Résumé rapide : Les diagrammes d'architecture d'agents d'IA visualisent les composants essentiels des systèmes d'IA autonomes : couches de raisonnement, modèles d'orchestration, gestion des états et intégration des outils. Les architectures d'agents modernes suivent généralement un modèle à quatre couches englobant le raisonnement LLM, la logique d'orchestration, l'infrastructure de données et les connexions d'outils externes. La compréhension de ces modèles architecturaux aide les développeurs à construire des systèmes d'agents fiables et évolutifs pour les environnements de production.
L'architecture des agents d'intelligence artificielle détermine si un système fonctionne de manière fiable en production ou s'effondre face à la complexité du monde réel. Pourtant, la plupart des discussions en ligne sur l'architecture présentent des diagrammes de pile simplifiés qui ne ressemblent guère à ce que les équipes de développement mettent réellement en œuvre.
Ce guide présente l'architecture des agents d'IA à l'aide de diagrammes visuels, de modèles éprouvés issus de la recherche universitaire et d'implémentations d'organisations telles que Microsoft et CSIRO. L'accent est mis sur ? Ce qui fonctionne réellement lors de la construction de systèmes autonomes qui raisonnent, se souviennent et agissent.
Comprendre les fondements de l'architecture des agents d'intelligence artificielle
Une architecture d'agent d'IA définit la manière dont les systèmes autonomes perçoivent leur environnement, prennent des décisions et exécutent des actions. Contrairement aux logiciels traditionnels qui suivent des chemins prédéterminés, les architectures d'agents doivent gérer l'incertitude et s'adapter à des conditions dynamiques.
Selon les recherches publiées dans le catalogue de modèles de conception d'agents par le CSIRO (Data61), les agents basés sur des modèles de fondation tirent parti des capacités de raisonnement et de traitement du langage pour fonctionner de manière autonome. Ces systèmes ne se contentent pas de répondre à des requêtes, ils poursuivent des objectifs de manière proactive.
Voici ce qui distingue les véritables architectures d'agents des simples chatbots : les agents conservent un état au fil des interactions, utilisent des outils pour étendre leurs capacités et ont recours à des stratégies de raisonnement pour décomposer les tâches complexes. Un bot de service client qui récupère le solde de votre compte n'est pas nécessairement un agent. Mais un système qui remarque vos habitudes de paiement, suggère de manière proactive un meilleur plan et gère le changement ? C'est un comportement d'agent.
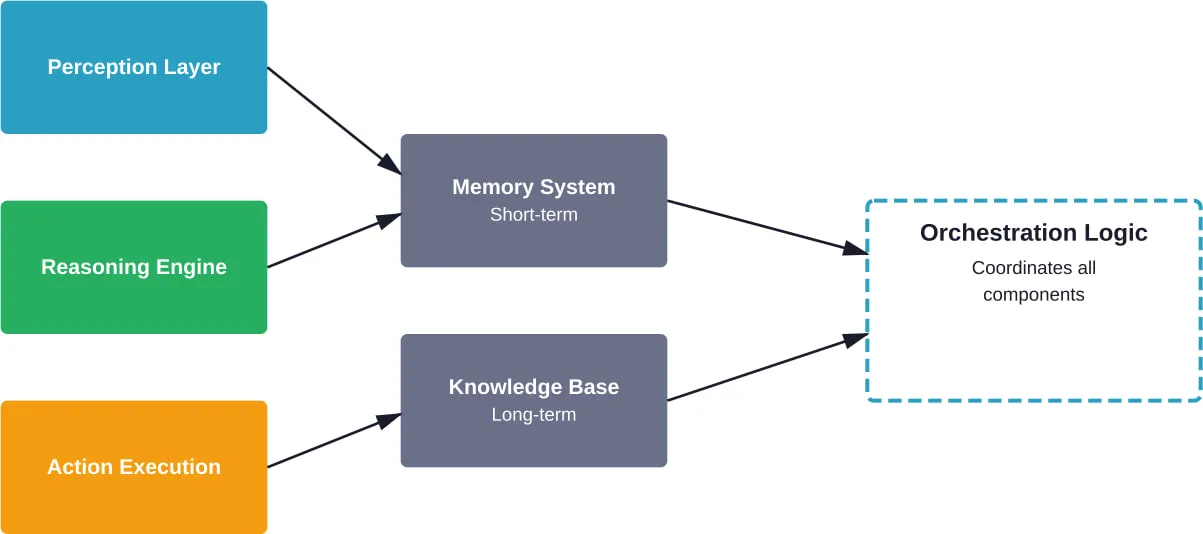
Composants essentiels des systèmes d'agents
Toute architecture d'agent fonctionnel contient ces éléments fondamentaux :
- Couche de perception : Comment l'agent reçoit et traite les informations provenant de son environnement
- Moteur de raisonnement : La composante cognitive, généralement alimentée par de grands modèles de langage
- Système de mémoire : Stockage du contexte à court terme et des connaissances à long terme
- Exécution de l'action : Outils et API que l'agent peut invoquer
- Logique d'orchestration : Le flux de contrôle qui coordonne la perception, le raisonnement et l'action
Des recherches menées par l'université de Halmstad soulignent que la fiabilité de l'IA agentique découle directement des choix architecturaux. La façon dont ces composants sont connectés détermine si un système se dégrade gracieusement dans des conditions inattendues ou s'il connaît une défaillance catastrophique.
