéter.
L'AgentKit d'OpenAI, annoncé dans la documentation de l'API, offre une boîte à outils modulaire pour la construction, le déploiement et l'optimisation des agents. Il comprend Agent Builder (un canevas visuel) et ChatKit pour intégrer des flux de travail.
Plateformes sans code : La rapidité au détriment de la flexibilité
Pour les équipes qui ne disposent pas de ressources d'ingénierie dédiées, les plateformes sans code offrent un chemin plus rapide vers les agents de base. n8n.io permet la création d'agents par le biais de constructeurs de flux de travail visuels, avec un niveau gratuit disponible et des plans payants à partir de $20/mois.
Mais attendez. Les outils sans code excellent dans les flux d'automatisation simples. Ils ont du mal à gérer les arbres de décision complexes, les intégrations personnalisées et la gestion sophistiquée des erreurs.
Étape 3 : Conception de l'architecture de l'agent
L'architecture d'un agent se compose de plusieurs éléments fondamentaux qui fonctionnent ensemble. La compréhension de ces éléments constitutifs est utile quel que soit le cadre choisi.
Les éléments essentiels dont tout agent a besoin
Les voici :
- Le cerveau du LLM : Le modèle linguistique traite le raisonnement et la prise de décision. Le choix du modèle est important : le guide d'OpenAI met l'accent sur l'adéquation entre les capacités du modèle et la complexité de la tâche.
- Accès aux outils : Mécanismes permettant à l'agent d'effectuer des actions au-delà de la génération de texte. Il peut s'agir d'API, de bases de données, de moteurs de recherche ou de fonctions personnalisées.
- Systèmes de mémoire : Conservation du contexte à travers les tours de conversation ou les étapes du flux de travail. Cela peut être simple (historique des conversations) ou complexe (bases de données vectorielles pour la recherche sémantique).
- Logique d'orchestration : Le flux de contrôle qui détermine comment l'agent sélectionne et exécute les outils. Les recherches menées par Anthropic en décembre 2024 montrent que les implémentations réussies favorisent l'orchestration explicite plutôt que l'autonomie totale.
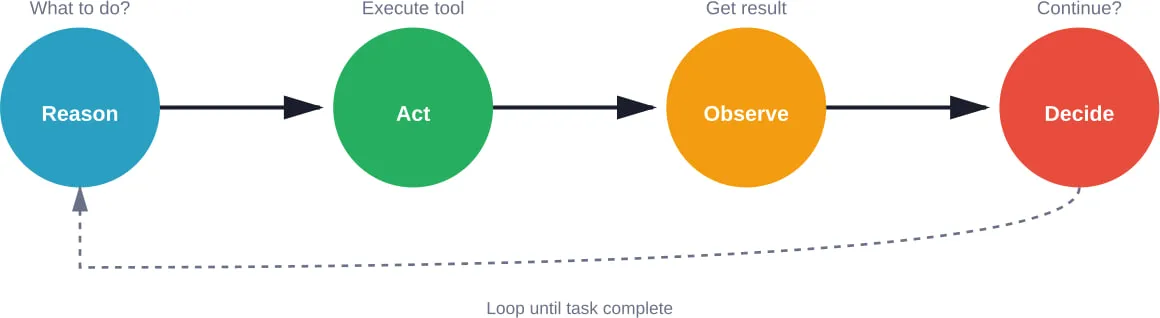
Le modèle ReAct en pratique
Le modèle ReAct structure le comportement de l'agent en phases claires. Tout d'abord, l'agent reçoit une tâche. Deuxièmement, il réfléchit à l'action à entreprendre. Troisièmement, il exécute cette action. Quatrièmement, il observe le résultat. Enfin, il décide de continuer ou de renvoyer une réponse finale.
Cette boucle se poursuit jusqu'à ce que l'agent détermine que la tâche est terminée ou qu'il atteigne une limite maximale d'itération.
Étape 4 : Connecter les outils et les sources de données
Un agent sans outils ne peut que générer du texte. Les outils transforment les agents en systèmes qui agissent dans le monde.
Selon le guide pratique de l'OpenAI, la conception des outils a un impact significatif sur la fiabilité des agents. Les outils bien conçus ont des descriptions claires, des définitions de paramètres explicites et des messages d'erreur prévisibles.
