Résumé rapide : L'analyse des performances des agents d'IA nécessite le suivi de mesures dans quatre domaines clés : les performances techniques (achèvement des tâches, latence, précision), l'impact commercial (retour sur investissement, réduction des coûts opérationnels), la sécurité et la conformité (taux d'hallucination, incidents de sécurité) et l'expérience des utilisateurs (taux de satisfaction, taux d'adoption). Selon des recherches menées à Stanford et au MIT, les agents bien implémentés atteignent un taux d'achèvement de 85-95% pour les tâches structurées, bien que l'évaluation reste difficile, 95% des investissements en IA ne produisant pas de retour mesurable en raison de cadres de mesure inadéquats.
La création d'agents d'IA est devenue remarquablement rapide. Certaines équipes déploient désormais des agents fonctionnels en quelques semaines. Mais il y a un hic : la rapidité ne signifie rien si l'agent n'apporte pas de valeur mesurable.
Le véritable défi n'est plus de créer des agents. Il s'agit de prouver qu'ils sont efficaces.
Selon des recherches citées dans des analyses sectorielles, les organisations ont souvent du mal à démontrer que les investissements dans l'IA ont des retombées mesurables. Ce n'est pas parce que la technologie échoue, mais parce que les organisations ne sont pas en mesure de déterminer à quoi ressemble réellement le succès. La recherche indique que l'évaluation de l'IA met souvent trop l'accent sur les paramètres techniques par rapport aux facteurs économiques et centrés sur l'utilisateur.
Ce déséquilibre crée de graves problèmes. Les équipes techniques se félicitent d'une faible latence alors que les dirigeants d'entreprise se demandent où est passé le retour sur investissement. Les équipes chargées de la sécurité signalent les cas limites qui ne sont jamais traités en priorité. Les utilisateurs abandonnent les agents qui “fonctionnent” techniquement, mais qui sont maladroits.
Pourquoi les mesures traditionnelles ne fonctionnent pas pour les agents d'IA
Les agents d'IA ne sont pas des logiciels traditionnels. Ils fonctionnent avec une variabilité inhérente - la même entrée peut produire des sorties différentes. Ils prennent des décisions autonomes, appellent des outils et gèrent des flux de travail à plusieurs étapes.
Cela introduit des modes de défaillance que le suivi traditionnel des erreurs ne peut pas détecter. Appels d'outils hallucinés. Boucles infinies. Actions inappropriées qui sont techniquement réussies mais contextuellement erronées.
Le contrôle standard du temps de fonctionnement ne permet pas de détecter un agent qui répond rapidement avec des informations totalement erronées. Les taux d'erreur ne révèlent pas un agent qui accomplit des tâches mais prend cinq fois plus de temps qu'un humain ne le ferait.
Les quatre dimensions fondamentales de la performance des agents d'IA
Une évaluation efficace des agents nécessite un cadre équilibré. Selon les recherches menées par le Digital Economy Lab de Stanford et le National Institute of Standards and Technology (NIST), qui a récemment annoncé la mise en place d'une initiative de normalisation des agents d'intelligence artificielle en février 2026, une évaluation complète englobe quatre dimensions essentielles.
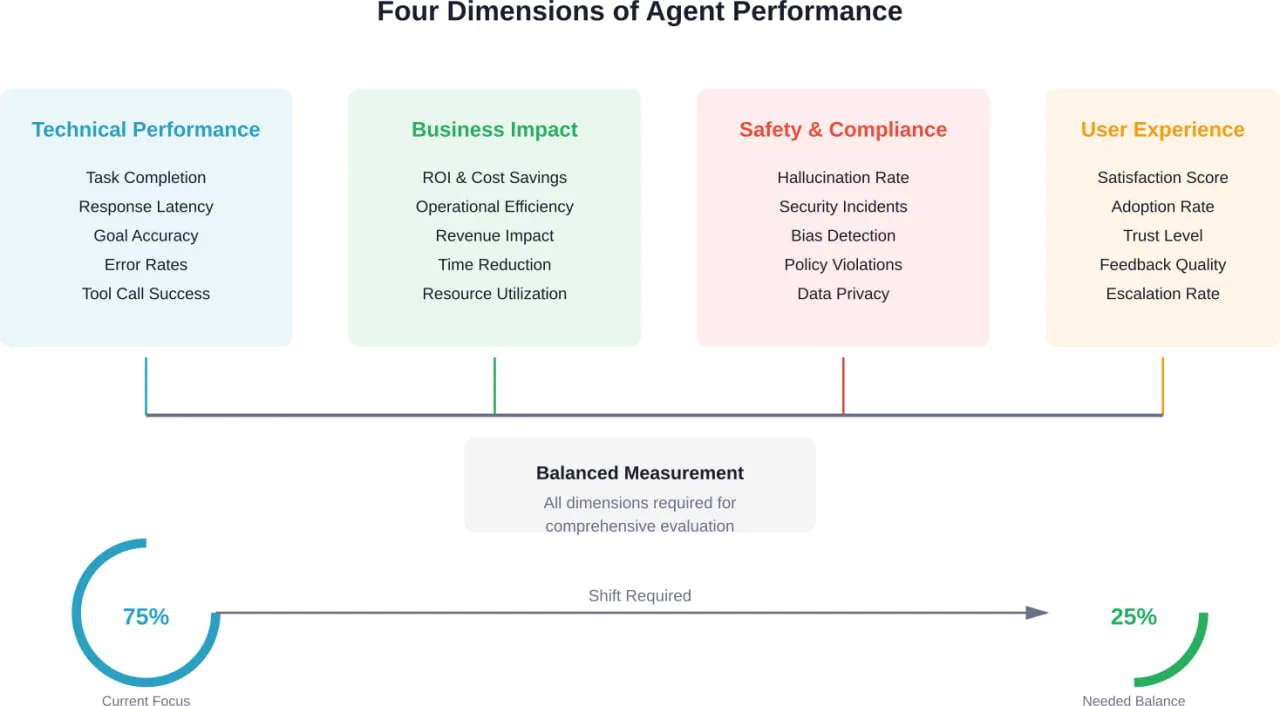
Chaque dimension répond à des besoins différents des parties prenantes. Les équipes techniques ont besoin de mesures opérationnelles. Les chefs d'entreprise ont besoin d'une justification financière. Les équipes chargées de la conformité ont besoin d'une garantie de sécurité. Les utilisateurs finaux ont besoin d'une fiabilité pratique.
