Quick Summary: AI agent architecture diagrams visualize the core components of autonomous AI systems: reasoning layers, orchestration patterns, state management, and tool integration. Modern agent architectures typically follow a four-layer model encompassing LLM reasoning, orchestration logic, data infrastructure, and external tool connections. Understanding these architectural patterns helps developers build reliable, scalable agent systems for production environments.
The architecture behind AI agents determines whether a system performs reliably in production or collapses under real-world complexity. Yet most architecture discussions online show simplified stack diagrams that bear little resemblance to what development teams actually implement.
This guide breaks down AI agent architecture using visual diagrams, proven patterns from academic research, and implementations from organizations like Microsoft and CSIRO. The focus? What actually works when building autonomous systems that reason, remember, and act.
Understanding AI Agent Architecture Fundamentals
An AI agent architecture defines how autonomous systems perceive their environment, make decisions, and execute actions. Unlike traditional software that follows predetermined paths, agent architectures must handle uncertainty and adapt to dynamic conditions.
According to research published in the Agent Design Pattern Catalogue by CSIRO (Data61), foundation model-enabled agents leverage reasoning and language processing capabilities to operate autonomously. These systems don’t just respond to queries—they proactively pursue goals.
Here’s what separates true agent architectures from simple chatbots: agents maintain state across interactions, use tools to extend their capabilities, and employ reasoning strategies to break down complex tasks. A customer service bot that retrieves your account balance isn’t necessarily an agent. But a system that notices your payment pattern, proactively suggests a better plan, and handles the switch? That’s agent behavior.
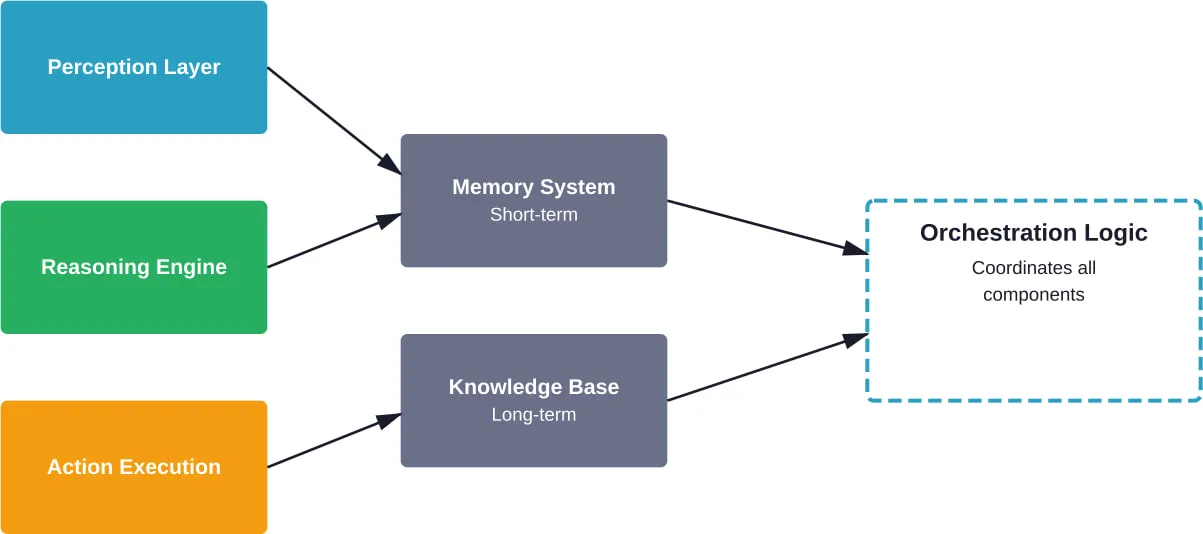
Core Components of Agent Systems
Every functional agent architecture contains these foundational elements:
- Perception layer: How the agent receives and processes information from its environment
- Reasoning engine: The cognitive component, typically powered by large language models
- Memory system: Both short-term context and long-term knowledge storage
- Action execution: Tools and APIs the agent can invoke
- Orchestration logic: The control flow that coordinates perception, reasoning, and action
Research from Halmstad University emphasizes that reliability in agentic AI stems directly from architectural choices. The way these components connect determines whether a system degrades gracefully under unexpected conditions or fails catastrophically.
