Es gibt keinen Mangel an PHP-Entwicklern in Indien, und genau das ist das Problem. Auf dem Papier kann fast jedes Unternehmen eine Website oder eine App erstellen, aber sobald es um Zeitpläne, Kommunikation und laufenden Support geht, werden die Unterschiede deutlich. Manche Teams arbeiten schnell, sparen aber an der falschen Stelle. Andere sind technisch solide, aber schwer zu koordinieren, wenn das Projekt wächst.
Im Laufe der Zeit kommt es nicht nur darauf an, wie gut sie den Code schreiben, sondern auch darauf, wie sie mit allem umgehen, was damit zusammenhängt - mit Aktualisierungen, Fehlern, kleinen Änderungen, die nicht zum Umfang gehörten, und mit den Momenten, in denen etwas nicht wie geplant läuft. Die Unternehmen in diesem Bereich gehen sehr unterschiedlich damit um. Einige integrieren sich eng in Ihr Team, andere bleiben unabhängiger, aber die besseren haben in der Regel eines gemeinsam: Sie sorgen dafür, dass sich die Arbeit überschaubar und nicht schwer anfühlt.

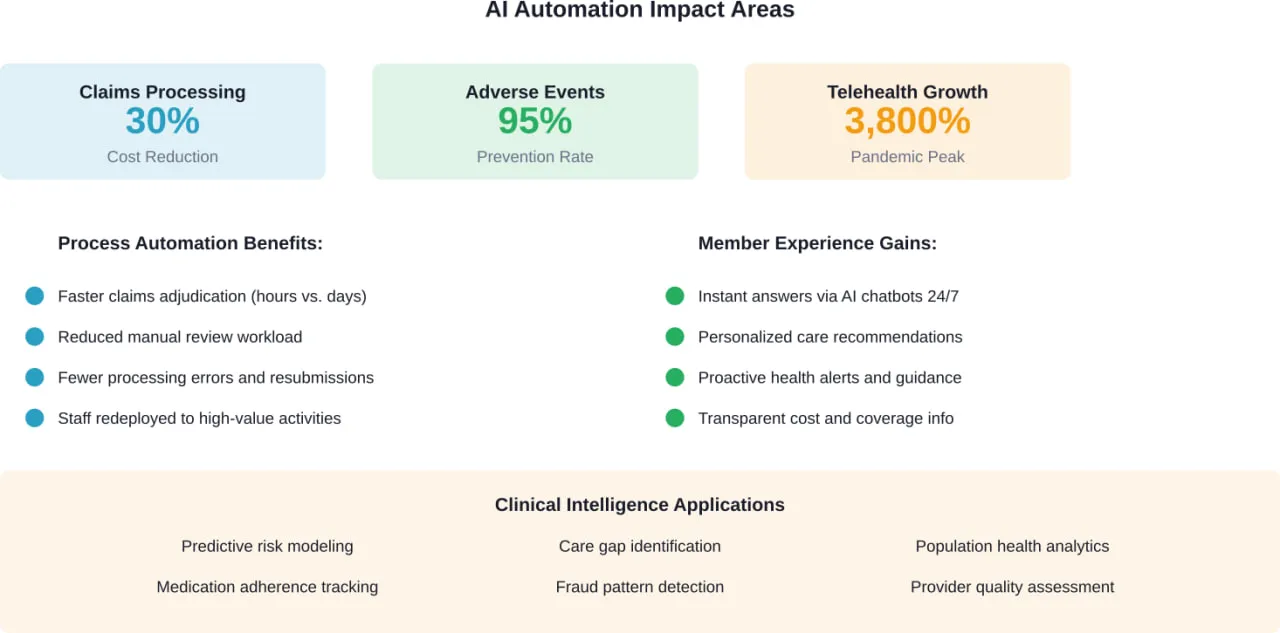
1. A-Listware
Bei A-listware betrachten wir die PHP-Webentwicklung als Teil eines umfassenderen Systems. Wir arbeiten an Webportalen, Unternehmenswebsites und Webanwendungen, die oft mit bestehenden Tools oder internen Systemen verbunden werden müssen. In der Praxis bedeutet das in der Regel, sich mit Dingen wie Datenflüssen, Benutzerrollen und Integrationen zu beschäftigen, die nicht immer auf Anhieb perfekt funktionieren. Wir bieten unsere Dienstleistungen in Indien an und unterstützen Unternehmen, die sowohl die Erstentwicklung als auch laufende Anpassungen nach der Einführung benötigen.
Unsere Arbeit wird in der Regel dadurch bestimmt, wie wir den Prozess der Entwicklung steuern. Wir verbringen viel Zeit mit dem Scoping und der Kommunikation in der Anfangsphase, vor allem um zu vermeiden, dass sich die Erwartungen auf halbem Wege des Projekts verschieben. Manche Kunden kommen mit einer klaren Vorstellung zu uns, andere mit einer eher vagen, und wir mussten uns an beide anpassen. Wir bleiben auch nach der Auslieferung involviert - nicht in großem Umfang, aber genug, um Aktualisierungen, Korrekturen oder kleine Änderungen vorzunehmen, die sich natürlich ergeben, sobald das System in Betrieb ist.
Wichtigste Highlights:
- Arbeit an Webportalen für Kunden, Partner und interne Teams
- Erfahrung mit der Erstellung einfacher Websites und komplexerer Webanwendungen
- Einbindung in den gesamten Entwicklungszyklus, von der Analyse bis zum Support
- Flexibler Kommunikationsaufbau je nach Projektgröße und -struktur
Dienstleistungen:
- PHP-Webentwicklung
- Entwicklung von Webanwendungen
- Entwicklung von Webportalen
- Entwicklung des elektronischen Geschäftsverkehrs
- Backend-Entwicklung und -Integrationen
- UI- und UX-Design
- Prüfung und QA
- Laufende Unterstützung und Wartung
Kontaktinformationen:
- Website: a-listware.com
- E-Mail: info@a-listware.com
- Facebook: www.facebook.com/alistware
- LinkedIn: www.linkedin.com/company/a-listware
- Anschrift: North Bergen, NJ 07047, USA
- Telefon: +1 (888) 337 93 73