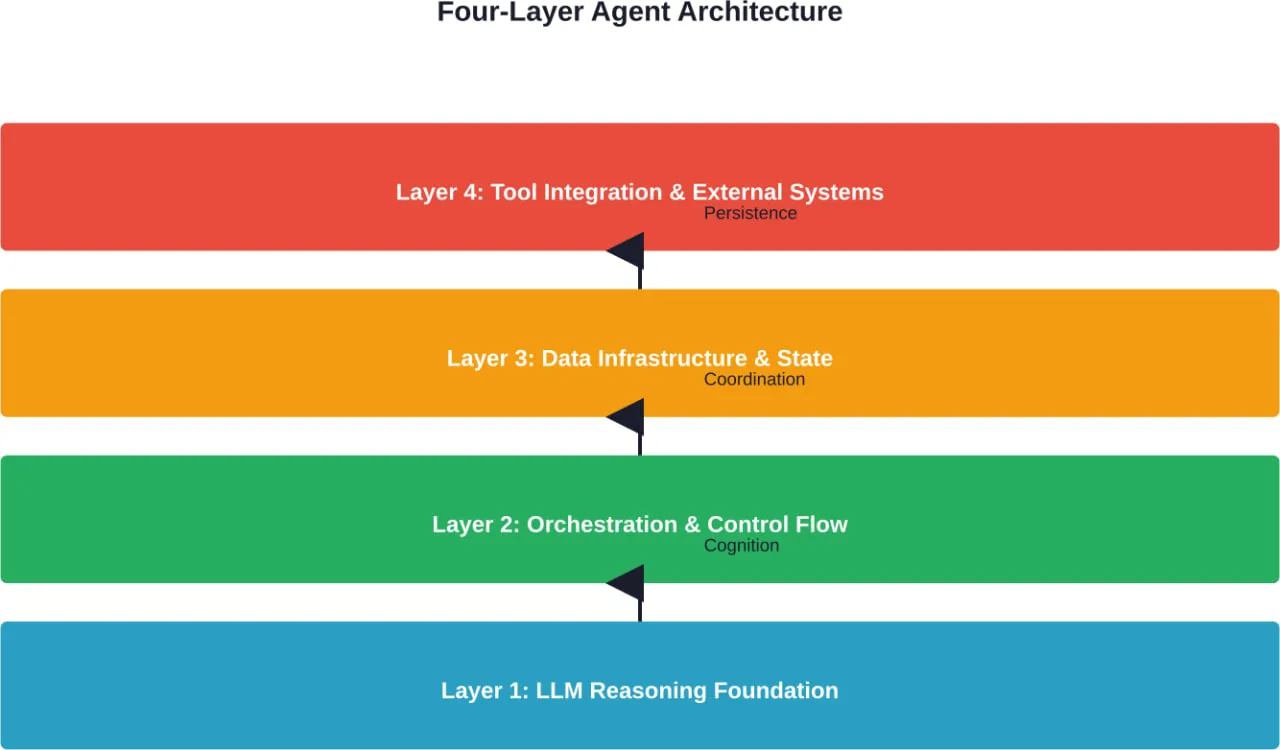
Le modèle d'architecture d'agent à quatre couches
Les systèmes modernes d'agents de production mettent généralement en œuvre un modèle architectural à quatre couches. Cette structure est née de l'expérience pratique de la construction de systèmes qui gèrent la complexité du monde réel sans s'effondrer dans un comportement imprévisible.
Couche 1 : Fondation de raisonnement LLM
À la base se trouve la couche de raisonnement, généralement un ou plusieurs grands modèles de langage. Cette couche gère la compréhension du langage naturel, la décomposition des tâches et la prise de décision. Le LLM ne fait pas fonctionner l'ensemble du système ; il sert de moteur cognitif qui interprète l'intention et planifie les actions.