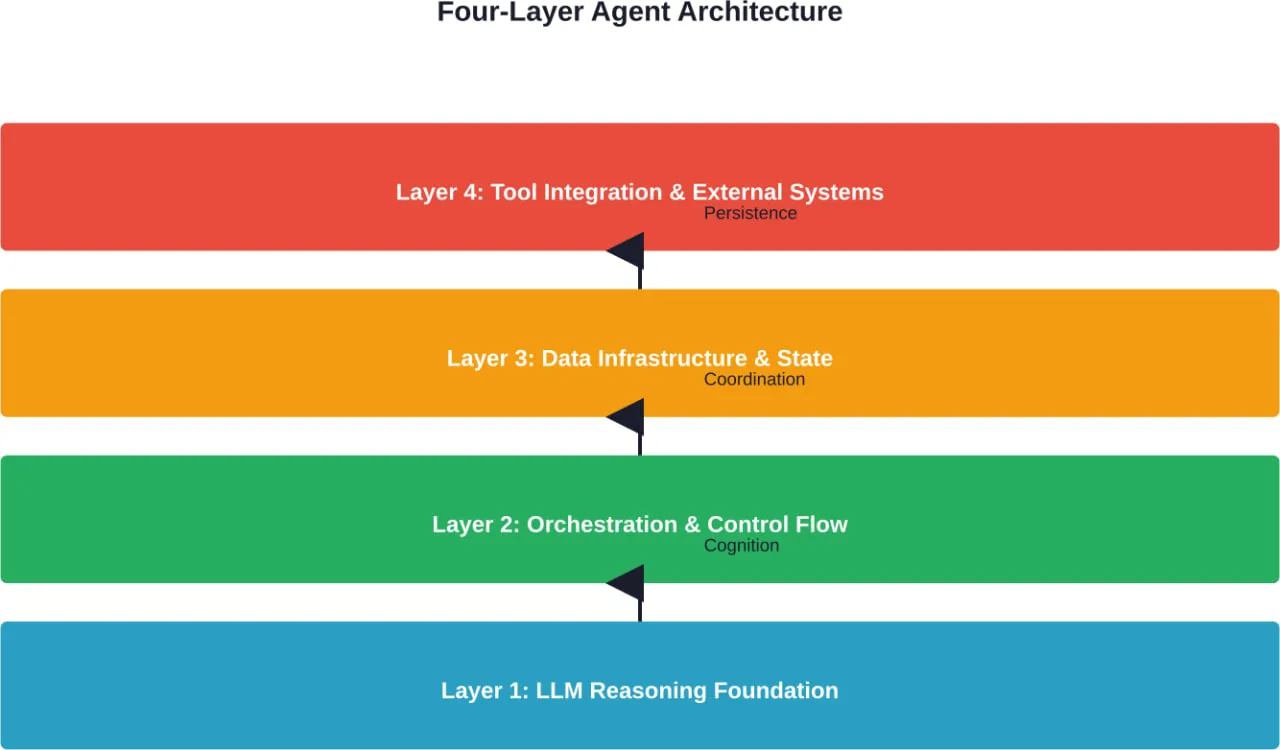
The Four-Layer Agent Architecture Model
Modern production agent systems typically implement a four-layer architectural model. This structure emerged from practical experience building systems that handle real-world complexity without collapsing into unpredictable behavior.
Layer 1: LLM Reasoning Foundation
At the base sits the reasoning layer—usually one or more large language models. This layer handles natural language understanding, task decomposition, and decision-making. The LLM doesn’t run the entire system; it serves as the cognitive engine that interprets intent and plans actions.
Different reasoning patterns exist at this layer. Chain-of-thought prompting breaks complex problems into steps. ReAct (Reasoning + Acting) patterns interleave thinking and tool use. Tree-of-thought approaches explore multiple reasoning paths simultaneously.