2. SunTec Indien
SunTec India arbeitet mit einer Mischung aus PHP-Webentwicklung und umfassenderen digitalen Ingenieurdienstleistungen, und diese Mischung zeigt sich in der Art und Weise, wie sie an Projekte herangehen. Sie konzentrieren sich nicht nur auf die Entwicklung einer einzelnen Anwendung - ihre Arbeit umfasst oft CMS-Plattformen, APIs und Integrationen, die über verschiedene Systeme hinweg funktionieren müssen. SunTec India neigt dazu, sowohl mit geschäftsorientierten Plattformen als auch mit internen Tools zu arbeiten, bei denen Datenverarbeitung und -struktur ebenso wichtig sind wie die Schnittstelle.
Eine Sache, die auffällt, ist, wie viel von ihrer PHP-Arbeit mit laufenden Änderungen und nicht mit einmaligen Builds zu tun hat. Sie erwähnen recht häufig Re-Engineering, Migration und die Entwicklung von Erweiterungen, was darauf hindeutet, dass sie sich mit bereits bestehenden Projekten beschäftigen, die Anpassungen benötigen, anstatt jedes Mal bei Null anzufangen. In der Praxis bedeutet das in der Regel, älteren Code zu reparieren, sich an neue Frameworks anzupassen oder neue Funktionen hinzuzufügen, ohne das Bestehende zu zerstören - was sich einfach anhört, es aber selten ist.
Wichtigste Highlights:
- Arbeit mit PHP-Webanwendungen, CMS und Unternehmensplattformen
- Erfahrung mit der Migration und dem Re-Engineering von bestehenden Systemen
- Beteiligung an der API-Entwicklung und der Integration mehrerer Systeme
- Schwerpunkt auf der Aufrechterhaltung der plattformübergreifenden Kompatibilität
Dienstleistungen:
- PHP-Webentwicklung
- API-Entwicklung und -Integration
- Re-Engineering von PHP-Anwendungen
- Migration und Portierung
- Unterstützung und Wartung
Kontaktinformationen:
- Website: www.suntecindia.com
- E-Mail: info@suntecindia.com
- Facebook: www.facebook.com/SuntecIndia
- Twitter: x.com/SuntecIndia
- LinkedIn: www.linkedin.com/company/suntecindia
- Instagram: www.instagram.com/suntec_india
- Adresse: Floor 3, Vardhman Times Plaza Plot 13, DDA Community Centre Road 44, Pitampura New Delhi - 110 034
- Telefon: +91 11 4264 4425

3. Binstellar
Binstellar konzentriert sich auf die PHP-Entwicklung, wobei der Schwerpunkt darauf liegt, wie sich Systeme unter realen Nutzungsbedingungen verhalten. Ihre Arbeit bezieht sich oft auf Plattformen, die wechselnde Belastungen bewältigen müssen - zum Beispiel E-Commerce-Systeme bei Spitzenbelastungen oder inhaltsintensive Anwendungen, die mit der Zeit wachsen. Ihr Ansatz zielt darauf ab, Lösungen zu entwickeln, die angepasst werden können, ohne dass sie später komplett neu erstellt werden müssen.
Anstatt die Dinge allgemein zu halten, scheint Binstellar die Entwicklung eng an branchenspezifische Anwendungsfälle zu binden. Sie sprechen von Bildungsplattformen, Immobiliensystemen und Fertigungswerkzeugen, was darauf hindeutet, dass sie die Struktur der Anwendung an die tatsächliche Nutzung anpassen. In der Praxis bedeutet das oft, dass man sich mit Details wie dem Filtern großer Datensätze, dem Verwalten von Inhaltsflüssen oder dem Sicherstellen, dass die Schnittstellen für nicht-technische Benutzer sinnvoll sind, befassen muss - Dinge, die nicht immer in einer Funktionsliste auftauchen, aber das Endergebnis beeinflussen.
Wichtigste Highlights:
- Arbeit an branchenspezifischen PHP-Anwendungen in verschiedenen Sektoren
- Verwendung von Frameworks wie Laravel und CodeIgniter bei der Entwicklung
- Schwerpunkt auf Skalierbarkeit und Handhabung unterschiedlicher Verkehrslasten
Dienstleistungen:
- Entwicklung kundenspezifischer PHP-Webanwendungen
- PHP CMS-Entwicklung
- CRM- und ERP-Entwicklung
- PHP-API-Entwicklung und -Integration
- Migration und Aktualisierung bestehender Anwendungen
- Backend-Entwicklung für mobile Anwendungen
Kontaktinformationen:
- Website: www.binstellar.com
- E-Mail: hello@binstellar.com
- Facebook: www.facebook.com/BinStellarTechnologies
- Twitter: x.com/binstellartech
- LinkedIn: www.linkedin.com/company/binstellar-technologies-pvt-ltd
- Instagram: www.instagram.com/lifeatbinstellar
- Adresse: D-402 Ganesh Meridian, gegenüber Kargil Petrol Pump, Sarkhej - Gandhinagar Hwy, Sola, Ahmedabad, Gujarat 380061
- Telefon: +91 8866-8877-26