Différents modèles de raisonnement existent à ce niveau. La chaîne de pensée décompose les problèmes complexes en étapes. Les modèles ReAct (Reasoning + Acting) associent la réflexion et l'utilisation d'outils. Les approches par arbre de pensée explorent simultanément plusieurs voies de raisonnement.
Couche 2 : Orchestration et flux de contrôle
La couche d'orchestration se situe au-dessus du raisonnement et détermine comment l'agent coordonne ses actions. C'est là que les modèles architecturaux deviennent essentiels. Selon la documentation sur les modèles d'orchestration des agents d'IA, les équipes peuvent choisir parmi plusieurs approches éprouvées :
| Modèle | Description | Meilleur pour |
|---|---|---|
| Séquentiel | Les tâches s'exécutent l'une après l'autre dans un ordre prédéterminé. | Des flux de travail prévisibles avec des dépendances claires |
| Concurrent | Tâches multiples exécutées en parallèle, résultats synthétisés | Opérations indépendantes pouvant se dérouler simultanément |
| Chat de groupe | Plusieurs agents spécialisés collaborent par le biais de discussions | Problèmes complexes nécessitant une expertise diversifiée |
| Transfert | Les tâches sont transférées d'un agent à l'autre en fonction du contexte et des capacités. | Service à la clientèle, processus en plusieurs étapes |
| Magentic | Acheminement dynamique vers les agents spécialisés appropriés | Variété de tâches imprévisibles nécessitant de la flexibilité |
L'orchestration séquentielle fonctionne lorsque les flux de travail sont prévisibles. Un agent de réservation de voyages qui vérifie les disponibilités, compare les prix et réserve un billet suit une logique séquentielle. L'orchestration concurrentielle gère les scénarios dans lesquels plusieurs opérations indépendantes peuvent se dérouler simultanément, comme un agent qui recueille des données à partir de cinq API différentes.
Couche 3 : Infrastructure de données et gestion des états
Les agents ont besoin de mémoire, ce qui nécessite une infrastructure. Cette couche gère la manière dont les agents stockent et récupèrent les informations au fil des interactions. La mémoire à court terme conserve le contexte de la conversation au cours d'une session. La mémoire à long terme conserve les connaissances d'une session à l'autre, en utilisant souvent des bases de données vectorielles pour la recherche sémantique.
La gestion des états devient critique en production. Que se passe-t-il lorsqu'un agent tombe en panne au milieu d'une tâche ? La couche d'infrastructure de données garantit que le système peut se rétablir de manière gracieuse, reprendre les flux de travail interrompus et maintenir la cohérence.
Couche 4 : Intégration des outils et systèmes externes
La couche supérieure relie les agents à des capacités externes. Il s'agit d'API, de bases de données, de moteurs de recherche, de calculatrices, d'interprètes de code - tout ce qui permet d'étendre les capacités de l'agent au-delà de la simple génération de langage.
L'intégration des outils nécessite une conception minutieuse de l'interface. Chaque outil a besoin d'une description claire que le LLM peut comprendre, de paramètres explicites et d'une gestion robuste des erreurs. Selon les recherches du CSIRO sur les modèles de conception des agents, des interfaces d'outils bien conçues améliorent considérablement la fiabilité des agents.
Architectures de systèmes multi-agents
Les systèmes à agent unique gèrent bien les tâches simples. Mais les scénarios d'entreprise complexes nécessitent souvent la collaboration de plusieurs agents spécialisés. Les architectures multi-agents répartissent les connaissances entre plusieurs composants autonomes, chacun disposant d'une expertise spécifique.
L'architecture de référence multi-agents de Microsoft montre comment les organisations déploient ces systèmes à grande échelle. Plutôt que de construire un agent massif qui essaie de tout faire, les équipes créent des agents ciblés qui collaborent par le biais de protocoles bien définis.
Quand l'approche multi-agents prend tout son sens
Tous les problèmes ne nécessitent pas des agents multiples. Des recherches menées par l'Université de Tunis sur les cadres d'IA agentique suggèrent que les approches multi-agents excellent dans les scénarios avec :
- Des domaines d'expertise distincts qui ne se chevauchent pas de manière significative
- Tâches qui se décomposent naturellement en sous-tâches parallèles
- Exigences relatives aux différentes stratégies de raisonnement au sein d'un même flux de travail
- Demande d'extension là où des agents isolés créent des goulets d'étranglement
Un système d'analyse financière peut employer des agents distincts pour l'étude de marché, l'évaluation des risques, le respect de la réglementation et l'optimisation du portefeuille. Chaque agent se spécialise profondément dans son domaine, puis collabore avec les autres pour produire des recommandations complètes.