Types d'outils utilisés par les agents
Les intégrations API relient les agents à des services externes - processeurs de paiement, systèmes de gestion de la relation client, plateformes de communication. Les requêtes de base de données permettent aux agents de récupérer ou de mettre à jour des informations structurées. Les fonctions de recherche permettent aux agents de trouver des informations pertinentes dans de vastes ensembles de documents ou sur le web.
Les environnements d'exécution de code permettent aux agents d'exécuter des scripts Python, d'effectuer des calculs ou de traiter des données. L'appel de fonctions transforme toute logique personnalisée en un outil accessible aux agents.
Meilleures pratiques en matière de conception d'outils
Limitez le champ d'application des outils. Au lieu d'un seul outil “database_query”, créez des outils spécifiques tels que “get_customer_by_id” ou “list_recent_orders”. Cela réduit l'ambiguïté et améliore la fiabilité.
Rédiger des descriptions détaillées des outils. L'agent s'appuie entièrement sur ces descriptions pour comprendre quand et comment utiliser chaque outil. Inclure des exemples de cas d'utilisation appropriés.
Traiter les erreurs avec élégance. Les outils doivent renvoyer des messages d'erreur structurés que l'agent peut comprendre et dont il peut éventuellement se remettre. Selon le guide d'ingénierie d'Anthropic, une gestion robuste des erreurs distingue les agents de production des prototypes.
Étape 5 : Mise en œuvre du contexte et de la mémoire
Les agents ont besoin de mémoire pour maintenir leur cohérence lors d'interactions à plusieurs tours. La stratégie de mémoire dépend du cas d'utilisation.
La mémoire à court terme stocke l'historique des conversations, généralement transmis au LLM dans le cadre de chaque invite. Cette méthode fonctionne pour les interactions brèves, mais devient coûteuse et peu pratique pour les sessions longues.
La mémoire à long terme nécessite un stockage externe - souvent des bases de données vectorielles pour la récupération sémantique. Selon le tutoriel sur les agents RAG de LangChain, ce modèle combine les capacités d'un agent avec la génération augmentée par la recherche.
L'agent peut interroger une base de connaissances, récupérer les informations pertinentes et les intégrer dans son raisonnement. Cette approche s'adapte à de grandes collections de documents tout en maintenant l'utilisation de jetons à un niveau raisonnable.
Étape 6 : Mise en place de garde-corps et de mesures de sécurité
Les systèmes autonomes ont besoin de contraintes. Le guide d'OpenAI de mars 2026 souligne que les garde-fous sont essentiels et non optionnels.
| Type de garde-corps | Objectif | Mise en œuvre |
|---|---|---|
| Validation des entrées | Prévenir les invites malveillantes | Filtrage du contenu, détection des injections rapides |
| Filtrage de la sortie | Attraper les réponses inappropriées | Détection des IPI, vérification de la politique de contenu |
| Limitation du taux | Contrôle des coûts et des abus | Quotas de demandes, application du délai d'attente |
| Approbation de l'action | Supervision humaine des actions critiques | Processus d'approbation, seuils de confiance |
| Contrôle | Suivre le comportement et les performances | Journalisation, alertes, pistes d'audit |
Une étude de l'Institute for Creative Technologies de l'USC, publiée en juillet 2025, décrit les meilleures pratiques pour les agents conversationnels d'IA dans le domaine des soins de santé - des principes qui s'appliquent de manière générale. Il s'agit notamment de mécanismes de consentement explicite, d'une communication transparente des capacités et d'une surveillance continue de la sécurité.
Le cadre de gestion des risques de l'IA du NIST (AI RMF 1.0), publié en janvier 2023, fournit des orientations supplémentaires pour le développement d'une IA digne de confiance. Bien qu'ils ne soient pas spécifiques à un agent, ses principes concernant la transparence, la responsabilité et les tests restent pertinents.
Étape 7 : Test et itération
Le développement d'un agent est par nature itératif. Selon le blog de LangChain (publié le 10 juillet 2025), les équipes doivent d'abord construire un MVP, puis tester et améliorer systématiquement.
Création de cas de test
Commencez par des exemples réalistes de la tâche que l'agent doit accomplir. Incluez des cas limites, des conditions d'erreur et des entrées ambiguës. Selon l'OpenAI, les tests de qualité et de sécurité requièrent divers scénarios au-delà du chemin le plus heureux.