4. N-iX
N-iX betrachtet die PHP-Entwicklung als Teil einer größeren technischen Einrichtung und nicht als separate Dienstleistung. Sie arbeiten an Backend-Systemen, Anwendungsarchitekturen und Integrationen, oft in Umgebungen, in denen PHP nur ein Teil eines breiteren Stacks ist. N-iX bietet seine Dienstleistungen nicht nur in Indien, sondern auch in anderen Regionen an, was ein verteiltes Liefermodell ermöglicht, das für Unternehmen, die Projekte über Zeitzonen hinweg durchführen, nützlich sein kann.
Ihre Arbeit umfasst in der Regel sowohl den Aufbau neuer Systeme als auch die Anpassung älterer Systeme. Ein deutlicher Schwerpunkt liegt auf der Modernisierung und Leistungsoptimierung, die in der Regel dann zum Tragen kommt, wenn die Anwendungen schon eine Weile laufen und erste Einschränkungen aufweisen. N-iX arbeitet oft an der Umstrukturierung von Teilen des Systems, der Verbesserung von APIs oder der Anpassung der Architektur, damit sich die Anwendung ohne ständige Neuschreibungen weiterentwickeln kann.
Wichtigste Highlights:
- Arbeit an Backend-Systemen und Anwendungsarchitekturen mit PHP
- Erfahrung mit der Modernisierung von PHP-Altanwendungen
- Mitwirkung an der API-Entwicklung und Systemintegrationen
- Flexible Kooperationsmodelle einschließlich Teamerweiterung
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- PHP-Beratung
- Modernisierung von Anwendungen
- CMS- und CRM-Entwicklung
Kontaktinformationen:
- Website: www.n-ix.com
- E-Mail: contact@n-ix.com
- Facebook: www.facebook.com/N.iX.Company
- Twitter: x.com/N_iX_Global
- LinkedIn: www.linkedin.com/company/n-ix
- Adresse: No.121, Estate Building 7th Floor, Dickenson Road Yellappa Garden, Bangalore, Indien
- Telefon: +17273415669

5. OrangeMantra
OrangeMantra arbeitet mit PHP als Teil einer breiteren Entwicklungsumgebung, die Webplattformen, Unternehmenstools und kundenorientierte Systeme umfasst. Ihre Projekte liegen oft irgendwo zwischen Standard-Websites und stärker strukturierten Geschäftsanwendungen, bei denen Workflows, Berechtigungen und Integrationen ebenso wichtig sind wie die Benutzeroberfläche. OrangeMantra ist an der Entwicklung von Systemen beteiligt, die den laufenden Geschäftsbetrieb unterstützen und nicht nur einmalig eingeführt werden.
Ihre PHP-Arbeit ist in der Regel mit größeren digitalen Initiativen verbunden, so dass es nicht ungewöhnlich ist, dass sich eine einfache Anfrage im Laufe der Zeit zu etwas vielschichtigerem entwickelt. Zum Beispiel könnte ein einfaches Portal später die Integration mit internen Systemen oder zusätzlichen Benutzerrollen erfordern. OrangeMantra neigt dazu, die Architektur so flexibel zu halten, dass sie erweitert werden kann, ohne dass ein kompletter Neuaufbau erforderlich ist, was oft der Punkt ist, an dem Projekte anfangen, kompliziert zu werden.
Wichtigste Highlights:
- Arbeit an PHP-basierten Webplattformen und Geschäftsanwendungen
- Erfahrung mit Systemen, die Integrationen und rollenbasierten Zugang erfordern
- Beteiligung an Projekten, die sich über den ursprünglichen Rahmen hinaus entwickeln
- Schwerpunkt auf der Erhaltung einer anpassungsfähigen Architektur
Dienstleistungen:
- PHP-Webentwicklung
- Entwicklung kundenspezifischer Webanwendungen
- Entwicklung von Unternehmensanwendungen
- API-Entwicklung und -Integration
Kontaktinformationen:
- Website: www.orangemantra.com
- E-Mail: contact@orangemantra.com
- Facebook: www.facebook.com/OrangeMantraIndia
- Twitter: x.com/OrangeMantraggn
- LinkedIn: in.linkedin.com/Unternehmen/orangemantra
- Instagram: www.instagram.com/orange_mantra
- Adresse: Einheit Nr. 650, 6. Stock, Turm A, Spaze iTech Park, Sohna - Gurgaon Rd, Block S, Sektor 49, Gurugram, Haryana 122018
- Telefon: +919870289050