Mesures essentielles de la performance technique
Les mesures techniques constituent la base. Elles permettent de déterminer si l'agent exécute ses fonctions principales de manière fiable.
Taux d'achèvement des tâches
Il s'agit du pourcentage de tâches qu'un agent accomplit sans intervention humaine. Les données de l'industrie montrent que les agents bien implémentés atteignent 85-95% d'achèvement autonome pour les tâches structurées.
Mais l'accomplissement des tâches ne suffit pas à rendre compte de la situation. Un agent peut accomplir 90% de tâches tout en prenant deux fois plus de temps que nécessaire ou en commettant des erreurs critiques en cours de route.
Précision de l'objectif
La précision des objectifs mesure si les agents atteignent les résultats escomptés, et pas seulement l'achèvement des tâches. Cette mesure principale doit être évaluée à 85%+ pour les agents de production. Toute valeur inférieure à 80% indique des problèmes importants nécessitant une attention immédiate.
La distinction est importante. Un agent peut accomplir une tâche (exécuter toutes les étapes) sans atteindre l'objectif (produire le résultat correct).
Temps de réponse et débit
La vitesse a un impact direct sur l'expérience de l'utilisateur. Les agents qui traitent les demandes des clients ont besoin de temps de réponse inférieurs à la seconde pour les requêtes simples. Les flux de travail complexes à plusieurs étapes peuvent prendre plus de temps, mais les utilisateurs ont besoin d'une visibilité sur la progression.
Le débit mesure le nombre de demandes qu'un agent traite simultanément. Les agents de production doivent généralement pouvoir traiter des centaines ou des milliers d'opérations simultanées.
Taux de réussite des appels à l'outil
Les agents modernes interagissent avec des outils externes, des API et des bases de données. Chaque point d'intégration présente un risque d'échec. Le suivi des appels d'outils réussis ou échoués révèle la fiabilité de l'intégration.
Selon une recherche publiée sur arXiv analysant l'évaluation des agents LLM, les erreurs d'utilisation des outils représentent un mode de défaillance important. Les appels d'outils hallucinés - où les agents tentent d'utiliser des fonctions inexistantes - apparaissent fréquemment dans les systèmes mal configurés.
Classification et récupération des erreurs
Toutes les erreurs n'ont pas le même poids. Une erreur de formatage diffère grandement d'une violation de la sécurité. Une surveillance efficace permet de classer les erreurs en fonction de leur gravité et de suivre le succès de la récupération.
L'agent peut-il détecter ses propres erreurs ? Réessaie-t-il de manière appropriée ? Fait-il appel à des humains lorsque cela est nécessaire ? La capacité de récupération est souvent plus importante que les taux d'erreur bruts.
| Métrique | Fourchette cible | Seuil d'alerte | Seuil critique |
|---|---|---|---|
| Taux d'achèvement des tâches | 85-95% | <85% | <75% |
| Précision de l'objectif | 85%+ | <85% | <80% |
| Temps de réponse (simple) | <1 seconde | >2 secondes | >5 secondes |
| Temps de réponse (complexe) | <10 secondes | >20 secondes | >30 secondes |
| Succès de l'appel à outils | 95%+ | <90% | <85% |
| Taux de récupération des erreurs | 80%+ | <70% | <60% |
Des mesures de l'impact sur l'entreprise qui stimulent la prise de décision
L'excellence technique ne signifie rien si l'entreprise ne peut pas justifier l'investissement. D'après les enquêtes menées dans le secteur, les leaders technologiques considèrent la qualité des performances comme une préoccupation majeure, mais les parties prenantes ont besoin de preuves financières.