Suivez les indicateurs clés : taux d'achèvement des tâches, nombre moyen d'étapes, schémas d'utilisation des outils, fréquence des erreurs et temps de latence des réponses. Ces indicateurs révèlent si l'agent travaille réellement ou s'il a de la chance.
Problèmes courants et solutions
Les agents ont souvent du mal à sélectionner les outils - ils choisissent le mauvais outil ou ne savent pas quand un outil est nécessaire. Cela est généralement dû à une mauvaise description des outils ou à un manque d'exemples dans les messages-guides.
Les boucles infinies se produisent lorsque les agents ne peuvent pas déterminer l'achèvement d'une tâche. La fixation de limites maximales d'itération permet d'éviter l'emballement de l'exécution. De meilleures indications sur les critères de réussite permettent aux agents de savoir quand s'arrêter.
La surcharge contextuelle se produit lorsque les agents reçoivent trop d'informations et se déconcentrent. L'amélioration de la pertinence de la recherche ou la mise en œuvre d'une transmission plus sélective du contexte permettent de remédier à ce problème.
Étape 8 : Déploiement et surveillance
Le passage du prototype à la production nécessite des décisions en matière d'infrastructure. Où l'agent sera-t-il exécuté ? Comment les utilisateurs y accéderont-ils ? Quels sont les systèmes de surveillance et de journalisation nécessaires ?
L'Agent Builder d'OpenAI permet d'intégrer des flux de travail via ChatKit ou de télécharger le code SDK pour l'auto-hébergement. LangSmith de LangChain permet de tracer et de surveiller les agents en production. Selon leur documentation, la définition de variables d'environnement permet d'enregistrer les traces à des fins de débogage et d'optimisation.
Considérations relatives à la production
La latence est importante pour les agents en contact avec les utilisateurs. Les flux de travail des agents en plusieurs étapes peuvent prendre des secondes ou des minutes en fonction de leur complexité. Définir clairement les attentes des utilisateurs en matière de temps de réponse permet d'éviter les frustrations.
La gestion des coûts devient critique à grande échelle. Chaque invocation d'agent implique de multiples appels LLM, des exécutions d'outils et des récupérations de données. La surveillance des schémas d'utilisation et la mise en œuvre de stratégies de mise en cache permettent de contrôler les dépenses.
Les versions et les mises à jour nécessitent une planification. Les agents intègrent plusieurs composants - modèles, outils, invites et logique d'orchestration. Toute modification apportée à l'un de ces composants peut affecter le comportement de l'agent. Le maintien du contrôle des versions et le test des mises à jour avant le déploiement permettent d'éviter les surprises au niveau de la production.
Construire un système solide derrière votre agent d'intelligence artificielle
La création d'un agent d'IA ne se limite pas au modèle. Elle dépend de systèmes dorsaux, d'API, d'intégrations et d'infrastructures qui peuvent fonctionner de manière fiable en production. C'est là qu'intervient A-listware. L'entreprise se concentre sur le développement de logiciels personnalisés et sur des équipes d'ingénieurs dédiées, couvrant l'architecture, le développement, les tests, le déploiement et l'assistance continue. C'est la partie qui transforme un concept d'IA en quelque chose qui fonctionne réellement à l'intérieur d'un produit.
Si vous construisez un agent d'IA, la majeure partie du travail se situe autour de lui - connecter les services, gérer les flux de données et maintenir le tout stable dans le temps. A-listware prend en charge l'intégralité du cycle de développement, de sorte que vous n'avez pas à répartir les responsabilités entre différents fournisseurs. Partagez votre configuration, définissez ce qui doit être construit et découvrez comment Logiciel de liste A peut soutenir le système autour de votre agent d'intelligence artificielle.
Modèles avancés : Systèmes multi-agents
Les agents individuels gèrent des tâches discrètes. Mais les flux de travail complexes bénéficient souvent de la collaboration de plusieurs agents spécialisés.
Selon le cadre Agent² publié sur arXiv, l'approche agent-génère-agent utilise les LLM pour concevoir de manière autonome des agents d'apprentissage par renforcement. Cette automatisation au niveau méta est prometteuse pour réduire l'expertise requise pour le développement d'agents.