6. Vofox Lösungen
Vofox Solutions konzentriert sich auf PHP-Entwicklung neben einem breiteren Mix von Web- und Software-Dienstleistungen. Ihre Arbeit reicht von kleineren Websites bis hin zu komplexeren Webanwendungen und Portalen, die oft mit Frameworks wie Laravel oder CodeIgniter entwickelt werden. Vofox Solutions kümmert sich auch um Offshore-Entwicklungen, was bedeutet, dass ein Teil ihrer Arbeit die Koordination von Teams und die Verwaltung der Lieferung über verschiedene Standorte hinweg umfasst, nicht nur das Schreiben von Code.
Ein erheblicher Teil ihrer PHP-Arbeit ist mit laufenden Aktualisierungen und Änderungen verbunden. Sie heben Migration, Upgrades und Wartung besonders hervor, was in der Regel auf Projekte hinweist, die schon eine Weile laufen und eher angepasst als ersetzt werden müssen. In der Praxis kann das bedeuten, dass die Leistung verbessert, Frameworks aktualisiert oder Teile des Systems repariert werden, die nicht mehr den aktuellen Anforderungen entsprechen.
Wichtigste Highlights:
- Arbeit mit PHP-Frameworks wie Laravel, CodeIgniter und Symfony
- Erfahrung mit neuen Builds und Upgrades bestehender Anwendungen
- Beteiligung an Offshore-Entwicklung und verteilten Teams
- Schwerpunkt auf Tests und Qualitätsprüfungen während der gesamten Entwicklung
Dienstleistungen:
- Entwicklung von PHP-Webanwendungen
- Entwicklung des elektronischen Geschäftsverkehrs
- API-Entwicklung und -Integration
- PHP-Migration und -Upgrades
- CMS-Entwicklung
Kontaktinformationen:
- Website: vofoxsolutions.com
- E-Mail: info@vofoxsolutions.com
- Facebook: www.facebook.com/vofox
- Twitter: x.com/VofoxS
- LinkedIn: www.linkedin.com/company/vofox-solutions-pvt-ltd
- Anschrift: VIP Road, JLN Stadium Metro Station, Kaloor, Kochi- 682017 Kerala, Indien
- Telefon: +91-484-4049006

7. Pixlogix
Pixlogix arbeitet an PHP-Projekten, die oft eng mit Websites, E-Commerce-Plattformen und inhaltsgesteuerten Systemen verbunden sind. Die Arbeit von Pixlogix konzentriert sich auf die Entwicklung von Anwendungen, die regelmäßig aktualisiert werden müssen, weshalb CMS-Entwicklung und -Integrationen häufig zu den Dienstleistungen des Unternehmens gehören. Pixlogix arbeitet auch mit verschiedenen PHP-Frameworks und passt die Struktur je nach Projekt an, anstatt sich auf einen einzigen Ansatz festzulegen.
Ein weiterer Schwerpunkt ist das Verhalten der Projekte nach dem Start. Pixlogix kümmert sich um Dinge wie Leistungsoptimierung, Versionskontrolle und fortlaufende Wartung, die in der Regel wichtig wird, wenn der Datenverkehr zunimmt oder neue Funktionen hinzugefügt werden. Bei kleineren Projekten kann das einfache Updates bedeuten.
Wichtigste Highlights:
- Arbeit an PHP-basierten Websites, CMS-Plattformen und E-Commerce-Systemen
- Erfahrung mit Frameworks wie Laravel, Symfony und CodeIgniter
- Beteiligung an der Entwicklung und an Verbesserungen nach der Markteinführung
Dienstleistungen:
- Kundenspezifische PHP-Webentwicklung
- PHP-Website-Entwicklung
- CMS-Entwicklung
- Entwicklung des elektronischen Geschäftsverkehrs
- API-Entwicklung und -Integrationen
- PHP-Migration und -Upgrades
- Wartung und Unterstützung
Kontaktinformationen:
- Website: www.pixlogix.com
- E-Mail: info@pixlogix.com
- Facebook: www.facebook.com/pixlogix
- Twitter: x.com/pixlogix
- LinkedIn: www.linkedin.com/company/pixlogix
- Instagram: www.instagram.com/pixlogix
- Anschrift: 704, Zion Z1, Nr. Avalon Hotel, Sindhu Bhavan Road, Bodakdev, Ahmedabad, Gujarat 380054, Indien
- Telefon: +91 7778865391