Retour sur investissement et économies de coûts
Le calcul du retour sur investissement des agents d'IA nécessite de suivre les coûts directs et indirects. Les coûts directs comprennent l'infrastructure, les appels d'API et le temps de développement. Les coûts indirects comprennent les frais généraux de surveillance, la correction des erreurs et la maintenance.
Les économies proviennent de la réduction des coûts de main-d'œuvre, de l'accélération des délais de traitement et de l'amélioration de la précision. Les recherches menées par l'école d'information de Berkeley soulignent que le suivi du retour sur investissement doit tenir compte de l'ensemble du cycle de vie de l'agent, et pas seulement de son déploiement initial.
Gains d'efficacité opérationnelle
Quelle est la rapidité d'exécution du travail ? Combien d'heures de travail humain sont réorientées vers des tâches à plus forte valeur ajoutée ?
Une mesure efficace compare les performances des agents aux performances humaines de référence pour les mêmes tâches. Les équipes qui déploient des agents pour le traitement des factures, le service à la clientèle ou la saisie de données font généralement état d'une réduction du temps de 60 à 80% une fois que les agents ont atteint la maturité de production.
Impact sur les revenus et optimisation des conversions
Pour les agents en contact avec la clientèle, c'est l'impact sur le chiffre d'affaires qui compte le plus. L'agent augmente-t-il les taux de conversion ? Réduit-il les abandons de panier ? Fait-il de la vente incitative de manière efficace ?
Les agents chargés du commerce électronique qui s'occupent des recommandations de produits doivent suivre les taux de clics, les taux d'ajout au panier et l'achèvement de l'achat. Les agents du service clientèle doivent surveiller les taux de résolution et l'évolution de la valeur de la vie du client.
Utilisation des ressources et coûts de mise à l'échelle
Les agents d'IA consomment des ressources informatiques. L'utilisation de jetons pour les appels LLM, les limites de taux de l'API, les requêtes de base de données et le temps de traitement contribuent tous aux coûts d'exploitation.
Les systèmes de production ont besoin d'un suivi détaillé des coûts par tâche, par utilisateur et par période. Cette granularité permet d'optimiser le système en identifiant les opérations coûteuses, les invites inefficaces ou les appels d'outils inutiles.
Mesures de sécurité et de conformité
Les défaillances en matière de sécurité peuvent détruire instantanément la confiance. Selon des recherches menées à Stanford et à Princeton sur l'établissement de critères agentiques rigoureux, l'évaluation de la sécurité devrait être systématique et continue, et non pas un point de contrôle ponctuel.
Détection et mesure des hallucinations
Les hallucinations - lorsque les agents génèrent des informations plausibles mais incorrectes - représentent l'un des modes de défaillance les plus dangereux. Dans des domaines à fort enjeu comme la finance, une étude de référence a révélé que les modèles les plus récents commettaient encore des erreurs critiques dans des environnements contradictoires.
Le benchmark CAIA, qui teste les agents d'IA sur les marchés financiers, a révélé des lacunes importantes où les modèles n'atteignent qu'une précision de 12-28% sur des tâches que les analystes juniors traitent couramment. Rien qu'en 2024, plus de $30 milliards ont été perdus à cause d'exploits et d'escroqueries sur les marchés des crypto-monnaies.
La mesure des taux d'hallucination nécessite une évaluation humaine, une vérification automatisée des faits par rapport à la vérité de base et des boucles de retour d'information de la part des utilisateurs. Les systèmes de production devraient suivre la fréquence des hallucinations par type de tâche et par niveau de gravité.
Suivi des incidents de sécurité
Les agents interagissent avec les systèmes sensibles. Ils accèdent aux bases de données, appellent les API et manipulent les données des utilisateurs. Chaque point d'interaction représente une vulnérabilité potentielle en matière de sécurité.
Le Cybersecurity AI Benchmark (CAIBench), un méta-benchmark pour l'évaluation des agents IA de cybersécurité, met l'accent sur l'évaluation offensive-défensive systématique. La recherche montre que les modèles d'IA de pointe atteignent un succès d'environ 70% sur les mesures de connaissances en matière de sécurité, mais se dégradent considérablement pour atteindre un succès de 20-40% dans les scénarios adverses à plusieurs étapes, ce qui indique qu'il y a une marge d'amélioration substantielle.
Les mesures de sécurité doivent permettre de suivre les tentatives d'accès non autorisé, les incidents de fuite de données, les succès d'injection rapide et les violations de politiques. Les seuils de tolérance zéro s'appliquent : même les incidents isolés doivent faire l'objet d'une enquête.
Détection des biais et évaluation de l'équité
Les agents d'IA peuvent perpétuer ou amplifier les biais présents dans les données d'apprentissage. Pour les applications en contact avec la clientèle, les comportements biaisés entraînent une responsabilité juridique et une atteinte à la réputation.
L'évaluation de l'équité nécessite de tester les réponses des agents à travers les groupes démographiques, les cas d'utilisation et les cas limites. L'ensemble de données StereoSet, développé par des chercheurs en PNL de McGill, fournit des cadres de mesure de biais standardisés qui testent les stéréotypes de race, de sexe, de profession et de religion.