Les modèles multi-agents comprennent des structures hiérarchiques dans lesquelles un agent coordinateur délègue des tâches à des agents spécialisés, et la collaboration entre pairs dans laquelle des agents dotés de capacités différentes travaillent ensemble sur des objectifs communs.
Le guide pratique de l'OpenAI couvre l'orchestration multi-agents, notant que les frais généraux de coordination augmentent la complexité du système. Les équipes doivent s'assurer que les agents multiples apportent réellement une valeur ajoutée par rapport à un seul agent bien conçu.
Applications et résultats dans le monde réel
Selon une étude de MIT Press (publiée le 30 janvier 2026), les entreprises qui mettent en œuvre des architectures centrées sur les agents enregistrent des gains de productivité de 2 à 10 fois, mais uniquement lorsqu'elles vont au-delà de l'adoption superficielle de l'IA.
L'enquête mondiale de McKinsey sur l'IA montre que si 78% des entreprises déclarent utiliser l'IA générative dans au moins une fonction, plus de 80% ne signalent aucune contribution matérielle aux bénéfices. La différence réside dans la profondeur de la mise en œuvre.
Une organisation de vente B2B citée dans l'étude Harvard Data Science Review a automatisé la prospection et l'approche initiale à l'aide d'agents spécialisés, libérant ainsi les équipes de vente pour qu'elles se concentrent sur l'établissement de relations et la conclusion d'affaires.
Les erreurs courantes à éviter
Commencer avec des agents totalement autonomes avant de maîtriser les flux de travail structurés conduit à des systèmes peu fiables. Les conseils d'Anthropic mettent l'accent sur la construction de flux de travail déterministes d'abord, puis sur l'introduction progressive de la prise de décision par des agents là où elle apporte une valeur ajoutée.
Négliger la gestion des erreurs crée des systèmes fragiles qui tombent en panne de manière imprévisible. Les agents de production doivent disposer de mécanismes complets de détection, d'enregistrement et de récupération des erreurs.
La sur-ingénierie avec des cadres complexes alors que des modèles simples suffiraient fait perdre du temps au développement. Selon Anthropic, les équipes les plus performantes utilisent des implémentations simples avec un flux de contrôle clair.
Des tests insuffisants avant le déploiement se traduisent par des expériences médiocres pour les utilisateurs et des comportements potentiellement dangereux. Des tests systématiques dans divers scénarios permettent d'identifier les problèmes avant que les utilisateurs ne les rencontrent.
Questions fréquemment posées
- Quels sont les langages de programmation les plus adaptés à la construction d'agents d'intelligence artificielle ?
Python domine le développement d'agents en raison du support étendu de la bibliothèque. LangChain, le SDK d'OpenAI et la plupart des frameworks d'agents fournissent des API en Python. JavaScript/TypeScript fonctionnent pour les agents basés sur le web, LangChain offrant des bibliothèques JavaScript. Pour les équipes qui n'ont pas d'expertise en matière de codage, les plateformes sans code comme n8n éliminent totalement les exigences en matière de langage.
- Quel est le coût de fonctionnement d'un agent d'IA en production ?
Les coûts varient considérablement en fonction des schémas d'utilisation, de la sélection du modèle et de l'architecture. Chaque invocation d'agent implique plusieurs appels à l'API LLM - les coûts évoluent en fonction du volume de requêtes et de l'utilisation des jetons. Les cadres de développement tels que LangChain sont gratuits et libres, tandis que l'hébergement et l'utilisation de l'API génèrent des dépenses permanentes. Les plateformes sans code facturent généralement des frais d'abonnement mensuels. Pour obtenir des estimations précises, vérifiez les prix actuels du fournisseur LLM et de la plateforme envisagée.
- Les agents d'intelligence artificielle peuvent-ils travailler hors ligne ou ont-ils besoin d'une connexion internet ?
La plupart des agents ont besoin d'une connexion internet pour accéder aux LLM basés sur le cloud via des API. Toutefois, les agents peuvent être construits avec des modèles open-source exécutés localement pour un fonctionnement hors ligne, bien que cela nécessite des ressources informatiques et une configuration technique importantes. Les approches hybrides utilisent le traitement local pour certaines tâches et se connectent à des services en nuage pour d'autres.
- Quelle est la différence entre un agent d'IA et un chatbot ?