8. Dynamische Dreamz
Dynamic Dreamz arbeitet hauptsächlich mit PHP und MySQL, und ihre Projekte bleiben oft nah an praktischen Anwendungsfällen wie E-Commerce-Shops, CMS-basierten Websites und benutzerdefinierten Webanwendungen. Ein Großteil ihrer Arbeit ist an Plattformen wie Laravel, Craft CMS und Prestashop gebunden, was darauf hindeutet, dass sie sich auf den Aufbau von Systemen konzentrieren, die Kunden später ohne allzu große Reibung verwalten und erweitern können. Dynamic Dreamz wickelt sowohl eigenständige Projekte als auch White-Label-Arbeiten ab, so dass einiges von dem, was sie bauen, am Ende unter dem Namen eines anderen Unternehmens geliefert wird.
Ihr Entwicklungsprozess ist ziemlich unkompliziert - Planung, Aufbau, Tests und dann die Beteiligung nach dem Start. Besonders hervorzuheben ist der Umfang des laufenden Supports, insbesondere für CMS- und E-Commerce-Systeme, bei denen im Laufe der Zeit immer wieder kleine Probleme auftreten. Das kann bedeuten, einen Plugin-Konflikt zu beheben, ein Modul zu aktualisieren oder das Verhalten einer API anzupassen, wenn sich etwas Externes ändert.
Wichtigste Highlights:
- Arbeit mit PHP und MySQL für Webanwendungen
- Erfahrung mit Laravel, Craft CMS und Prestashop
- Mitwirkung an White-Label-Entwicklungsprojekten
- Schwerpunkt auf der Wartung von CMS- und E-Commerce-Plattformen
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Entwicklung von Laravel-Anwendungen
- API-Entwicklung und -Integration
- CMS-Entwicklung
- Entwicklung des elektronischen Geschäftsverkehrs
- Plugin- und Modulentwicklung
Kontaktinformationen:
- Website: www.dynamicdreamz.com
- E-Mail: info@dynamicdreamz.com
- LinkedIn: www.linkedin.com/company/dynamic-dreamz-websolutions
- Instagram: www.instagram.com/dynamicdreamz_surat
- Anschrift: Balaji House, Chamunda Restaurant Lane, Opp. Sub Jail, Near Udhna Darwaja, Surat, Gujarat 395002, Indien
- Telefon: +91 9327642007

9. Clarion Technologien
Clarion Technologies betrachtet die PHP-Entwicklung nicht als isoliertes Projekt, sondern als Teil eines ausgelagerten Ingenieurteams. Ihre Arbeit umfasst oft den Aufbau oder die Erweiterung von Teams, die Webanwendungen, CRM-Systeme und interne Plattformen über einen längeren Zeitraum betreuen. Clarion Technologies konzentriert sich nicht nur auf die Lieferung, sondern auch darauf, wie die Teams strukturiert und verwaltet werden, was sich in Projekten bemerkbar macht, die über Monate statt Wochen laufen.
Sie arbeiten auch viel mit bestehenden Systemen. Modernisierungen, Upgrades und Migrationen kommen häufig vor, was in der Regel bedeutet, dass man in Projekte einsteigt, die bereits eine gewisse Geschichte hinter sich haben. Bei der Arbeit geht es weniger darum, etwas Neues zu entwickeln, sondern vielmehr darum, die Stabilität zu verbessern, Frameworks zu aktualisieren oder dafür zu sorgen, dass das System künftige Änderungen ohne ständige Nacharbeit bewältigen kann.
Wichtigste Highlights:
- Arbeit durch engagierte Teams und langfristige Kooperationsmodelle
- Erfahrung mit der Modernisierung von bestehenden PHP-Anwendungen
- Verwendung von Frameworks wie Laravel, Symfony und CodeIgniter
- Fokus auf strukturierte Entwicklungsprozesse und Teamaufbau
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Full-Stack-Entwicklung
- API-Entwicklung und -Integration
- CMS- und Plattformentwicklung
- Anwendungsmigration und Upgrades
Kontaktinformationen:
- Website: www.clariontech.com
- E-Mail: info@clariontech.com
- Twitter: x.com/Clarion_Tech
- LinkedIn: in.linkedin.com/Unternehmen/clariontechnologies
- Instagram: www.instagram.com/clarion_technologies
- Adresse: The Hive, Raja Bahadur Mill Rd, Neben dem Sheraton Grand Hotel, Sangamvadi, Pune - 411001
- Telefon: +1 (888)-551-0371