Modèles de coordination dans les systèmes multi-agents
Faire travailler les agents ensemble nécessite des mécanismes de coordination explicites. Le modèle de chat de groupe, décrit dans la documentation d'Azure sur l'orchestration, permet aux agents de communiquer par le biais de la transmission de messages. Un agent pose des questions, les autres répondent avec leurs connaissances spécialisées et un coordinateur synthétise la discussion.
Les modèles de transfert fonctionnent différemment. Dans ce cas, les agents se transfèrent explicitement le contrôle les uns aux autres en fonction des exigences de capacité. Un scénario de service à la clientèle peut commencer par un agent chargé des demandes générales, passer à un spécialiste technique pour les questions complexes, puis à un agent chargé de la facturation pour les questions de paiement.
Les architectures hiérarchiques introduisent des relations leader-suiveur. Un agent superviseur délègue des sous-tâches à des agents travailleurs, surveille leur progression et intègre les résultats. Ce modèle réduit la complexité de la coordination mais introduit des points de défaillance uniques.
Les modèles d'orchestration expliqués
La couche d'orchestration détermine la manière dont les agents exécutent les tâches. Le choix du bon modèle est important, car il a un impact direct sur la fiabilité, les performances et la maintenabilité. Les recherches menées par l'université d'Halmstad soulignent que les choix architecturaux effectués à ce niveau déterminent la fiabilité du système plus que tout autre facteur.
Orchestration séquentielle
L'orchestration séquentielle exécute les tâches les unes après les autres. La première étape est terminée, puis la deuxième commence. Ce modèle fonctionne bien lorsque les opérations ont des dépendances claires et que les résultats des premières étapes éclairent les décisions ultérieures.
Prenons l'exemple d'un agent de recherche qui analyse un article scientifique. Il pourrait d'abord extraire le résumé, puis identifier les concepts clés, rechercher les travaux connexes et enfin synthétiser les résultats. Chaque étape s'appuie sur les résultats précédents, ce qui rend l'exécution séquentielle naturelle.
L'inconvénient ? La latence. Chaque tâche attend que la précédente soit complètement terminée.
Orchestration simultanée
Les modèles simultanés exécutent plusieurs tâches simultanément lorsque les opérations ne dépendent pas les unes des autres. Un agent d'analyse de marché peut interroger dix sources de données différentes en parallèle, puis combiner les résultats une fois que toutes les requêtes sont terminées.
Cela permet de réduire considérablement le temps d'exécution total des opérations indépendantes. Mais elle introduit une certaine complexité : gestion des défaillances partielles, gestion des délais d'attente et synthèse d'informations potentiellement contradictoires.
Chat de groupe et modèles de collaboration
L'orchestration des discussions de groupe traite plusieurs agents spécialisés comme des participants à une discussion. Les agents apportent à tour de rôle des informations, en s'appuyant sur les réponses des uns et des autres. Un agent coordinateur facilite la conversation et détermine quand il y a suffisamment d'informations pour conclure.
Ce modèle est idéal pour les problèmes dont la solution n'est pas évidente. Les questions stratégiques complexes, le brainstorming créatif et les scénarios nécessitant des perspectives diverses bénéficient de l'exploration collaborative.
Modèles de routage magistraux et dynamiques
Le modèle magentic, auquel il est fait référence dans les travaux de Microsoft sur les agents, achemine dynamiquement les tâches vers les agents spécialisés appropriés sur la base de l'analyse du contenu. Plutôt que des flux de travail prédéterminés, le système analyse chaque demande et sélectionne intelligemment l'agent qui doit la traiter.
Cela offre une certaine souplesse pour les charges de travail imprévisibles, mais nécessite une logique de routage robuste et des définitions claires des capacités de l'agent.
| Modèle d'orchestration | Temps de latence | Complexité | Flexibilité | Fiabilité |
|---|---|---|---|---|
| Séquentiel | Haut | Faible | Faible | Haut |
| Concurrent | Faible | Moyen | Moyen | Moyen |
| Chat de groupe | Haut | Haut | Haut | Moyen |
| Transfert | Moyen | Moyen | Moyen | Haut |
| Magentic/Dynamic | Moyen | Haut | Haut | Moyen |
Gestion des états et architecture de la mémoire
Les agents sans mémoire ne peuvent pas maintenir le contexte, apprendre des interactions ou gérer des flux de travail complexes à plusieurs étapes. L'architecture de la mémoire détermine quelles informations sont conservées, comment elles sont récupérées et quand elles expirent.