Préservation de la vie privée et traitement des données
Les agents traitent les données des utilisateurs pour accomplir des tâches. Ces données doivent être protégées. Les mesures de confidentialité permettent de suivre les périodes de conservation des données, l'utilisation du cryptage, l'efficacité de l'anonymisation et la conformité avec des réglementations telles que le GDPR ou le CCPA.
Le CAIBench comprend une évaluation des performances en matière de préservation de la vie privée grâce à sa composante CyberPII-Bench, qui évalue le traitement des informations personnelles identifiables par les agents.
Expérience de l'utilisateur et mesures d'adoption
L'excellence technique et la valeur commerciale ne signifient rien si les utilisateurs ne se servent pas de l'agent. Les mesures de l'expérience utilisateur révèlent si les agents apportent une valeur pratique dans des conditions réelles.
Satisfaction des utilisateurs et Net Promoter Score
Le retour d'information direct des utilisateurs fournit des informations irremplaçables. Les enquêtes post-interaction, les évaluations de satisfaction et les Net Promoter Scores (NPS) quantifient le sentiment des utilisateurs.
Les systèmes de production doivent recueillir des informations en plusieurs points - après l'achèvement d'une tâche, au cours d'interactions prolongées et par le biais d'enquêtes périodiques. Les objectifs de satisfaction sont généralement de 4+ sur 5 ou 70%+ d'évaluations positives.
Taux d'adoption et utilisation active
Combien d'utilisateurs prévus utilisent réellement l'agent ? À quelle fréquence ? Les indicateurs d'adoption révèlent si les agents apportent suffisamment de valeur pour modifier le comportement des utilisateurs.
Une faible adoption malgré de bonnes mesures techniques indique des problèmes d'interface utilisateur, une formation insuffisante ou des cas d'utilisation mal alignés. Une forte adoption initiale suivie d'un déclin de l'utilisation indique un enthousiasme initial suivi d'une déception.
Indicateurs de confiance et schémas d'escalade
Les utilisateurs font-ils confiance aux résultats des agents ? Les taux d'escalade - la fréquence à laquelle les utilisateurs demandent une vérification humaine ou passent outre les décisions de l'agent - révèlent les niveaux de confiance.
Les taux d'escalade sains varient en fonction du domaine. Les décisions à fort enjeu (diagnostics médicaux, transactions financières) devraient avoir des taux d'escalade plus élevés que les tâches à faible enjeu (planification, saisie de données).
Qualité du retour d'information et possibilité d'action
La qualité du retour d'information de l'utilisateur compte autant que la quantité. Un retour d'information détaillé permet d'apporter des améliorations spécifiques. Les rapports génériques “ne fonctionne pas” n'ont qu'une valeur limitée par rapport à “n'a pas réussi à traiter les factures avec des codes de devises internationaux”.”
Les systèmes doivent enregistrer un retour d'information structuré - quelle tâche a été tentée, ce qui n'a pas fonctionné, ce que l'utilisateur attendait et l'importance de l'échec.
Construire un cadre de mesure
Les mesures individuelles fournissent des points de données. Un cadre les relie pour en faire des informations exploitables.
Établissement de la performance de référence
Une mesure efficace nécessite des données de référence. Quelle est la performance actuelle sans l'agent ? Comment les humains effectuent-ils les mêmes tâches ?
L'établissement d'une base de référence devrait permettre de recueillir des informations :
- Délai et coût d'achèvement de la tâche en cours
- Taux et types d'erreurs humaines
- Satisfaction des utilisateurs à l'égard des processus existants
- Coûts opérationnels et utilisation des ressources
Ces données de référence permettent d'effectuer des comparaisons significatives et de calculer le retour sur investissement.
Fixer des repères et des objectifs réalistes
Selon une étude du cadre de gestion des risques liés à l'IA du NIST, la définition des objectifs doit concilier ambition et réalisme. En visant une précision de 99,9% dès le premier jour, les équipes s'exposent à l'échec.
Les objectifs progressifs sont plus efficaces. Le déploiement initial pourrait viser l'accomplissement des tâches 70% sous la surveillance de l'homme. Les systèmes matures augmentent progressivement l'autonomie au fur et à mesure que la fiabilité s'améliore.
Le benchmark FinGAIA, une évaluation de bout en bout des agents d'IA dans le domaine de la finance, témoigne d'une définition réaliste des objectifs. Chaque tâche de ce benchmark a nécessité environ 90 minutes de conception et d'annotation manuelles, ce qui reflète la complexité d'une évaluation de haute qualité.
Mise en œuvre de la surveillance continue
Une évaluation unique ne suffit pas. Les performances des agents varient en fonction de la distribution des données, de l'émergence de cas particuliers et de la mise à jour des modèles sous-jacents.
Le contrôle de la production doit être continu et automatisé. Des tableaux de bord en temps réel permettent de suivre les paramètres clés. Des alertes automatisées signalent les anomalies. Des audits réguliers permettent de détecter les dérives avant qu'elles ne deviennent critiques.