Layer 2: Orchestration and Control Flow
The orchestration layer sits above reasoning and determines how the agent coordinates its actions. This is where architectural patterns become critical. According to AI agent orchestration patterns documentation, teams can choose from several proven approaches:
| Pattern | Description | Best For |
|---|---|---|
| Sequential | Tasks execute one after another in predetermined order | Predictable workflows with clear dependencies |
| Concurrent | Multiple tasks run in parallel, results synthesized | Independent operations that can happen simultaneously |
| Group Chat | Multiple specialized agents collaborate through discussion | Complex problems requiring diverse expertise |
| Handoff | Tasks pass between agents based on context and capability | Customer service, multi-stage processes |
| Magentic | Dynamically routes to appropriate specialized agents | Unpredictable task variety requiring flexibility |
Sequential orchestration works when workflows are predictable. A travel booking agent that checks availability, then compares prices, then reserves a ticket follows sequential logic. Concurrent orchestration handles scenarios where multiple independent operations can happen at once—like an agent gathering data from five different APIs simultaneously.
Layer 3: Data Infrastructure and State Management
Agents need memory, and that requires infrastructure. This layer handles how agents store and retrieve information across interactions. Short-term memory maintains conversation context within a session. Long-term memory persists knowledge across sessions, often using vector databases for semantic search.
State management becomes critical in production. What happens when an agent crashes mid-task? The data infrastructure layer ensures the system can recover gracefully, resume interrupted workflows, and maintain consistency.
Layer 4: Tool Integration and External Systems
The top layer connects agents to external capabilities. This includes APIs, databases, search engines, calculators, code interpreters—anything that extends the agent’s abilities beyond pure language generation.
Tool integration requires careful interface design. Each tool needs a clear description the LLM can understand, explicit parameters, and robust error handling. According to CSIRO’s research on agent design patterns, well-designed tool interfaces dramatically improve agent reliability.
Multi-Agent System Architectures
Single-agent systems handle straightforward tasks well. But complex enterprise scenarios often require multiple specialized agents working together. Multi-agent architectures distribute cognition across several autonomous components, each with specific expertise.
Microsoft’s multi-agent reference architecture demonstrates how organizations deploy these systems at scale. Rather than building one massive agent that tries to do everything, teams create focused agents that collaborate through well-defined protocols.
When Multi-Agent Makes Sense
Not every problem needs multiple agents. Research from the University of Tunis examining agentic AI frameworks suggests multi-agent approaches excel in scenarios with:
- Distinct domains of expertise that don’t overlap significantly
- Tasks that naturally decompose into parallel subtasks
- Requirements for different reasoning strategies within one workflow
- Scale demands where single agents create bottlenecks
A financial analysis system might employ separate agents for market research, risk assessment, regulatory compliance, and portfolio optimization. Each agent specializes deeply in its domain, then collaborates with others to produce comprehensive recommendations.
Coordination Patterns in Multi-Agent Systems
Getting agents to work together requires explicit coordination mechanisms. The group chat pattern, described in Azure’s orchestration documentation, lets agents communicate through message passing. One agent poses questions, others respond with their specialized knowledge, and a coordinator synthesizes the discussion.
Handoff patterns work differently. Here agents explicitly transfer control to one another based on capability requirements. A customer service scenario might start with a general inquiry agent, hand off to a technical specialist for complex issues, then transfer to a billing agent for payment matters.
Hierarchical architectures introduce leader-follower relationships. A supervisor agent delegates subtasks to worker agents, monitors their progress, and integrates results. This pattern reduces coordination complexity but introduces single points of failure.
Orchestration Patterns Explained
The orchestration layer determines how agents execute tasks. Choosing the right pattern matters—it directly impacts reliability, performance, and maintainability. Research from Halmstad University emphasizes that architectural choices at this layer shape system reliability more than any other factor.
Sequential Orchestration
Sequential orchestration runs tasks one after another. Step one completes, then step two begins. This pattern works well when operations have clear dependencies and outcomes from early steps inform later decisions.
Consider a research agent analyzing a scientific paper. It might first extract the abstract, then identify key concepts, then search for related work, then synthesize findings. Each step builds on previous results, making sequential execution natural.
The downside? Latency. Every task waits for its predecessor to finish completely.
Concurrent Orchestration
Concurrent patterns run multiple tasks simultaneously when operations don’t depend on each other. A market analysis agent might query ten different data sources in parallel, then combine results once all queries complete.
