Résumé rapide : Digital transformation for municipalities involves the strategic integration of digital technologies into all areas of local government operations to improve service delivery, operational efficiency, and citizen engagement. This comprehensive shift goes beyond simple digitization of paper records to fundamentally reimagining how municipalities operate, make decisions, and serve their communities through tools like cloud computing, IoT sensors, AI-driven analytics, and automated workflows.
Municipal governments face unprecedented pressure to do more with less. Citizens expect seamless digital experiences that mirror what they get from private sector companies. Budget constraints tighten year after year. Meanwhile, infrastructure ages, workforces shrink, and urban challenges grow more complex.
Digital transformation offers municipalities a path forward. But what does that actually mean for local government?
Unlike private companies chasing competitive advantage, municipalities must balance efficiency gains with public trust, transparency, and equitable access. The stakes are different. The constraints are tighter. And the playbook needs serious adaptation.
This guide explores how municipalities can successfully navigate digital transformation—from foundational technologies to implementation strategies that work within the unique constraints of local government.
Understanding Digital Transformation in Municipal Context
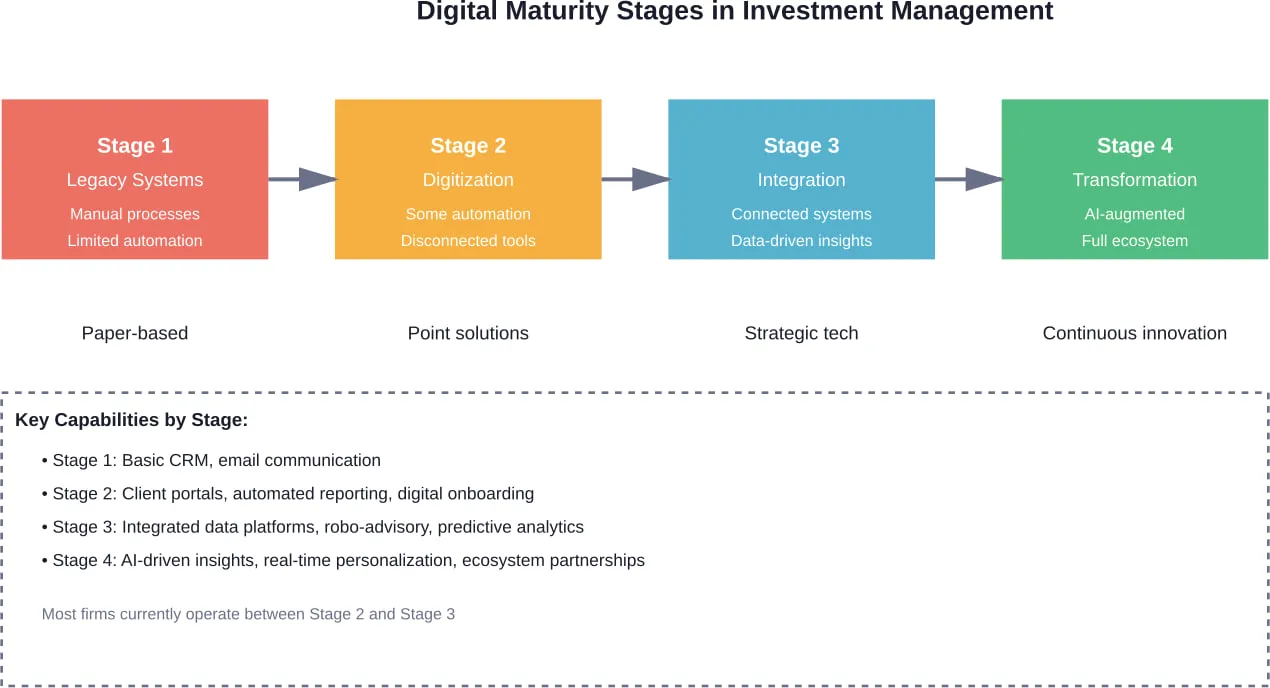
Digital transformation in municipalities means fundamentally rethinking how local governments operate, deliver services, and interact with citizens using digital technologies. It’s not about buying software or scanning documents.