10. IndienInternets
IndiaInternets konzentriert sich auf die PHP-Entwicklung mit einem Schwerpunkt auf Frameworks wie Laravel, CodeIgniter und Yii. Ihre Arbeit umfasst Webportale, CMS-Plattformen und E-Commerce-Lösungen, die oft sowohl mit Blick auf das Frontend als auch auf das Backend entwickelt werden. IndiaInternets verbringt auch Zeit mit der Auswahl des richtigen Frameworks für jedes Projekt, was einen Unterschied machen kann, wenn die Anforderungen zu Beginn nicht vollständig definiert sind.
Sie arbeiten seit langem mit PHP, und das zeigt sich darin, wie sie mit allgemeinen Problemen wie Fehlern, Leistung und Updates umgehen. Anstatt die Entwicklung als einmaligen Prozess zu betrachten, werden Support und Wartung als Teil des Arbeitsablaufs betrachtet.
Wichtigste Highlights:
- Arbeit mit mehreren PHP-Frameworks, darunter Laravel und CodeIgniter
- Erfahrung im Aufbau von Webportalen, CMS und E-Commerce-Systemen
- Beteiligung sowohl an der Entwicklung als auch an der Unterstützung nach der Markteinführung
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Entwicklung von Webanwendungen
- API-Entwicklung
- PHP-Anpassung
- Migration und Modernisierung
- Beratung
- Unterstützung und Wartung
Kontaktinformationen:
- Website: www.indiainternets.com
- E-Mail: sales@indiainternets.com
- Facebook: www.facebook.com/indiainternets
- LinkedIn: www.linkedin.com/company/alliance-web-solution-pvt-ltd
- Instagram: www.instagram.com/indiainternets
- Anschrift: Alliance Tower, 112, B Block Rd, B Block, Sector 64, Noida, Uttar Pradesh 201309, Indien
- Telefon: +91 956 043 3318

11. Vrinsoft
Vrinsoft konzentriert sich sehr darauf, PHP-Entwickler als Teil eines flexiblen Teams bereitzustellen, anstatt nur feste Projekte zu liefern. Ihre Arbeit umfasst Webanwendungen, Portale, CMS-Plattformen und API-basierte Systeme, die oft von speziellen oder erweiterten Teams entwickelt werden.
Sie scheinen auch gerne in verschiedenen Phasen eines Projekts zu arbeiten. Manche Kunden kommen mit frühen Ideen, andere mit bestehenden Systemen, die umstrukturiert oder skaliert werden müssen. Vrinsoft kümmert sich um beides, was in der Praxis bedeuten kann, dass in einem Fall etwas von Grund auf neu entwickelt und in einem anderen Fall ein älteres System überarbeitet wird.
Wichtigste Highlights:
- Arbeit durch engagierte Entwickler und flexible Einstellungsmodelle
- Erfahrung sowohl mit neuen Builds als auch mit Aktualisierungen von Altsystemen
- Mitwirkung an der API-Entwicklung und Systemintegrationen
- Fokus auf strukturierte Entwicklung und Codequalität
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Entwicklung von Webanwendungen
- CMS- und Portalentwicklung
Kontaktinformationen:
- Website: www.vrinsofts.com
- E-Mail: sales@vrinsofts.com
- Facebook: www.facebook.com/vrinsofts
- Twitter: x.com/Vrinsofts
- LinkedIn: www.linkedin.com/company/vrinsoft-technologies-pvt-ltd
- Instagram: www.instagram.com/vrinsofts
- Adresse: 707, Elite Business Park, AUDI showroom lane- Shapath Hexa, S G Highway, Ahmedabad - 380060, Gujarat, Indien
- Telefon: +91 7227 906118

12. mTouch Labs
mTouch Labs arbeitet mit PHP in einer strukturierten, prozessgesteuerten Weise und folgt einer klaren Abfolge von der Planung bis zum Support nach der Einführung. Zu ihren Projekten gehören in der Regel Unternehmenswebsites und Webanwendungen, bei denen Leistung und Benutzerfreundlichkeit in Einklang gebracht werden müssen. Sie setzen auf Frameworks wie Laravel und Symfony, was darauf schließen lässt, dass sie organisierte Architekturen bevorzugen.
Eine Sache, die auffällt, ist, wie sie die Arbeit nach dem Start als Teil desselben Zyklus behandeln und nicht als separate Phase. Das ist normalerweise wichtig, wenn sich Anwendungen weiterentwickeln - neue Funktionen, kleine Korrekturen oder Leistungsoptimierungen.
Wichtigste Highlights:
- Einsatz eines strukturierten Entwicklungsprozesses von der Planung bis zum Support
- Erfahrung mit Frameworks wie Laravel, Symfony und CodeIgniter
- Schwerpunkt auf Leistung, Tests und Benutzerfreundlichkeit
- Beteiligung an Aktualisierungen und Verbesserungen nach der Markteinführung
Dienstleistungen:
- PHP-Webentwicklung
- Entwicklung kundenspezifischer Webanwendungen
- UI- und UX-Design
- Prüfung und Optimierung
- Unterstützung bei der Bereitstellung und Einführung
- Laufende Wartung
Kontaktinformationen:
- Website: www.mtouchlabs.com
- E-Mail: contact@mtouchlabs.com
- Facebook: www.facebook.com/MTouchLabs
- Twitter: x.com/mtouchlabs
- LinkedIn: www.linkedin.com/company/mtouchlabs
- Instagram: www.instagram.com/mtouch_labs
- Adresse: Manjeera Trinity Corporate, 514, JNTU - Hitech City Rd, Kukatpally Housing Board Colony, K P H B Phase 3, Kukatpally, Hyderabad, Telangana 500072, Indien
- Telefon: +91 9390683154