This dramatically reduces total execution time for independent operations. But it introduces complexity—handling partial failures, managing timeouts, and synthesizing potentially conflicting information.
Group Chat and Collaborative Patterns
Group chat orchestration treats multiple specialized agents as participants in a discussion. Agents take turns contributing insights, building on each other’s responses. A coordinator agent facilitates the conversation and determines when enough information exists to conclude.
This pattern excels for problems without clear solution paths. Complex strategy questions, creative brainstorming, and scenarios requiring diverse perspectives benefit from collaborative exploration.
Magentic and Dynamic Routing Patterns
The magentic pattern, referenced in Microsoft’s agent work, dynamically routes tasks to appropriate specialized agents based on content analysis. Rather than predetermined workflows, the system analyzes each request and intelligently selects which agent should handle it.
This provides flexibility for unpredictable workloads but requires robust routing logic and clear agent capability definitions.
| Orchestration Pattern | Latency | Complexity | Flexibility | Reliability |
|---|---|---|---|---|
| Sequential | High | Low | Low | High |
| Concurrent | Low | Medium | Medium | Medium |
| Group Chat | High | High | High | Medium |
| Handoff | Medium | Medium | Medium | High |
| Magentic/Dynamic | Medium | High | High | Medium |
State Management and Memory Architecture
Agents without memory can’t maintain context, learn from interactions, or handle complex multi-step workflows. The memory architecture determines what information persists, how it’s retrieved, and when it expires.
Short-Term Context Windows
Short-term memory handles immediate conversation context. For LLM-based agents, this typically means the prompt window—everything the model sees in the current interaction. Context windows have grown substantially, with some models now handling hundreds of thousands of tokens.
But larger windows don’t eliminate the need for smart context management. Relevant information should appear near the beginning and end of prompts, where models pay more attention. Irrelevant details consume tokens without improving performance.
Long-Term Knowledge Storage
Long-term memory persists across sessions. This might include user preferences, historical interactions, learned facts, or accumulated expertise. Vector databases enable semantic search over stored information—agents retrieve contextually relevant memories rather than exact keyword matches.
Implementation often combines structured databases for factual information with vector stores for semantic recall. A customer service agent might query a SQL database for account details while simultaneously searching vector embeddings for similar past issues.
State Persistence and Recovery
Production systems need state persistence. What happens when an agent crashes halfway through a multi-step booking process? Without proper state management, users start over. With it, the system recovers and resumes.
This requires explicit state tracking—recording which steps completed successfully, what decisions the agent made, and what remains to be done. State can persist in databases, message queues, or specialized orchestration frameworks.
When Agents Are Overkill
Here’s what marketing materials won’t tell you: agents aren’t always the right architecture. Many problems that seem to require agents actually work better with simpler approaches.
If workflows are 80% predictable, deterministic code often performs better than autonomous agents. A trip planning website that needs to check availability, compare prices, and book tickets doesn’t need agent architecture. It needs a well-designed API integration.
Agents introduce overhead—computational cost, latency, unpredictability, and debugging complexity. These costs make sense when problems genuinely require reasoning, adaptation, and autonomous decision-making. But forcing agent architecture onto simple workflows creates unnecessary complexity.
Direct Model Calls vs Agent Systems
According to Azure’s architecture guidance, direct model calls suffice for classification, summarization, and simple transformations. No orchestration, no tools, no state management. Just prompt engineering and model inference.
Agent architectures become valuable when tasks require multiple steps, external information gathering, or adaptive strategies based on intermediate results. The decision point: can you map the workflow in advance, or does the agent need to figure it out dynamically?
Tool Integration and API Design
Tools extend agent capabilities beyond language generation. But poorly designed tool interfaces lead to unreliable behavior, failed function calls, and frustrated debugging sessions.
Designing Tool Interfaces
Each tool needs three elements: a clear natural language description, explicit parameters with types and constraints, and robust error handling. The description tells the LLM when and why to use the tool. Parameters define exactly what information the tool requires. Error handling ensures graceful degradation when operations fail.
Descriptions should be concise but specific. Instead of “searches the database,” write “searches customer records by email address or phone number, returning account details and purchase history.” Specificity helps models choose appropriate tools.