Créer des boucles de rétroaction pour l'amélioration
Mesurer sans agir, c'est gaspiller des ressources. Les cadres efficaces bouclent la boucle : les mesures éclairent les décisions, les décisions conduisent à des améliorations, les améliorations sont à nouveau mesurées.
Selon les meilleures pratiques d'évaluation de l'OpenAI, les équipes devraient établir des cycles de révision réguliers. Examens hebdomadaires des mesures critiques. Des analyses mensuelles approfondies du retour d'information des utilisateurs. Réévaluation trimestrielle des objectifs et des repères.
Méthodes d'évaluation et stratégies de test
Différentes méthodes d'évaluation répondent à des objectifs différents. La surveillance de la production permet de détecter les problèmes en direct. Les tests hors ligne permettent de valider les modifications avant leur déploiement. Les ensembles de données de référence permettent une comparaison normalisée.
Évaluation en ligne avec les données de production
L'évaluation en ligne permet de contrôler les performances des agents en direct avec des utilisateurs réels. Cette méthode offre la vision la plus précise des performances réelles, mais comporte un risque : les erreurs affectent les utilisateurs réels.
Selon le livre de recettes d'évaluation Langfuse pour les agents, l'évaluation en ligne doit comprendre les éléments suivants :
- Suivi en temps réel de toutes les interactions
- Mécanismes de collecte des commentaires des utilisateurs
- Détection d'anomalies et alertes automatisées
- Relecture de la session pour déboguer les interactions problématiques
Les données de production reflètent la réalité. Des cas de figure qui n'apparaissent jamais dans les ensembles de données de test font constamment surface. Les modèles de comportement des utilisateurs changent. L'évaluation en ligne permet de saisir cette variabilité.
Évaluation hors ligne avec des ensembles de données de référence
L'évaluation hors ligne fait appel à des ensembles de données curatées dont les réponses correctes sont connues. Cela permet d'effectuer des tests contrôlés sans risque pour les utilisateurs.
La liste de contrôle Agentic Benchmark Checklist (ABC), synthétisée à partir de l'expérience et des meilleures pratiques en matière de construction de repères, fournit des lignes directrices pour une évaluation hors ligne rigoureuse. Appliquée à CVE-Bench, un benchmark dont les exigences d'évaluation sont particulièrement complexes, l'ABC a permis d'améliorer la fiabilité de manière significative.
Les ensembles de données hors ligne doivent comprendre
- Exemples de tâches représentatives couvrant des scénarios courants
- Cas limites et modes de défaillance connus
- Exemples contradictoires testant la robustesse
- Étiquettes de vérité terrain pour la notation automatisée
Évaluation du programme LLM en tant que juge
L'évaluation LLM-as-judge utilise un modèle de langage pour évaluer le résultat d'un autre modèle. Cette approche s'adapte efficacement et gère l'évaluation subjective de la qualité que les mesures automatisées ont du mal à gérer.
Selon une étude du Digital Economy Lab de Stanford, l'utilisation d'un LLM en tant que juge permet d'évaluer la qualité de la production sur la base de critères spécifiques. Cela permet un contrôle de qualité rapide et évolutif pour des systèmes tels que les chatbots ou les générateurs de contenu.
Mais les juges du LLM ont des limites. Ils peuvent perpétuer des préjugés. Ils sont parfois en désaccord avec les évaluateurs humains. Ils fonctionnent mieux lorsqu'ils sont combinés à d'autres méthodes d'évaluation.
Le cadre WebJudge, développé par des chercheurs et référencé à l'École de recherche sur l'information de Berkeley, fournit un retour d'information plus approfondi pour les exécutions agentiques. Il a démontré une concordance de >85% entre WebJudge et l'évaluation humaine lors de l'utilisation du modèle o4-mini d'OpenAI.
Évaluation humaine et examen par des experts
Les mesures automatisées ne peuvent pas tout saisir. L'évaluation humaine reste essentielle :
- Évaluation subjective de la qualité (utilité, clarté, ton)
- Validation de raisonnements complexes
- Sécurité et considérations éthiques
- Nouvelle découverte du mode de défaillance
L'évaluation humaine est plus coûteuse et moins efficace que l'automatisation. L'utilisation stratégique concentre l'examen humain sur les domaines où les mesures automatisées fournissent un signal insuffisant.
| Méthode d'évaluation | Meilleur pour | Limites | Fréquence typique |
|---|---|---|---|
| Production en ligne | Performances en conditions réelles, comportement des utilisateurs | Risque pour les utilisateurs, difficultés à isoler les variables | En continu |
| Évaluation comparative hors ligne | Tests contrôlés, détection de la régression | Peut ne pas refléter la réalité, ensembles de données statiques | Avant chaque déploiement |
| LLM en tant que juge | Qualité subjective, échelle | Partialité potentielle, désaccord avec les humains | Quotidien à hebdomadaire |
| Revue humaine | Évaluation nuancée, sécurité | Coûteux, lent, non évolutif | Hebdomadaire à mensuel |
Défis communs en matière de mesure de la performance des agents
Même avec de bons cadres, l'évaluation est confrontée à des défis persistants. Les comprendre permet de trouver de meilleures solutions.