13. MetaDesign Lösungen
MetaDesign Solutions arbeitet an der PHP-Entwicklung mit dem Schwerpunkt auf Webanwendungen, CMS-Plattformen und E-Commerce-Systemen. Ihre Arbeit neigt dazu, Backend-Funktionalität mit praktischen geschäftlichen Anwendungsfällen zu kombinieren, bei denen das System Inhalte, Transaktionen oder interne Arbeitsabläufe verarbeiten muss, ohne übermäßig komplex zu werden.
Ihr Ansatz scheint einem strukturierten Weg von der Planung bis zur Bereitstellung zu folgen, wobei auf die Codestruktur und die Wartbarkeit geachtet wird. Das wird oft später wichtig - wenn Teams Funktionen aktualisieren, neue Systeme verbinden oder die Anwendung skalieren müssen, ohne alles neu zu schreiben. MetaDesign Solutions scheint mit dieser längerfristigen Perspektive zu arbeiten, anstatt sich nur auf das erste Release zu konzentrieren.
Wichtigste Highlights:
- Arbeit an PHP-basierten Webanwendungen, CMS und e-Commerce-Plattformen
- Verwendung eines strukturierten Entwicklungsansatzes mit Schwerpunkt auf der Wartbarkeit
- Flexible Engagementmodelle je nach Projektumfang
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- CMS-Entwicklung
- Entwicklung des elektronischen Geschäftsverkehrs
- Entwicklung von Webanwendungen
- API-Einbindung
- Migration und Upgrades
Kontaktinformationen:
- Website: www.metadesignsolutions.com
- E-Mail: sales@metadesignsolutions.com
- LinkedIn: www.linkedin.com/company/metadesign-solutions
- Instagram: www.instagram.com/metadesign_solutions
- Anschrift: Parzelle 28, 29, Electronic City, Phase IV, Udyog Vihar, Sektor 18, Gurugram, Haryana 122001 Indien
- Telefon: +91-76-69-913462

14. Intellistall
Intellistall konzentriert sich bei seiner PHP-Arbeit auf die Entwicklung kompletter Websysteme und nicht nur auf eigenständige Websites. Ihre Projekte umfassen oft Anwendungen wie ERP-Systeme, CRMs und E-Commerce-Plattformen, was darauf hindeutet, dass sie an Lösungen arbeiten, die eng mit internen Geschäftsprozessen verbunden sind, und nicht nur an öffentlich zugänglichen Schnittstellen. Sie beziehen sich auch auf API-Entwicklung und Integrationen, was in der Regel bedeutet, dass ihre Projekte mit anderen Tools, Plattformen oder Diensten verbunden werden müssen.
Ein weiterer auffälliger Aspekt ist der Fokus auf neuere Ansätze wie Headless-CMS-Setups und serverlose Umgebungen. In der Praxis deutet dies auf Projekte hin, bei denen es auf Skalierbarkeit oder die Bereitstellung über mehrere Kanäle ankommt, z. B. wenn das gleiche Backend Web-, Mobil- oder Drittanbieter-Integrationen unterstützt. Daneben erwähnen sie strukturierte Architekturen und Sicherheitspraktiken, die typischerweise wichtig werden, wenn Systeme wachsen und im Laufe der Zeit gewartet werden müssen.
Wichtigste Highlights:
- Arbeit an ERP-, CRM- und e-Commerce-Systemen mit PHP
- Erfahrung mit API-Entwicklung und der Integration von Drittanbietern
- Nutzung moderner Ansätze wie Headless CMS und Serverless Setups
- Schwerpunkt auf skalierbarer Architektur und Sicherheitspraktiken
Dienstleistungen:
- Entwicklung kundenspezifischer PHP-Anwendungen
- Entwicklung des elektronischen Geschäftsverkehrs
- API-Entwicklung und -Integration
- Entwicklung von Webanwendungen
- CMS-Entwicklung
- Wartung und Unterstützung
Kontaktinformationen:
- Website: www.intellistall.com
- E-Mail: info@intellistall.com
- Facebook: www.facebook.com/intellistall.digitalmarketing
- Twitter: x.com/intellistall
- LinkedIn: www.linkedin.com/company/intellistall
- Instagram: www.instagram.com/intellistall
- Anschrift: SCO 84, 1st & 2nd Floor, Jagadhari Rd, angrenzend an Gagan Banquets, Ambala Cantt, Haryana 133001
- Telefon: +917494955535