Function Calling Protocols
Modern LLMs support structured function calling—generating JSON that specifies tool invocation rather than natural language. This reduces parsing errors and makes tool usage more reliable.
But function calling requires well-defined schemas. Parameters need clear types, defaults, and validation rules. Optional versus required parameters must be explicit. Ambiguous interfaces lead to hallucinated parameters and failed calls.
Production Deployment Considerations
Getting agents working in development differs dramatically from running them reliably in production. According to NIST’s AI Agent Standards Initiative announced on February 17, 2026, standardizing agent deployment practices matters for security, interoperability, and reliability.
Monitoring and Observability
Traditional application monitoring doesn’t capture what matters for agents. Teams need visibility into reasoning steps, tool invocations, state transitions, and decision paths—not just latency and error rates.
Logging every LLM interaction helps debug unexpected behavior. Tracking which tools get called reveals usage patterns. Recording state transitions shows where workflows break down.
Safety and Guardrails
Autonomous systems need constraints. Guardrails prevent agents from taking harmful actions, exceeding authority, or making irreversible decisions without confirmation.
This might include approval workflows for high-stakes actions, spending limits for agents with API access, or content filtering for customer-facing systems. NIST’s AI Risk Management Framework provides guidance on building trustworthy AI systems with appropriate safeguards.
Cost Management
LLM API calls aren’t free. Agents that make dozens of reasoning steps per task can generate significant costs. Production deployments need cost monitoring, budget alerts, and optimization strategies.
Caching repeated queries, using smaller models for simple decisions, and implementing rate limiting all help control expenses without sacrificing capability.

Enterprise Multi-Agent Patterns
Enterprise deployments face unique challenges: legacy system integration, compliance requirements, scale demands, and organizational complexity. Research on multi-agent control systems highlights how architectural choices cascade through organizational structures.
Cloud Architecture for Agent Systems
Cloud infrastructure provides the scalability agents need. Cloud Run, Lambda, and similar serverless platforms handle variable workloads without manual scaling. But agents introduce stateful requirements that complicate serverless deployment.
Hybrid approaches work well—serverless functions for stateless reasoning steps, managed databases for state persistence, and message queues for orchestration. This separates concerns and lets each component scale independently.
Security and Compliance
Autonomous systems that access sensitive data or make consequential decisions need robust security. This includes authentication for tool access, authorization for agent actions, audit logging, and data protection.
Security considerations in AI agent systems should be architectural—built into system design rather than bolted on afterward. Authentication tokens expire, permissions follow least-privilege principles, and sensitive data never appears in unencrypted logs.
Integration with Existing Systems
Enterprises rarely start fresh. Agent architectures must integrate with decades of legacy systems, each with its own APIs, data formats, and quirks.
Adapter patterns help—building translation layers that convert between agent expectations and legacy system realities. This isolates complexity and lets agent logic remain clean while adapters handle messy integration details.
Architectural Decision Framework
Choosing the right agent architecture requires evaluating tradeoffs across multiple dimensions. Here’s a framework for making informed decisions:
Complexity Assessment
Start by assessing task complexity honestly. Can workflows be mapped in advance? Do tasks require reasoning and adaptation? Would simpler approaches work?
If 80% of cases follow predictable paths, consider deterministic systems with agent fallback for edge cases. Full agent architecture makes sense when task variety exceeds what predetermined logic can handle.
Reliability Requirements
How critical is consistent behavior? Customer service agents need high reliability—unpredictable responses damage trust. Research agents exploring novel strategies tolerate more variability.
Higher reliability requirements favor simpler orchestration patterns, extensive testing, and strong guardrails. Lower stakes scenarios allow more experimental architectures.
Latency Constraints
Real-time interactions demand fast response. Multi-step reasoning workflows introduce latency. If users expect sub-second responses, complex agent architectures might not fit.
Latency-sensitive applications benefit from concurrent orchestration, smaller models for quick decisions, and aggressive caching. Batch workflows tolerate more elaborate reasoning.
Scale Projections
How many concurrent users will the system support? Single-agent architectures create bottlenecks at scale. Multi-agent systems distribute load but introduce coordination overhead.
High-scale deployments favor stateless components, horizontal scaling, and asynchronous processing. Small-scale internal tools can use simpler architectures.