Fenêtres contextuelles à court terme
La mémoire à court terme gère le contexte immédiat de la conversation. Pour les agents basés sur LLM, il s'agit typiquement de la fenêtre d'invite - tout ce que le modèle voit dans l'interaction en cours. Les fenêtres de contexte ont considérablement augmenté, certains modèles gérant désormais des centaines de milliers de jetons.
Mais des fenêtres plus grandes n'éliminent pas la nécessité d'une gestion intelligente du contexte. Les informations pertinentes doivent apparaître au début et à la fin des invites, là où les modèles sont les plus attentifs. Les détails non pertinents consomment des jetons sans améliorer les performances.
Stockage à long terme des connaissances
La mémoire à long terme persiste d'une session à l'autre. Il peut s'agir de préférences de l'utilisateur, d'interactions historiques, de faits appris ou d'une expertise accumulée. Les bases de données vectorielles permettent une recherche sémantique sur les informations stockées - les agents récupèrent des souvenirs contextuellement pertinents plutôt que des correspondances exactes de mots-clés.
La mise en œuvre combine souvent des bases de données structurées pour les informations factuelles et des entrepôts vectoriels pour le rappel sémantique. Un agent du service clientèle peut interroger une base de données SQL pour obtenir les détails d'un compte tout en recherchant simultanément des enregistrements vectoriels pour des problèmes antérieurs similaires.
Persistance et récupération de l'état
Les systèmes de production ont besoin d'une persistance de l'état. Que se passe-t-il lorsqu'un agent tombe en panne à mi-chemin d'un processus de réservation à plusieurs étapes ? Sans une gestion adéquate des états, les utilisateurs recommencent à zéro. Avec une telle gestion, le système se rétablit et reprend.
Cela nécessite un suivi explicite de l'état, c'est-à-dire l'enregistrement des étapes qui se sont déroulées avec succès, des décisions prises par l'agent et de ce qu'il reste à faire. L'état peut persister dans des bases de données, des files d'attente de messages ou des cadres d'orchestration spécialisés.
Quand les agents sont excessifs
Voici ce que les documents marketing ne vous diront pas : les agents ne sont pas toujours la bonne architecture. De nombreux problèmes qui semblent nécessiter des agents fonctionnent en fait mieux avec des approches plus simples.
Si les flux de travail sont 80% prévisibles, le code déterministe est souvent plus performant que les agents autonomes. Un site web de planification de voyages qui doit vérifier la disponibilité, comparer les prix et réserver des billets n'a pas besoin d'une architecture d'agent. Il a besoin d'une intégration API bien conçue.
Les agents introduisent des frais généraux - coûts de calcul, temps de latence, imprévisibilité et complexité du débogage. Ces coûts sont justifiés lorsque les problèmes nécessitent réellement un raisonnement, une adaptation et une prise de décision autonome. Mais le fait d'imposer une architecture d'agents à des flux de travail simples crée une complexité inutile.
Appels directs sur le modèle et systèmes d'agents
Selon les directives d'architecture d'Azure, les appels de modèle directs suffisent pour la classification, le résumé et les transformations simples. Pas d'orchestration, pas d'outils, pas de gestion d'état. Il suffit de faire appel à l'ingénierie et à l'inférence de modèle.
Les architectures d'agents deviennent précieuses lorsque les tâches nécessitent des étapes multiples, la collecte d'informations externes ou des stratégies adaptatives basées sur des résultats intermédiaires. Le point de décision : pouvez-vous cartographier le flux de travail à l'avance ou l'agent doit-il le déterminer de manière dynamique ?
Intégration d'outils et conception d'API
Les outils étendent les capacités de l'agent au-delà de la génération de langage. Mais des interfaces d'outils mal conçues entraînent un comportement peu fiable, des appels de fonction infructueux et des sessions de débogage frustrantes.
Conception d'interfaces d'outils
Chaque outil a besoin de trois éléments : une description claire en langage naturel, des paramètres explicites avec des types et des contraintes, et une gestion robuste des erreurs. La description indique au LLM quand et pourquoi utiliser l'outil. Les paramètres définissent exactement les informations dont l'outil a besoin. La gestion des erreurs garantit une dégradation progressive lorsque les opérations échouent.
Les descriptions doivent être concises mais précises. Au lieu de “recherche dans la base de données”, écrivez “recherche dans les dossiers des clients par adresse électronique ou numéro de téléphone, en renvoyant les détails du compte et l'historique des achats”. La spécificité aide les modèles à choisir les outils appropriés.