The distinction matters. Three related but different concepts often get confused:
Digitization vs. Digitalization vs. Digital Transformation
- Digitization converts analog information into digital format. Scanning paper permits into PDFs? That’s digitization. It creates digital copies but doesn’t change how work gets done.
- Digitalization uses digital technologies to change business processes. Online permit applications that route automatically to the right department? That’s digitalization. Processes become more efficient, but the fundamental operating model remains similar.
- Transformation numérique leverages technology to fundamentally reimagine how an organization creates and delivers value. A municipality that uses real-time sensor data, predictive analytics, and automated workflows to shift from reactive to preventive infrastructure maintenance? That’s transformation. The entire approach to service delivery changes.
According to research from municipalities in the Eastern Cape, many local governments struggle because they lack standardized digital transformation principles. They jump to solutions without understanding this foundational distinction.
Why Municipalities Need a Different Approach
Private sector digital transformation frameworks don’t translate directly to municipal government. Several factors make local government transformation unique:
- Public accountability requirements: Every decision faces scrutiny. Transparency isn’t optional. Technology choices must withstand public records requests and open meeting laws.
- Equity imperatives: Municipal services must remain accessible to all residents regardless of digital literacy, internet access, or technical capabilities. Digital solutions can’t leave vulnerable populations behind.
- Legacy system constraints: Decades-old systems often run critical functions. Replacement carries enormous risk. Integration becomes more important than wholesale replacement.
- Budget cycles: Multi-year transformation initiatives must navigate annual budget processes. Funding certainty remains elusive even for obviously beneficial projects.
- Workforce realities: According to ICMA workforce research, 46% of HR managers in the public sector anticipate the largest wave of retirements in coming years. Knowledge walks out the door while specialized digital skills remain scarce.
Accelerate Municipal Innovation with Expert Development Teams
Transitioning to a digital-first municipality requires more than just new software; it requires the right technical talent to integrate legacy systems with modern citizen-facing platforms. Many local governments struggle with recruitment delays and high overhead when trying to build internal IT departments. A-Listware solves this by providing specialized development teams and staff augmentation that scale with your specific digital transformation goals.
- Expert Talent: Access to vetted developers experienced in AI, cloud infrastructure, and data analytics.
- Cost Efficiency: Significant savings compared to traditional in-house hiring and long-term overhead.
- Legacy Modernization: Specialized support for migrating outdated systems to secure, scalable architectures.