Turn Your AI Architecture Into a Working System
An architecture diagram shows how AI agents, services, and data flows should connect. The challenge usually starts after that – integrating components, setting up stable backend logic, and making sure everything runs reliably in a real environment. This is where many teams slow down, especially when internal resources are limited or focused on other priorities.
A-listware supports this stage from an engineering perspective. The company provides dedicated development teams that handle backend systems, integrations, APIs, and infrastructure around AI-driven solutions. The focus is not on building AI agents themselves, but on making sure the surrounding system works as expected and scales without constant fixes.
If your architecture is already defined but not yet implemented, this is the point to bring in extra engineering capacity. Contact A-listware to support the development, integration, and rollout of your system.
Frequently Asked Questions
- What’s the difference between agent architecture and traditional software architecture?
Traditional software follows predetermined logic paths—given input X, execute steps A, B, C. Agent architectures introduce autonomous decision-making. The system determines its own action sequence based on goals and environmental feedback. This requires components for reasoning, state management, and tool orchestration that don’t exist in conventional architectures.
- Do I need multiple agents or will one suffice?
Single agents work well for focused tasks within one domain. Multiple agents make sense when problems naturally decompose into distinct specializations, require parallel processing, or benefit from diverse reasoning approaches. Most teams start with single-agent systems and introduce multiple agents only when complexity or scale demands it.
- Which orchestration pattern should I choose?
Sequential orchestration works for predictable workflows with clear step dependencies. Concurrent patterns reduce latency when operations are independent. Group chat excels for complex problems without obvious solutions. Choose based on whether your workflow is predetermined (sequential), parallelizable (concurrent), or exploratory (group chat).
- How do I handle agent failures in production?
Implement state persistence so agents can resume after failures. Use retry logic with exponential backoff for transient errors. Design graceful degradation—if the agent can’t complete a task autonomously, escalate to human operators rather than failing silently. Monitor state transitions to detect where failures occur most frequently.
- What’s the role of vector databases in agent architecture?
Vector databases enable semantic memory—agents retrieve contextually relevant information rather than exact keyword matches. This supports long-term memory across sessions, retrieval-augmented generation workflows, and finding similar past cases. Not every agent needs vector storage, but those requiring extensive knowledge recall benefit significantly.
- How do I prevent agents from taking harmful actions?
Implement guardrails at multiple levels. Constrain which tools agents can access. Require approval workflows for high-stakes actions. Set spending limits for agents with financial access. Filter outputs for inappropriate content. Design fail-safes that prevent irreversible actions. AI risk management frameworks provide guidance on building appropriate safeguards.
- Should I build agent infrastructure from scratch or use a framework?
Frameworks like LangChain, AutoGen, and Semantic Kernel provide orchestration primitives, tool integration patterns, and state management utilities. They accelerate development but introduce dependencies and opinions. Building from scratch offers control but requires more engineering effort. For most teams, frameworks provide a reasonable starting point with the option to replace components later.
Conclusion: Building Reliable Agent Systems
AI agent architecture determines whether autonomous systems perform reliably or fail unpredictably. The four-layer model—reasoning foundation, orchestration logic, data infrastructure, and tool integration—provides a proven structure for building production systems.
Architectural choices cascade through every aspect of system behavior. Sequential versus concurrent orchestration affects latency. State management approaches determine recovery capabilities. Multi-agent versus single-agent designs impact scale characteristics.
But architecture alone doesn’t guarantee success. Production-ready agents require monitoring, guardrails, cost management, and security. According to NIST’s AI Agent Standards Initiative, standardizing these practices will enable broader adoption with appropriate safeguards.
Start with the simplest architecture that meets requirements. Add complexity only when simpler approaches prove insufficient. Test extensively with realistic workloads before production deployment. Monitor agent behavior closely in early releases.
The research is clear: reliability stems from thoughtful architectural choices, not merely from using the latest models. Teams that invest in solid architecture, proper tooling, and robust state management build agents that actually work when deployed.
Ready to implement these patterns? Begin by mapping your specific use case to the orchestration patterns and architectural layers described here. Prototype with a single-agent system, validate behavior, then scale complexity as requirements demand.