Gestion de la variabilité et du non-déterminisme
Les modèles linguistiques ne sont pas déterministes. La même entrée peut produire des sorties différentes. Cela rend les tests de logiciels traditionnels inadéquats.
L'évaluation doit tenir compte des variations acceptables. Un agent du service clientèle peut répondre à la même question de plusieurs façons, toutes correctes mais formulées différemment.
Les techniques de gestion de la variabilité comprennent
- Evaluation de la similarité sémantique au lieu de la correspondance exacte
- Réponses de référence multiples pour comparaison
- Intervalles de confiance au lieu d'estimations ponctuelles
- Agrégation sur plusieurs séries
Évaluation du raisonnement à plusieurs étapes et de l'utilisation des outils
Les agents modernes effectuent des flux de travail complexes en plusieurs étapes. Ils décomposent les problèmes en sous-tâches, font appel à des outils et enchaînent les opérations.
L'évaluation des étapes intermédiaires est aussi importante que les résultats finaux. Un agent peut parvenir à la bonne réponse grâce à un raisonnement erroné - un problème qui se manifeste plus tard lorsque les contextes changent.
Le cadre de simulation multi-agents à très grande échelle d'AgentScope démontre la complexité de l'évaluation des systèmes multi-agents. Les améliorations apportées à la plateforme améliorent l'évolutivité et la facilité d'utilisation des simulations à grande échelle grâce à une architecture distribuée.
Équilibrer l'automatisation et la surveillance humaine
L'automatisation complète permet de passer à l'échelle supérieure, mais ne tient pas compte des nuances. L'examen humain complet permet de saisir les nuances, mais ne permet pas de passer à l'échelle supérieure.
Les approches efficaces combinent les deux. Des mesures automatisées signalent les problèmes potentiels. Des examinateurs humains étudient les cas signalés. Les cas marginaux permettent d'améliorer les mesures automatisées.
Exigences d'évaluation spécifiques au domaine
Les exigences varient selon les domaines. Les agents financiers ont besoin d'une extrême précision. Les agents du service clientèle ont besoin d'empathie et de gestion du ton. Les agents de génération de code ont besoin d'une correction fonctionnelle.
Le benchmark FinGAIA démontre une évaluation spécifique à un domaine pour les agents financiers. Toutes les tâches ont été formulées à la suite de discussions avec des experts financiers, et chaque question a nécessité environ 90 minutes pour sa conception, son annotation et sa vérification.
Les cadres d'évaluation génériques doivent être adaptés au domaine. Ce qui est considéré comme “bon” varie considérablement d'un cas d'utilisation à l'autre.
Outils et plateformes pour l'évaluation des agents
De nombreuses plates-formes fournissent aujourd'hui une infrastructure d'évaluation des agents. Les capacités varient considérablement.
Langfuse pour l'observabilité et les essais
Langfuse fournit un traçage et une évaluation complets pour les applications et les agents LLM. Il capture les étapes internes de l'agent, ce qui permet une analyse détaillée des performances.
La plateforme prend en charge à la fois le suivi de la production en ligne et l'évaluation des ensembles de données hors ligne. Les équipes l'utilisent pour comparer les variantes, suivre les coûts et identifier les régressions de performance.
Poids et biais pour le suivi des expériences
Weights & Biases (W&B) permet le suivi des expériences, l'évaluation des modèles et la visualisation. Les équipes l'utilisent pour comparer les configurations des agents, suivre les mesures dans le temps et partager les résultats entre les organisations.
W&B s'intègre aux cadres d'agents courants, ce qui permet l'enregistrement et la visualisation automatisés des mesures sans instrumentation personnalisée.
Evals OpenAI pour les tests standardisés
Le cadre Evals de l'OpenAI fournit des modèles d'évaluation et des ensembles de données standardisés. Il permet d'effectuer des tests cohérents entre les versions et les configurations des modèles.
Selon la documentation sur les meilleures pratiques d'évaluation de l'OpenAI, les équipes devraient utiliser un mélange de données de production et d'ensembles de données créés par des experts. Pour les tâches de résumé, les implémentations doivent atteindre un score ROUGE-L d'au moins 0,40 et un score de cohérence d'au moins 80% en utilisant G-Eval sur des ensembles conservés.
Pipelines d'évaluation personnalisés
Certaines équipes construisent une infrastructure d'évaluation personnalisée. Cette solution offre une flexibilité maximale mais nécessite un investissement technique important.
Les pipelines personnalisés sont utiles lorsque :
- Les exigences du domaine ne correspondent pas aux outils existants
- L'intégration avec les systèmes propriétaires est essentielle
- L'échelle dépasse les limites de la plate-forme commerciale
- Les exigences réglementaires imposent des contrôles spécifiques
Faites en sorte que les mesures de votre agent d'IA soient réellement utiles
Les mesures de performance n'ont d'importance que si le système qui les sous-tend est fiable. Dans la pratique, les problèmes viennent souvent de la façon dont les données sont collectées, de la façon dont les services interagissent et de la question de savoir si le backend peut prendre en charge des mesures cohérentes dans le temps.