Protocoles d'appel de fonction
Les LLM modernes prennent en charge l'appel de fonctions structurées, générant du JSON qui spécifie l'invocation de l'outil plutôt que du langage naturel. Cela réduit les erreurs d'analyse et rend l'utilisation des outils plus fiable.
Mais l'appel d'une fonction nécessite des schémas bien définis. Les paramètres doivent avoir des types clairs, des valeurs par défaut et des règles de validation. Les paramètres facultatifs ou obligatoires doivent être explicites. Les interfaces ambiguës conduisent à des paramètres hallucinés et à des appels qui échouent.
Considérations relatives au déploiement en production
Faire fonctionner des agents en développement diffère considérablement de les faire fonctionner de manière fiable en production. Selon l'initiative de normalisation des agents d'IA du NIST annoncée le 17 février 2026, la normalisation des pratiques de déploiement des agents est importante pour la sécurité, l'interopérabilité et la fiabilité.
Contrôle et observabilité
La surveillance traditionnelle des applications ne permet pas de saisir ce qui est important pour les agents. Les équipes ont besoin de visibilité sur les étapes de raisonnement, les invocations d'outils, les transitions d'état et les chemins de décision, et pas seulement sur les taux de latence et d'erreur.
L'enregistrement de chaque interaction LLM permet de déboguer les comportements inattendus. Le suivi des outils appelés révèle les schémas d'utilisation. L'enregistrement des transitions d'état montre où les flux de travail s'interrompent.
Sécurité et garde-corps
Les systèmes autonomes ont besoin de contraintes. Les garde-fous empêchent les agents de prendre des mesures préjudiciables, d'outrepasser leur autorité ou de prendre des décisions irréversibles sans confirmation.
Il peut s'agir de flux d'approbation pour les actions à fort enjeu, de limites de dépenses pour les agents ayant un accès API, ou de filtrage de contenu pour les systèmes en contact avec les clients. Le cadre de gestion des risques liés à l'IA du NIST fournit des conseils sur la construction de systèmes d'IA dignes de confiance avec des mesures de protection appropriées.
Gestion des coûts
Les appels à l'API LLM ne sont pas gratuits. Les agents qui effectuent des dizaines d'étapes de raisonnement par tâche peuvent générer des coûts importants. Les déploiements en production nécessitent un suivi des coûts, des alertes budgétaires et des stratégies d'optimisation.
La mise en cache des requêtes répétées, l'utilisation de modèles plus petits pour les décisions simples et la mise en œuvre d'une limitation des taux permettent de contrôler les dépenses sans sacrifier les capacités.

Modèles d'entreprise multi-agents
Les déploiements en entreprise sont confrontés à des défis uniques : l'intégration des systèmes existants, les exigences de conformité, les exigences d'échelle et la complexité organisationnelle. La recherche sur les systèmes de contrôle multi-agents met en évidence la façon dont les choix architecturaux se répercutent sur les structures organisationnelles.
Architecture en nuage pour les systèmes d'agents
L'infrastructure cloud offre l'évolutivité dont les agents ont besoin. Cloud Run, Lambda et d'autres plateformes similaires sans serveur gèrent des charges de travail variables sans mise à l'échelle manuelle. Mais les agents introduisent des exigences d'état qui compliquent le déploiement sans serveur.
Les approches hybrides fonctionnent bien : des fonctions sans serveur pour les étapes de raisonnement sans état, des bases de données gérées pour la persistance de l'état et des files de messages pour l'orchestration. Cela permet de séparer les préoccupations et de faire évoluer chaque composant de manière indépendante.
Sécurité et conformité
Les systèmes autonomes qui accèdent à des données sensibles ou prennent des décisions importantes ont besoin d'une sécurité solide. Cela comprend l'authentification pour l'accès aux outils, l'autorisation pour les actions des agents, l'enregistrement des audits et la protection des données.
Les considérations de sécurité dans les systèmes d'agents d'IA devraient être intégrées dans la conception du système plutôt que d'être ajoutées après coup. Les jetons d'authentification expirent, les autorisations suivent les principes du moindre privilège et les données sensibles n'apparaissent jamais dans des journaux non chiffrés.
Intégration avec les systèmes existants
Les entreprises prennent rarement un nouveau départ. Les architectures d'agents doivent s'intégrer à des décennies de systèmes hérités, chacun avec ses propres API, formats de données et bizarreries.