- Une mise à l'échelle flexible : Quickly expand or reduce your team based on project phases and budget availability.
Commencez votre transformation numérique avec A-Listware.
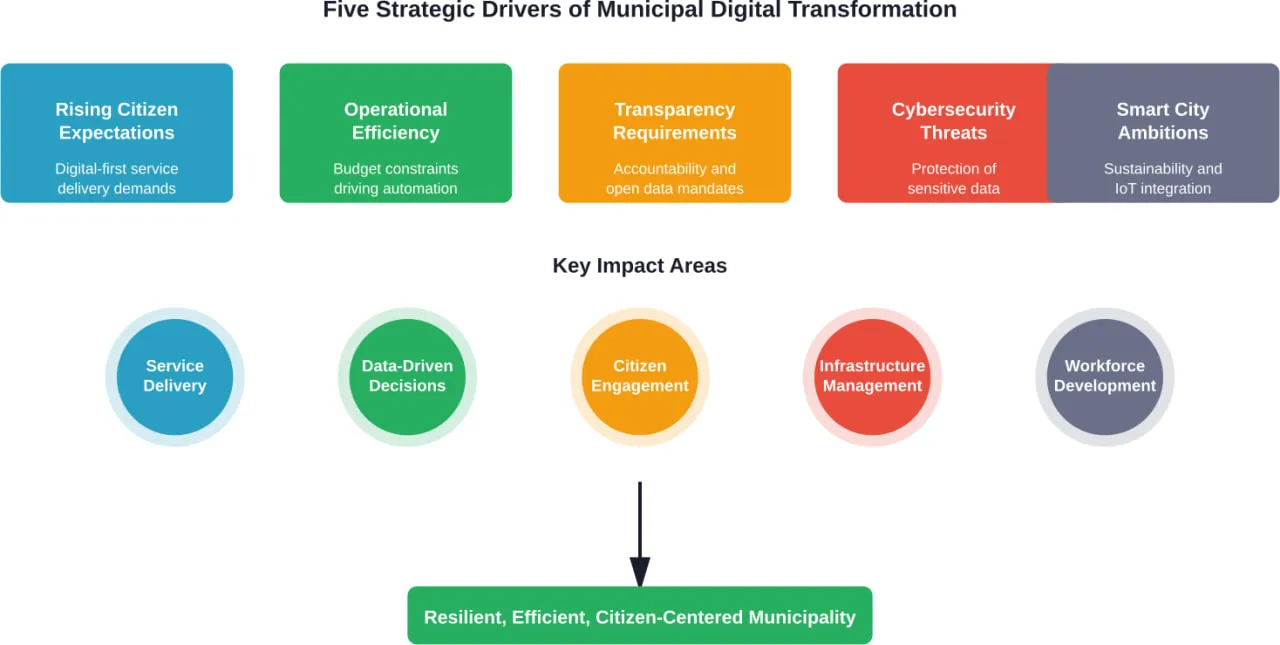
The Strategic Drivers Behind Municipal Digital Transformation
What’s actually pushing municipalities toward digital transformation right now?
Rising Citizen Expectations
Residents increasingly expect friction-free, self-service interactions with their local government. In the private sector, people access websites or download apps for basic transactions, check service status, and get real-time updates. That expectation now extends to government services.
The gap between private sector digital experiences and government services has grown too wide. Citizens notice. They voice frustration. And they judge their local government accordingly.
Operational Efficiency Pressures
Local governments operate complex organizations delivering multiple services to residents. But inefficient processes waste staff time on manual tasks, paper shuffling, and redundant data entry.
Digital transformation offers municipalities ways to streamline operations, reduce administrative overhead, and reallocate staff to higher-value activities. When budgets stay flat or shrink, efficiency gains become essential for maintaining service levels.
Transparency and Accountability Demands
Citizens increasingly demand visibility into how their local government operates. Where do tax dollars go? How are decisions made? What’s the status of that pothole repair request?
Technology enables unprecedented transparency. Digital systems can automatically publish data, track performance metrics, and give residents real-time windows into government operations. This transparency helps citizens hold leaders accountable and reduces potential for corruption.
Cybersecurity Imperatives
Municipal governments store enormous amounts of sensitive citizen data and operate essential services. That makes them attractive targets for cybercrime—especially when they’re running outdated systems with inadequate security.
Modern digital infrastructure includes security as a foundational element rather than an afterthought. Cloud platforms, zero-trust architectures, and automated security monitoring significantly improve municipal cybersecurity postures.
Smart City Ambitions
According to Sustainable Development Goal 11, smart cities strive to make urban areas more inclusive, safe, resilient, and sustainable. Digital technologies address urbanization concerns like rising energy use, pollution, waste disposal, and social inequities.
The Internet of Things and data-driven technologies have become essential drivers for smart municipalities. Sensors monitor everything from air quality to parking availability. Data analytics optimize service delivery. Integrated systems coordinate responses across departments.
As NIST research emphasizes, the measurement science and standards-based foundations for interoperable, replicable, scalable, and trustworthy cyber-physical systems enable cities and communities of all sizes to improve their efficiency and trustworthiness cost-effectively.