Les chatbots gèrent principalement la conversation, en répondant aux messages des utilisateurs sur la base de scripts prédéfinis ou de la génération de modèles de langage. Les agents d'IA vont au-delà de la conversation et prennent des mesures : ils interrogent des bases de données, appellent des API, exécutent des flux de travail en plusieurs étapes et prennent des décisions sur la base d'observations. Les agents utilisent des outils et maintiennent un comportement orienté vers un objectif à travers plusieurs étapes. De nombreuses interfaces conversationnelles sont en fait des agents, même si les utilisateurs interagissent par le biais d'un chat.
- Combien de temps faut-il pour créer un agent d'intelligence artificielle fonctionnel ?
Le délai dépend de la complexité et de l'approche. Des agents d'automatisation simples utilisant des plateformes sans code peuvent être créés en quelques heures. Le développement et les tests d'agents basés sur du code et gérant des tâches spécifiques peuvent prendre des jours ou des semaines. Les systèmes multi-agents complexes avec des intégrations étendues nécessitent des mois. Selon le guide de l'OpenAI, les équipes devraient d'abord se concentrer sur des MVP étroits - des fonctionnalités de base mises en œuvre rapidement, puis développées en fonction des performances réelles.
- Quels sont les principaux risques liés au déploiement d'agents d'IA ?
Les agents peuvent entreprendre des actions involontaires si les messages-guides sont ambigus ou si les descriptions des outils ne sont pas claires. Des vulnérabilités en matière de sécurité apparaissent si les agents accèdent à des données sensibles sans contrôle adéquat. Des dépassements de coûts se produisent lorsque les agents effectuent des appels API excessifs ou entrent dans des boucles. Des problèmes de fiabilité se posent en raison d'une gestion inadéquate des erreurs. La confiance des utilisateurs s'érode si les agents se comportent de manière imprévisible. Selon le cadre de gestion des risques liés à l'IA du NIST, l'évaluation systématique des risques et les stratégies d'atténuation répondent à ces préoccupations.
- Ai-je besoin d'une expertise en apprentissage automatique pour créer un agent d'IA ?
Pas nécessairement. Les frameworks modernes font abstraction de la complexité de la ML - les développeurs travaillent avec des API de haut niveau plutôt que de former des modèles à partir de zéro. La compréhension de l'ingénierie rapide, de l'intégration des API et de la conception des systèmes est plus importante que les connaissances approfondies en ML. Les plateformes sans code éliminent même ces exigences pour les cas d'utilisation simples. Cependant, l'optimisation des performances des agents, le débogage de comportements complexes et la mise en œuvre de capacités personnalisées bénéficient de la profondeur technique.
Démarrer avec votre premier agent
Le chemin qui mène du concept à l'agent opérationnel devient plus clair grâce à la structure. Commencez par définir une tâche spécifique que l'agent doit accomplir. Choisissez un cadre correspondant aux capacités techniques - LangChain pour les développeurs, plateformes sans code pour les équipes non techniques ou approches hybrides pour le prototypage rapide.
Construire la version la plus simple qui puisse fonctionner. Un seul outil, un contexte minimal, un flux de contrôle explicite. Testez-la minutieusement dans le cadre de scénarios réalistes. Ce n'est qu'une fois que cette base s'est avérée fiable que l'on peut commencer à développer des capacités supplémentaires.
D'après les recherches publiées par de multiples sources faisant autorité en 2025-2026, cette approche progressive distingue les déploiements d'agents réussis des expériences abandonnées.
L'écosystème des agents continue d'évoluer rapidement. De nouveaux cadres apparaissent, les outils existants ajoutent des capacités et les meilleures pratiques se consolident grâce à des déploiements dans le monde réel. Mais les principes fondamentaux - définition claire de l'objectif, conception appropriée de l'outil, tests systématiques et garde-fous robustes - restent constants.
Les organisations qui tirent parti de la valeur des agents ont des points communs : commencer par un périmètre restreint, donner la priorité à la fiabilité plutôt qu'à l'autonomie et traiter le développement des agents comme une ingénierie itérative plutôt que comme une mise en œuvre ponctuelle.
Prêt à construire ? Les cadres, la documentation et les ressources communautaires existent aujourd'hui. Le principal obstacle n'est pas la capacité technique, mais le fait de faire le premier pas concret de l'exploration à la mise en œuvre.