Les modèles d'adaptateurs aident à construire des couches de traduction qui font le lien entre les attentes des agents et les réalités des systèmes existants. Cela permet d'isoler la complexité et de laisser la logique de l'agent propre tandis que les adaptateurs gèrent les détails d'intégration gênants.
Cadre décisionnel architectural
Pour choisir la bonne architecture d'agent, il faut évaluer les compromis entre plusieurs dimensions. Voici un cadre permettant de prendre des décisions en connaissance de cause :
Évaluation de la complexité
Commencez par évaluer honnêtement la complexité des tâches. Les flux de travail peuvent-ils être cartographiés à l'avance ? Les tâches nécessitent-elles un raisonnement et une adaptation ? Des approches plus simples seraient-elles efficaces ?
Si 80% des cas suivent des chemins prévisibles, il convient d'envisager des systèmes déterministes avec des agents de secours pour les cas marginaux. L'architecture complète d'agents se justifie lorsque la variété des tâches dépasse ce que la logique prédéterminée peut gérer.
Exigences de fiabilité
Quelle est l'importance d'un comportement cohérent ? Les agents du service clientèle ont besoin d'une grande fiabilité - les réponses imprévisibles nuisent à la confiance. Les agents de recherche qui explorent de nouvelles stratégies tolèrent une plus grande variabilité.
Les exigences de fiabilité plus élevées favorisent des modèles d'orchestration plus simples, des tests approfondis et des garde-fous solides. Les scénarios à enjeux moindres permettent des architectures plus expérimentales.
Contraintes de latence
Les interactions en temps réel exigent une réponse rapide. Les processus de raisonnement en plusieurs étapes introduisent un temps de latence. Si les utilisateurs attendent des réponses en moins d'une seconde, les architectures d'agents complexes risquent de ne pas convenir.
Les applications sensibles aux temps de latence bénéficient d'une orchestration simultanée, de modèles plus petits pour des décisions rapides et d'une mise en cache agressive. Les flux de travail par lots tolèrent des raisonnements plus élaborés.
Projections d'échelle
Combien d'utilisateurs simultanés le système prendra-t-il en charge ? Les architectures à agent unique créent des goulets d'étranglement à grande échelle. Les systèmes multi-agents répartissent la charge mais introduisent des frais généraux de coordination.
Les déploiements à grande échelle favorisent les composants sans état, la mise à l'échelle horizontale et le traitement asynchrone. Les outils internes à petite échelle peuvent utiliser des architectures plus simples.
Transformez votre architecture d'IA en un système opérationnel
Un diagramme d'architecture montre comment les agents d'intelligence artificielle, les services et les flux de données doivent être connectés. Le défi commence généralement après cela : intégrer les composants, mettre en place une logique de backend stable et s'assurer que tout fonctionne de manière fiable dans un environnement réel. C'est là que de nombreuses équipes ralentissent, en particulier lorsque les ressources internes sont limitées ou concentrées sur d'autres priorités.
A-listware soutient cette étape du point de vue de l'ingénierie. L'entreprise met à disposition des équipes de développement dédiées qui gèrent les systèmes dorsaux, les intégrations, les API et l'infrastructure autour des solutions basées sur l'IA. L'accent n'est pas mis sur la création d'agents d'IA eux-mêmes, mais sur la garantie que le système environnant fonctionne comme prévu et évolue sans correctifs constants.
Si votre architecture est déjà définie mais pas encore mise en œuvre, c'est le moment de faire appel à une capacité d'ingénierie supplémentaire. Contact Logiciel de liste A pour soutenir le développement, l'intégration et le déploiement de votre système.
Questions fréquemment posées
- Quelle est la différence entre l'architecture des agents et l'architecture logicielle traditionnelle ?
Les logiciels traditionnels suivent des chemins logiques prédéterminés - pour une entrée X, exécuter les étapes A, B, C. Les architectures d'agents introduisent une prise de décision autonome. Le système détermine sa propre séquence d'actions en fonction des objectifs et du retour d'information sur l'environnement. Cela nécessite des composants pour le raisonnement, la gestion des états et l'orchestration des outils qui n'existent pas dans les architectures conventionnelles.
- Ai-je besoin de plusieurs agents ou un seul suffit-il ?
Les agents uniques fonctionnent bien pour les tâches ciblées dans un domaine. Les agents multiples sont utiles lorsque les problèmes se décomposent naturellement en spécialisations distinctes, qu'ils nécessitent un traitement parallèle ou qu'ils bénéficient de diverses approches de raisonnement. La plupart des équipes commencent par des systèmes à agent unique et n'introduisent des agents multiples que lorsque la complexité ou l'échelle l'exigent.