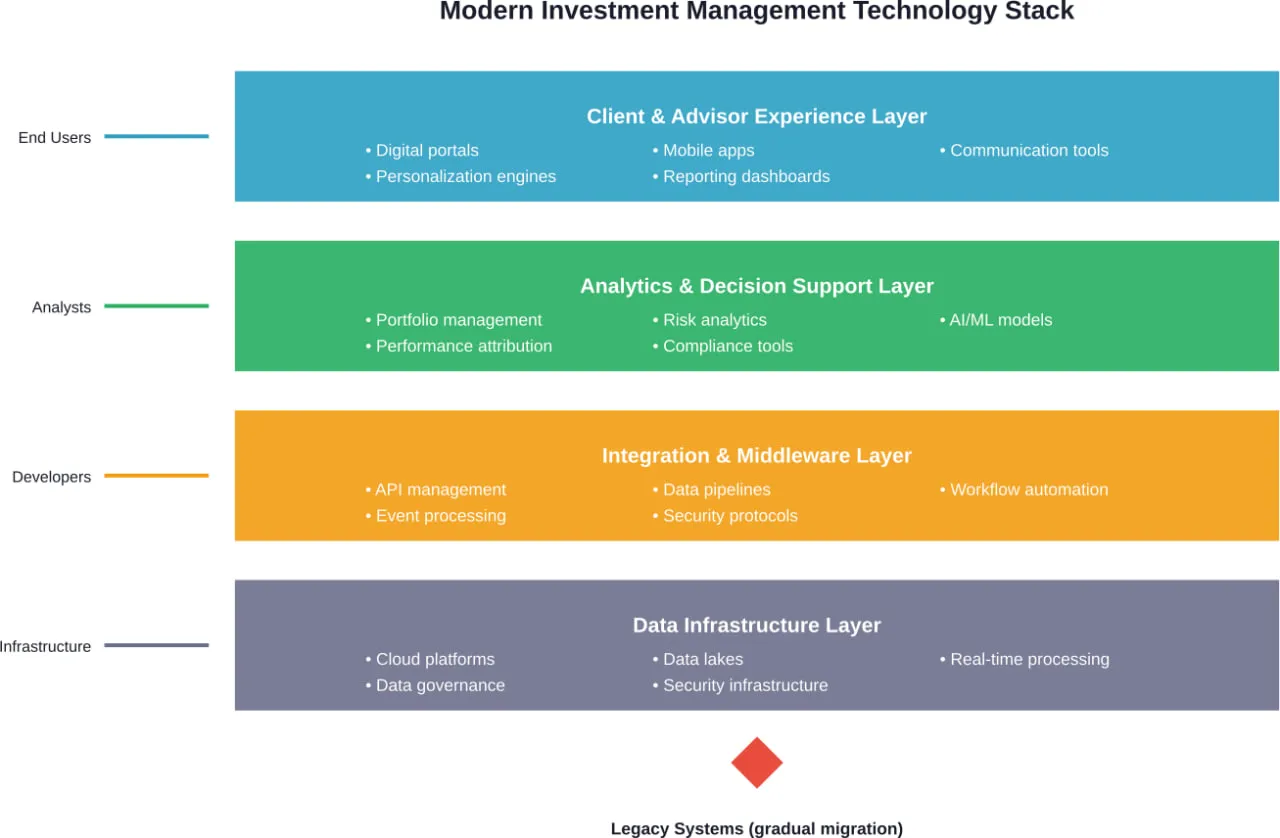
Core Technologies Enabling Municipal Digital Transformation
Several technology categories form the foundation for municipal digital transformation. Understanding each helps municipalities make informed investment decisions.
Cloud Computing Infrastructure
Cloud platforms provide scalable, secure infrastructure without requiring municipalities to build and maintain their own data centers. This shift from capital expenditure to operational expenditure makes technology more accessible for smaller municipalities with limited IT budgets.
Cloud infrastructure also enhances disaster recovery capabilities, improves system reliability, and enables remote work—a capability that proved essential during recent years.
Internet of Things (IoT) Sensors and Networks
IoT sensors collect real-time data from physical infrastructure. Smart streetlights adjust brightness based on activity. Water sensors detect leaks before they become expensive problems. Traffic monitors optimize signal timing to reduce congestion.
NIST research emphasizes that cyber-physical systems enabled by IoT require interoperable, replicable, scalable, and trustworthy foundations. Standards become critical as municipalities deploy thousands of connected devices across their infrastructure.