A-listware travaille sur cette couche avec des équipes de développement dédiées. L'accent est mis sur les systèmes dorsaux, les intégrations et l'infrastructure qui supportent un flux de données et un reporting stables, de sorte que les mesures de performance reflètent les conditions réelles plutôt que des résultats partiels. Contact Logiciel de liste A pour faciliter la mise en place du système et assurer l'exactitude des mesures en production.
Orientations futures de l'évaluation des agents
L'évaluation des agents continue d'évoluer au fur et à mesure que les agents deviennent plus performants et plus répandus.
Efforts de normalisation et références industrielles
L'initiative de normalisation des agents d'IA du NIST, annoncée en février 2026, vise à garantir que l'IA de nouvelle génération soit largement adoptée en toute confiance, qu'elle fonctionne en toute sécurité et qu'elle interopère sans heurts dans l'écosystème numérique.
Cette initiative témoigne de la reconnaissance croissante du fait que les cadres d'évaluation normalisés profitent à l'ensemble du secteur. Des critères de référence cohérents permettent des comparaisons significatives et accélèrent l'amélioration.
Tests contradictoires et Red Teaming
À mesure que les agents gèrent des tâches aux enjeux plus importants, les tests d'adversité deviennent essentiels. Le test de référence CAIA met en évidence un point faible essentiel de l'évaluation de l'IA, à savoir l'incapacité à fonctionner dans des environnements contradictoires à enjeux élevés, où la désinformation est utilisée comme arme et où les erreurs sont coûteuses.
La recherche montre des lacunes importantes en matière de robustesse à l'adversité. Les agents qui fonctionnent bien dans des conditions bénignes échouent souvent de manière spectaculaire lorsqu'ils sont confrontés à une manipulation intentionnelle.
Évaluation des systèmes multi-agents
De nombreux systèmes de production font désormais appel à la collaboration de plusieurs agents. Le cadre TradingAgents démontre des systèmes LLM multi-agents pour la négociation d'actions, en simulant des sociétés de négociation du monde réel.
L'évaluation multi-agents nécessite de nouvelles mesures - efficacité de la coordination, surcharge de communication, comportements émergents et résultats au niveau du système au-delà des performances individuelles des agents.
Mesures d'apprentissage continu et d'adaptation
Les agents statiques céderont la place à des systèmes qui apprennent à partir des interactions. L'évaluation doit porter sur l'efficacité de l'apprentissage - la rapidité avec laquelle les agents s'améliorent, la généralisation des améliorations et l'introduction de nouveaux modes de défaillance par l'adaptation.
Questions fréquemment posées
- Quelle est la mesure la plus importante pour évaluer les performances des agents d'IA ?
Il n'y en a pas un seul. La précision des objectifs (85%+ pour les agents de production) constitue la meilleure mesure technique unique, mais une évaluation complète nécessite de trouver un équilibre entre la performance technique, l'impact sur l'entreprise, la sécurité et l'expérience de l'utilisateur. Selon la recherche, 83% d'évaluation se concentrent sur les mesures techniques alors que seulement 30% prennent en compte les facteurs centrés sur l'utilisateur ou économiques - ce déséquilibre est source de problèmes. La mesure la plus importante dépend de l'objectif de votre agent et des parties prenantes.
- À quelle fréquence les agents d'IA doivent-ils être évalués en production ?
En permanence. Les paramètres essentiels doivent être surveillés en temps réel et les anomalies doivent faire l'objet d'alertes automatiques. Les examens hebdomadaires doivent permettre d'analyser les tendances et le retour d'information des utilisateurs. Les analyses approfondies mensuelles doivent porter sur les cas limites et les modes de défaillance. Les évaluations trimestrielles doivent permettre de réévaluer les objectifs et les critères de référence. Le cadre d'évaluation Langfuse recommande cette cadence pour les systèmes de production traitant un volume important d'utilisateurs.
- Quel est un taux d'achèvement des tâches réaliste pour un nouvel agent d'intelligence artificielle ?
Les données de l'industrie montrent que les agents bien implémentés atteignent une autonomie de 85-95% pour les tâches structurées. Mais les nouveaux agents commencent généralement plus bas - 60-70% est courant lors du déploiement initial avec une supervision humaine. Au fur et à mesure que les équipes affinent les messages-guides, améliorent la gestion des erreurs et augmentent les données de formation, les taux d'achèvement augmentent. Tout taux inférieur à 75% pour les agents de production matures indique des problèmes importants nécessitant une attention particulière.
- Comment mesurer le retour sur investissement des agents d'IA ?
Suivez les coûts (infrastructure, appels d'API, temps de développement, frais généraux de surveillance, maintenance) et les avantages (réduction des coûts de main-d'œuvre, traitement plus rapide, amélioration de la précision, impact sur les recettes). De nombreuses organisations déclarent avoir atteint un retour sur investissement positif en l'espace de plusieurs mois, car les économies cumulées dépassent les coûts de développement et d'exploitation. Calculer le coût par tâche accomplie et le comparer à la référence humaine. Inclure à la fois l'impact financier direct et les avantages indirects tels que la satisfaction des employés résultant de l'élimination du travail fastidieux.