- Quel modèle d'orchestration dois-je choisir ?
L'orchestration séquentielle fonctionne pour les flux de travail prévisibles avec des dépendances d'étapes claires. Les modèles simultanés réduisent la latence lorsque les opérations sont indépendantes. Le chat de groupe excelle pour les problèmes complexes sans solution évidente. Choisissez selon que votre flux de travail est prédéterminé (séquentiel), parallélisable (concurrent) ou exploratoire (discussion de groupe).
- Comment gérer les défaillances des agents en production ?
Mettre en œuvre la persistance de l'état afin que les agents puissent reprendre leur activité après une défaillance. Utiliser une logique de réessai avec un backoff exponentiel pour les erreurs transitoires. Concevoir une dégradation progressive : si l'agent ne peut pas accomplir une tâche de manière autonome, faire appel à des opérateurs humains plutôt que d'échouer silencieusement. Surveiller les transitions d'état pour détecter les endroits où les défaillances sont les plus fréquentes.
- Quel est le rôle des bases de données vectorielles dans l'architecture des agents ?
Les bases de données vectorielles permettent une mémoire sémantique - les agents récupèrent des informations contextuelles pertinentes plutôt que des correspondances exactes de mots-clés. Cela favorise la mémoire à long terme entre les sessions, les flux de travail de génération augmentés par la récupération et la recherche de cas antérieurs similaires. Tous les agents n'ont pas besoin d'un stockage vectoriel, mais ceux qui ont besoin d'un rappel de connaissances approfondi en tirent un avantage considérable.
- Comment empêcher les agents de prendre des mesures préjudiciables ?
Mettre en place des garde-fous à plusieurs niveaux. Limiter les outils auxquels les agents peuvent accéder. Exiger des processus d'approbation pour les actions à fort enjeu. Fixer des limites de dépenses pour les agents ayant un accès financier. Filtrer les sorties pour détecter les contenus inappropriés. Concevoir des dispositifs de sécurité qui empêchent les actions irréversibles. Les cadres de gestion des risques liés à l'IA fournissent des conseils sur la mise en place de mesures de protection appropriées.
- Dois-je créer l'infrastructure de l'agent à partir de zéro ou utiliser un cadre ?
Des cadres tels que LangChain, AutoGen et Semantic Kernel fournissent des primitives d'orchestration, des modèles d'intégration d'outils et des utilitaires de gestion d'état. Ils accélèrent le développement mais introduisent des dépendances et des opinions. Construire à partir de zéro offre un contrôle mais demande plus d'efforts d'ingénierie. Pour la plupart des équipes, les cadres fournissent un point de départ raisonnable avec la possibilité de remplacer des composants ultérieurement.
Conclusion : Construire des systèmes d'agents fiables
L'architecture des agents d'IA détermine si les systèmes autonomes sont fiables ou s'ils échouent de manière imprévisible. Le modèle à quatre niveaux - base de raisonnement, logique d'orchestration, infrastructure de données et intégration d'outils - fournit une structure éprouvée pour la construction de systèmes de production.
Les choix architecturaux se répercutent sur tous les aspects du comportement du système. L'orchestration séquentielle ou concurrente affecte la latence. Les approches de gestion des états déterminent les capacités de récupération. Les conceptions multi-agents ou mono-agents ont un impact sur les caractéristiques d'échelle.
Mais l'architecture seule ne garantit pas le succès. Les agents prêts pour la production nécessitent une surveillance, des garde-fous, une gestion des coûts et une sécurité. Selon l'initiative de normalisation des agents d'IA du NIST, la normalisation de ces pratiques permettra une adoption plus large avec des garanties appropriées.
Commencer par l'architecture la plus simple qui réponde aux besoins. N'ajoutez de la complexité que lorsque les approches les plus simples s'avèrent insuffisantes. Effectuer des tests approfondis avec des charges de travail réalistes avant de procéder au déploiement de la production. Surveiller de près le comportement des agents dans les premières versions.
La recherche est claire : la fiabilité découle de choix architecturaux réfléchis, et pas seulement de l'utilisation des modèles les plus récents. Les équipes qui investissent dans une architecture solide, un outillage approprié et une gestion robuste des états construisent des agents qui fonctionnent réellement lorsqu'ils sont déployés.
Prêt à mettre en œuvre ces modèles ? Commencez par mettre en correspondance votre cas d'utilisation spécifique avec les modèles d'orchestration et les couches architecturales décrits ici. Faites un prototype avec un système à agent unique, validez le comportement, puis augmentez la complexité en fonction des besoins.