Analyse des données et intelligence économique
Municipalities generate enormous amounts of data. But raw data sitting in siloed systems creates no value. Analytics platforms transform that data into actionable insights.
Dashboards visualize trends. Predictive models forecast service demand. Pattern recognition identifies inefficiencies. This data-driven approach enables municipalities to shift from reactive to proactive management.
Workflow Automation Platforms
Workflow automation moves requests, documents, and approvals through processes without manual intervention. A building permit application routes automatically to the right reviewers, tracks completion, triggers notifications, and generates approvals—all without staff manually managing each step.
Beyond basic digitization, workflow automation fundamentally changes how municipalities deliver services. Staff focus on complex cases requiring judgment rather than shepherding routine requests through manual processes.
Intelligence artificielle et apprentissage automatique
AI applications in municipal government continue expanding. Chatbots handle routine citizen inquiries. Machine learning models predict maintenance needs. Computer vision analyzes infrastructure conditions from drone footage.
However, according to research from the RAND Corporation, state and local governments are experimenting with AI but lack systematic approaches to scale these efforts effectively. Instead, efforts remain piecemeal and slow, leaving many practitioners struggling to keep up.
As RAND researchers note, the opportunity exists now to set standards for AI-enabled governance, but it requires proactive steps in policy development, funding, procurement, workforce development, and safeguards.
Citizen Engagement Platforms
Modern engagement platforms give residents convenient ways to interact with their local government. Mobile apps let citizens report issues, request services, and receive updates. Online portals provide self-service access to permits, payments, and records.
These platforms create two-way communication channels rather than one-way information broadcasts. Municipalities gather feedback, measure satisfaction, and respond to community needs more effectively.
Cybersecurity and Identity Management
As municipalities digitize operations and connect systems, cybersecurity becomes foundational rather than peripheral. Zero-trust architectures verify every access request. Multi-factor authentication protects sensitive systems. Automated monitoring detects threats in real time.
Identity management ensures the right people access the right systems with the right permissions—and provides audit trails demonstrating compliance with regulations.
Key Dimensions of Smart Municipality Transformation
Research on smart municipalities identifies four key dimensions where digital transformation creates the most impact:
Smart Governance
Digital technologies enable more transparent, participatory, and efficient governance. Online portals publish budget data, meeting minutes, and performance metrics. Digital platforms facilitate citizen input on policy decisions. Automated systems ensure consistent application of rules and regulations.
Smart governance also means better internal coordination. Integrated systems let departments share information seamlessly. Workflow automation eliminates redundant approvals. Data analytics inform strategic planning.
Smart Environment
Environmental monitoring and management benefit significantly from digital technologies. Sensor networks track air and water quality. Smart grids optimize energy distribution. Waste management systems use IoT to optimize collection routes and reduce fuel consumption.
According to research on smart cities and energy, municipalities can contribute substantially to addressing global energy challenges through digital transformation of infrastructure management.
Smart Living
Quality of life improvements stem from digital transformation across multiple municipal services. Smart transportation reduces congestion and improves mobility. Digital health services expand access to care. Connected emergency services respond faster and more effectively.
Public safety applications use predictive analytics to allocate resources more efficiently. Recreation departments offer online registration and facility booking. Libraries provide digital resources accessible from anywhere.
Smart Technology Integration
The technology dimension focuses on infrastructure that enables other smart capabilities. High-speed broadband reaches all residents. Secure networks connect municipal facilities. Data platforms integrate information from diverse sources.