- Quelle est la différence entre l'accomplissement d'une tâche et la précision d'un objectif ?
L'achèvement de la tâche permet de déterminer si l'agent a terminé toutes les étapes. L'exactitude de l'objectif permet de déterminer si l'agent atteint le résultat escompté. Un agent peut achever une tâche (exécuter toutes les opérations) sans atteindre l'objectif (produire le bon résultat). Par exemple, un agent peut interroger avec succès une base de données, traiter les résultats et formater la sortie (100% pour l'achèvement de la tâche), mais renvoyer des informations non pertinentes en raison d'erreurs dans la construction de la requête (0% pour la précision de l'objectif). La précision des objectifs devrait être de 85%+ pour les systèmes de production.
- Comment évaluez-vous les qualités subjectives telles que la serviabilité ou le ton de l'agent ?
Combiner l'évaluation LLM en tant que juge avec l'examen humain et le retour d'information de l'utilisateur. Les approches LLM-as-judge s'adaptent efficacement en utilisant un modèle linguistique pour évaluer les résultats d'un autre modèle sur la base de critères spécifiques. Mais elles ont besoin d'être validées par des jugements humains. Les enquêtes de satisfaction des utilisateurs, les Net Promoter Scores et le retour d'information qualitatif capturent l'expérience subjective. Pour les applications sensibles au ton, comme le service clientèle, l'évaluation humaine experte d'un échantillon représentatif (100 à 500 interactions par mois) fournit une vérité de base pour calibrer la notation automatisée.
- Quels sont les outils permettant de contrôler les performances des agents d'IA ?
Plusieurs plateformes fournissent une infrastructure d'évaluation des agents. Langfuse offre un traçage et une évaluation complets avec un support pour le suivi en ligne et les tests hors ligne. Weights & Biases assure le suivi et la visualisation des expériences dans toutes les configurations. Le cadre Evals d'OpenAI offre des modèles et des ensembles de données standardisés. De nombreuses équipes construisent également des pipelines personnalisés lorsque les exigences du domaine ne correspondent pas aux outils existants ou lorsque l'intégration avec des systèmes propriétaires est essentielle. Le meilleur choix dépend de la complexité de l'agent, de son échelle et de l'expertise de l'équipe.
Conclusion
L'analyse des performances des agents d'IA n'est plus facultative - elle fait la différence entre un déploiement réussi et un échec coûteux.
Les indicateurs qui comptent couvrent quatre dimensions. Les performances techniques garantissent la fiabilité de l'exécution des agents. L'impact commercial justifie l'investissement. La sécurité et la conformité préviennent les défaillances catastrophiques. L'expérience utilisateur favorise l'adoption.
Il n'existe pas de mesure unique qui permette de tout appréhender. Les cadres d'évaluation équilibrés combinent le contrôle automatisé, les tests hors ligne, le retour d'information des utilisateurs et l'examen par des experts. Ils établissent des bases de référence, fixent des objectifs réalistes, assurent un suivi continu et bouclent les boucles de rétroaction.
Selon une étude du MIT, 95% des investissements dans l'IA ne produisent aucun rendement mesurable. Non pas parce que la technologie ne fonctionne pas, mais parce que les organisations ne peuvent pas prouver qu'elle fonctionne. Une analyse rigoureuse des performances change cette équation.
Commencez par l'exactitude des objectifs et le taux d'achèvement des tâches, qui fournissent un signal immédiat. Élargissez votre champ d'action aux mesures commerciales qui intéressent les parties prenantes. Ajoutez des garde-fous et un suivi de l'expérience utilisateur. Construire progressivement plutôt que d'essayer de tout mesurer en même temps.
Le paysage de l'évaluation des agents continue d'évoluer. Les efforts de normalisation du NIST, les références émergentes telles que FinGAIA et CAIA, et les nouveaux cadres tels que la liste de contrôle de l'évaluation comparative des agents indiquent une maturité croissante.
Les organisations qui maîtrisent la mesure de la performance des agents déploieront l'IA en toute confiance, l'optimiseront systématiquement et la feront évoluer avec succès. Celles qui ne le font pas auront du mal à justifier leurs investissements, manqueront des échecs critiques et verront l'adoption stagner malgré les capacités techniques.
Le défi n'est plus de créer des agents. Il s'agit de prouver qu'ils fonctionnent, de les maintenir en activité et de les améliorer. Pour ce faire, il est nécessaire d'effectuer des mesures exhaustives, continues et liées aux décisions.
Prêt à évaluer correctement vos agents ? Commencez par identifier les trois indicateurs qui comptent le plus pour vos principaux interlocuteurs. Mettez en place un suivi de ces paramètres dans un premier temps. Développez à partir de là. Il n'est pas nécessaire que les mesures soient parfaites dès le premier jour. Il suffit de commencer.