15. AMITKK
AMITKK konzentriert sich auf die PHP-Entwicklung für Unternehmenswebsites und Webanwendungen, wobei die Entwicklung oft mit der Neugestaltung oder Verbesserung bestehender Plattformen kombiniert wird. Ihre Arbeit umfasst den Aufbau von benutzerdefinierten Anwendungen, CMS-basierten Websites und E-Commerce-Lösungen, wobei der Schwerpunkt auf der Anpassbarkeit der Projekte bei sich ändernden Anforderungen liegt.
Sie betonen auch die fortlaufende Einbindung durch Wartung, Tests und Aktualisierungen, was darauf hindeutet, dass sie mit den Kunden über die erste Einführung hinaus zusammenarbeiten. In vielen Fällen eignet sich diese Art der Einrichtung für Unternehmen, die erwarten, dass ihre Plattform im Laufe der Zeit immer wieder angepasst wird, sei es durch das Hinzufügen von Funktionen, die Verbesserung der Leistung oder die Anpassung an neue Anforderungen.
Wichtigste Highlights:
- Arbeit an neuen Entwicklungen und an der Umgestaltung bestehender Plattformen
- Erfahrung mit CMS-, CRM- und E-Commerce-Lösungen
- Schwerpunkt auf der Skalierbarkeit und Anpassungsfähigkeit von Webanwendungen
- Laufende Unterstützung, Tests und Aktualisierungen nach der Einführung
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Entwicklung von Webanwendungen
- API-Entwicklung und -Integration
- CMS-Entwicklung
- CRM- und Portalentwicklung
- Entwicklung des elektronischen Geschäftsverkehrs
- Migration und Upgrades
Kontaktinformationen:
- Website: www.amitkk.com
- E-Mail: amit@amitkk.com
- Facebook: www.facebook.com/Amitkk-110578507216727
- LinkedIn: www.linkedin.com/in/amitkhare588
- Instagram: www.instagram.com/_amitkk_
- Adresse: Zweiter Stock, 1172, Sektor-45, in der Nähe der DPS-Schule, Gurgaon, Haryana-122002
- Telefon: +91-9695 871 040

16. Webindia Meister
Webindia Master betrachtet die PHP-Entwicklung hauptsächlich aus der Perspektive des Aufbaus von Unternehmenswebsites und Webanwendungen, die flexibel und relativ einfach zu verwalten sein müssen. Ihre Arbeit umfasst eine Reihe von Projekten, darunter CMS-Plattformen, E-Commerce-Lösungen und kundenspezifische Webanwendungen, die oft auf unterschiedliche Unternehmensgrößen zugeschnitten sind.
Sie legen auch Wert auf Kompatibilität und plattformübergreifende Unterstützung, was in der Regel wichtig ist, wenn Projekte in verschiedenen Umgebungen laufen oder in gängige Systeme integriert werden müssen. Ihre Erfahrung mit Frameworks wie Laravel, CodeIgniter und Magento legt nahe, dass sie innerhalb etablierter Ökosysteme arbeiten, anstatt alles von Grund auf neu zu entwickeln.
Wichtigste Highlights:
- Arbeit an Websites, CMS-Plattformen und E-Commerce-Lösungen
- Erfahrung mit Frameworks wie Laravel, CodeIgniter und Magento
- Schwerpunkt auf der Kompatibilität zwischen verschiedenen Plattformen und Umgebungen
Dienstleistungen:
- Kundenspezifische PHP-Entwicklung
- Entwicklung von Webanwendungen
- CMS-Entwicklung
- Entwicklung des elektronischen Geschäftsverkehrs
- Design und Entwicklung von Websites
- Rahmenbasierte Entwicklung
Kontaktinformationen:
- Website: www.webindiamaster.com
- E-Mail: info@webindiamaster.com
- Facebook: www.facebook.com/Webindia.Master
- Twitter: x.com/webindiamaster
- LinkedIn: in.linkedin.com/Unternehmen/webindiamaster
- Instagram: www.instagram.com/webindia_master
- Adresse: 1201 Tower-S3, Cloud 9, Sector-1 Vaishali, Ghaziabad - 201010 Uttar Pradesh, Indien
- Telefon: +91 98712 82862
Schlussfolgerung
Wenn Sie sich diese PHP-Webentwicklungsunternehmen ansehen, liegen die Unterschiede nicht wirklich in der Sprache selbst - PHP ist nur die Basis. Was sie tatsächlich unterscheidet, ist die Art und Weise, wie sie an echte Projekte herangehen. Einige konzentrieren sich auf langfristige Systeme wie CRM oder interne Tools, andere eher auf E-Commerce oder schnelllebige Webplattformen. Und genau hier beginnt die Entscheidung in der Regel Sinn zu machen. Es geht weniger darum, das “beste” Unternehmen zu finden, sondern vielmehr darum, ein Unternehmen zu finden, das in der Art von Umgebung, mit der Sie zu tun haben, bereits funktioniert.
Es gibt auch etwas Bemerkenswertes: Viele dieser Teams bauen nicht mehr nur von Grund auf neu. Sie greifen in bestehende Systeme ein, bereinigen sie, erweitern sie oder modernisieren sie langsam, ohne dabei alles kaputt zu machen. Das ist oft die schwierigere Aufgabe. Wenn Sie also einen Partner auswählen, ist es hilfreich, über den technischen Stack hinauszuschauen und darauf zu achten, wie er mit Veränderungen, Wartung und Wachstum im Laufe der Zeit umgeht. Denn in den meisten Fällen beginnt die eigentliche Arbeit, nachdem die erste Version in Betrieb genommen wurde.