Research from Stockholm’s broadband initiative shows that availability and adoption represent different challenges. While Stockholm’s broadband network reaches 100 percent of businesses and 90 percent of residences, significant gaps remain between who can access broadband and who actually does. Municipalities must address both infrastructure and adoption barriers.
| Smart Dimension | Objectif principal | Technologies clés | Citizen Impact |
|---|
| Smart Governance | Transparent, efficient administration | Cloud platforms, workflow automation, open data portals | Better accountability, easier access to services |
| Smart Environment | Sustainability and resource management | IoT sensors, smart grids, environmental monitoring | Cleaner air, efficient utilities, reduced waste |
| Smart Living | Quality of life improvements | Mobile apps, connected services, digital health platforms | Improved mobility, safety, and access to services |
| Smart Technology | Digital infrastructure foundation | Broadband networks, data integration, cybersecurity systems | Universal access, secure services, integrated experience |
Practical Benefits Municipalities Achieve Through Digital Transformation
What tangible outcomes can municipalities expect from successful digital transformation? Real-world implementations demonstrate several consistent benefit categories:
Operational Cost Reduction
Automated workflows eliminate manual processing time. Cloud infrastructure reduces IT maintenance costs. Digital communications replace printing and mailing expenses. Predictive maintenance prevents costly emergency repairs.
These savings accumulate across departments and compound over time. Staff hours freed from routine tasks get reallocated to higher-value activities.
Improved Service Speed and Quality
Digital transformation dramatically reduces processing times for common municipal services. Permit applications that once took weeks now complete in days. Service requests get routed instantly to appropriate departments. Citizens track their request status in real time rather than making phone calls.
Speed improvements also enhance quality. Automated systems apply rules consistently. Digital checklists reduce errors. Integration eliminates redundant data entry that introduces mistakes.
Enhanced Transparency and Trust
Open data portals and digital dashboards give citizens unprecedented visibility into municipal operations. Budget visualizations show where money goes. Performance metrics demonstrate service levels. Meeting recordings and transcripts remain permanently accessible.
This transparency builds trust. When citizens can see how decisions get made and verify that services meet standards, confidence in local government increases.
Better Resource Allocation
Data analytics reveal where municipalities over-invest or under-serve. Usage patterns inform facility planning. Demand forecasts improve staffing decisions. Performance metrics identify underperforming processes that need attention.
This evidence-based approach to resource allocation ensures municipalities maximize the impact of constrained budgets.
Increased Accessibility and Equity
Digital services can expand access when designed thoughtfully. Online portals let residents interact with their government outside traditional office hours. Mobile apps eliminate transportation barriers. Multilingual interfaces serve diverse populations.
However, digital transformation must address rather than widen the digital divide. Municipalities need parallel strategies for residents without internet access or digital literacy.
Environmental Sustainability Gains
Going paperless reduces environmental impact directly. But digital transformation enables broader sustainability improvements. Smart lighting reduces energy consumption. Optimized routes cut fleet fuel usage. Building automation lowers heating and cooling costs.
Sensor data helps municipalities track and achieve environmental goals through better measurement and management.
Workforce Development and Retention
Modern digital tools make municipal jobs more attractive to younger workers expecting technology-enabled workplaces. Automation of tedious tasks reduces burnout. Remote work capabilities improve work-life balance. Training on new technologies develops valuable skills.
Given that 46% of HR managers in the public sector anticipate significant retirement waves, municipalities that embrace digital transformation position themselves better to attract and retain talent.
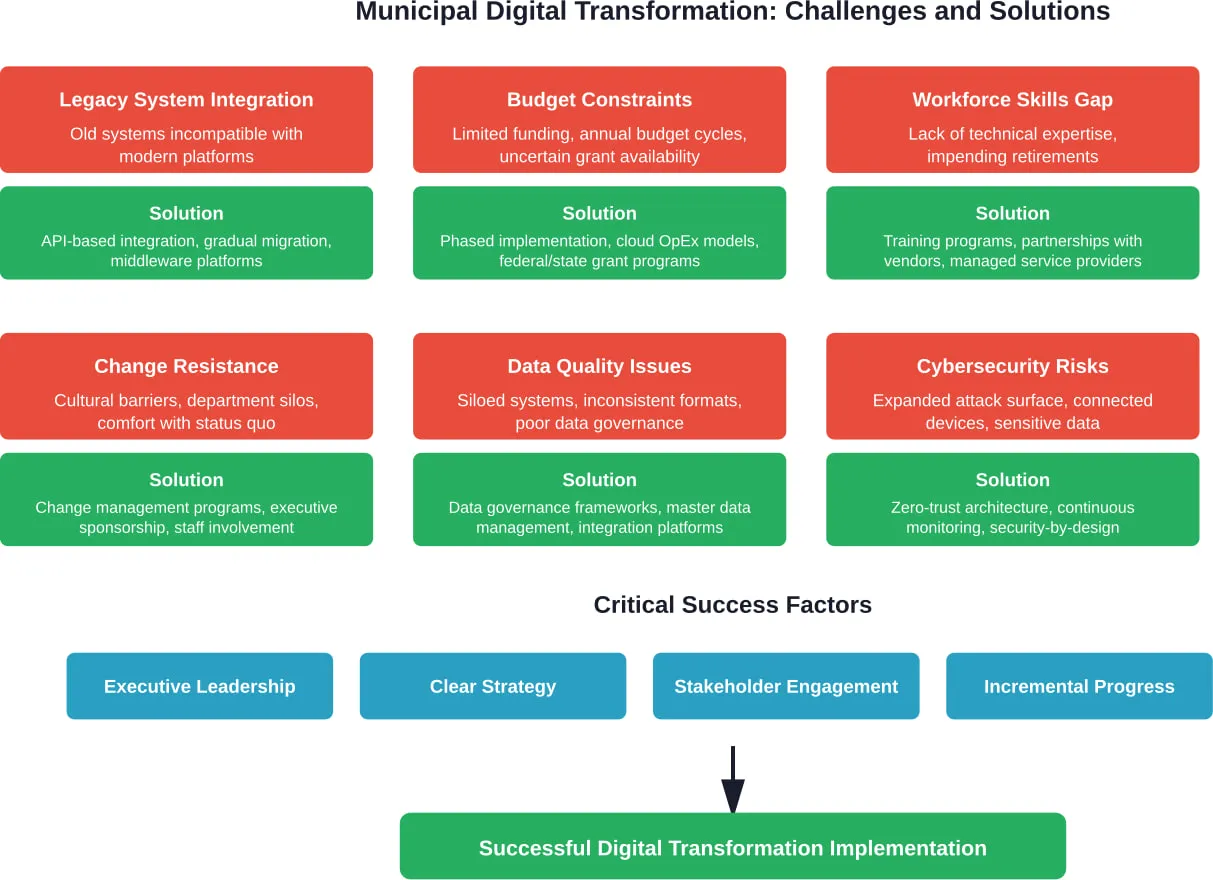
Common Challenges Municipalities Face During Digital Transformation
Understanding obstacles helps municipalities plan realistic transformation strategies. Research across multiple municipalities identifies recurring challenges:
Intégration des systèmes existants
Decades-old systems run critical functions but weren’t designed to integrate with modern platforms. Data exists in incompatible formats. APIs don’t exist. Vendors no longer support the software.
Wholesale replacement carries enormous risk and cost. Gradual migration requires careful planning and significant technical expertise that many municipalities lack in-house.
Budget Constraints and Funding Uncertainty
Digital transformation requires multi-year investment, but municipal budgets operate on annual cycles. Initial costs often exceed ongoing savings, creating challenging budget dynamics. Grant funding helps but introduces uncertainty and reporting burdens.
Federal programs like the State and Local Cybersecurity Grant Program offer potential, though current authorization expires September 30, 2026. State initiatives like Massachusetts’ FutureTech Act exemplifies direct state investment, with authorization mentioned for IT capital projects including AI.
Lacunes en matière de compétences de la main-d'œuvre
Municipal workforces often lack the technical skills needed to implement and manage digital transformation initiatives. Specialized skills remain scarce in public sector labor markets. Training existing staff takes time and resources.
The traditional model of recruiting externally and hiring full-time for long-term tenure faces strain. Retirements accelerate while specialized digital skills become harder to attract at government salary scales.
Organizational Resistance to Change
Long-established processes and work cultures don’t change easily. Staff comfortable with existing systems resist new approaches. Department silos impede cross-functional integration. Leadership turnover disrupts transformation momentum.
Change management becomes as important as technology selection. Without addressing the human side of transformation, even well-designed technical solutions fail to achieve expected benefits.
Qualité des données et problèmes d'intégration
Digital transformation depends on quality data, but municipal data often exists in siloed systems with inconsistent formats, definitions, and quality standards. Cleaning and integrating this data requires significant effort before analytics and automation can deliver value.
Risques liés à la cybersécurité
Digital transformation expands attack surfaces. More connected systems create more vulnerabilities. Cloud migration raises data sovereignty questions. IoT devices introduce new security challenges.
Municipalities must invest in cybersecurity alongside digital transformation rather than treating it as an afterthought. The sensitive data municipalities hold and the essential services they provide make them attractive targets.
Regulatory and Compliance Complexity
Municipal governments operate under complex regulatory requirements that complicate digital transformation. Data retention rules, public records laws, accessibility standards, and procurement regulations all constrain technology choices.
Solutions that work in the private sector may not comply with public sector requirements. Municipalities need careful legal review of digital initiatives.
Vendor Lock-In Concerns
Committing to proprietary platforms creates dependency on specific vendors. If that vendor raises prices, discontinues products, or fails to innovate, municipalities have limited recourse. Migration to alternative solutions becomes prohibitively expensive.
Open standards and interoperability principles help mitigate this risk but may limit feature availability or increase complexity.

Strategic Approaches to Municipal Digital Transformation
How should municipalities actually approach digital transformation? Research and practitioner experience point to several effective strategic frameworks:
The Micro-Transformation Framework
According to research presented at ICEGOV 2025, existing digital government models often assume levels of capacity, stability, and institutional readiness that many public administrations lack. The Micro-Transformation Framework responds to this gap by emphasizing sequenced, incremental changes.
Rather than attempting comprehensive transformation all at once, municipalities implement small, manageable changes that build capacity over time. Each micro-transformation delivers tangible value while developing organizational capabilities needed for more ambitious initiatives.
This approach proves particularly valuable for smaller municipalities or those with limited technical capacity. Success builds momentum and develops internal champions who drive further transformation.
Citizen-Centered Design Principles
Digital transformation should start from citizen needs rather than internal processes. What problems do residents actually face when interacting with their municipality? Where does friction occur? What outcomes matter most?
A growing number of scholars and practitioners recognize that value gets defined and co-created by citizens. Citizens must be involved in the service delivery process to improve the quality and efficacy of public services.
This service-oriented logic flips traditional government thinking. Instead of digitizing existing processes, municipalities redesign services around citizen journeys and desired outcomes.
Platform-Based Architecture
Rather than implementing disconnected point solutions, successful municipalities build on integrated platforms that share common infrastructure, data, and capabilities.
Platform approaches reduce redundancy, improve interoperability, and accelerate implementation of new services. Citizen identity management, payment processing, document management, and workflow orchestration become shared services that multiple departments leverage.
Agile, Iterative Implementation
Traditional waterfall project management—spending years planning before implementation begins—doesn’t work well for digital transformation. Requirements change. Technologies evolve. Organizational priorities shift.
Agile approaches deliver working functionality quickly, gather feedback, and iterate. Minimum viable products get deployed to real users who provide input shaping subsequent development. This reduces risk and ensures solutions actually meet needs.
Public-Private Partnerships
Many municipalities lack the internal capacity to drive digital transformation alone. Strategic partnerships with private sector technology providers, academic institutions, and non-profit organizations can accelerate progress.
These partnerships work best when they build municipal capacity rather than creating permanent dependency. Municipalities should retain control of core systems and data while leveraging external expertise for implementation and specialized capabilities.
Regional Collaboration and Shared Services
Smaller municipalities can achieve digital transformation more cost-effectively through regional cooperation. Shared platforms serve multiple jurisdictions. Common procurement reduces costs. Pooled technical staff provide expertise no single municipality could afford.
Regional approaches work particularly well for specialized capabilities like cybersecurity monitoring, advanced analytics, or emerging technologies like AI where single municipalities lack scale to justify investment.
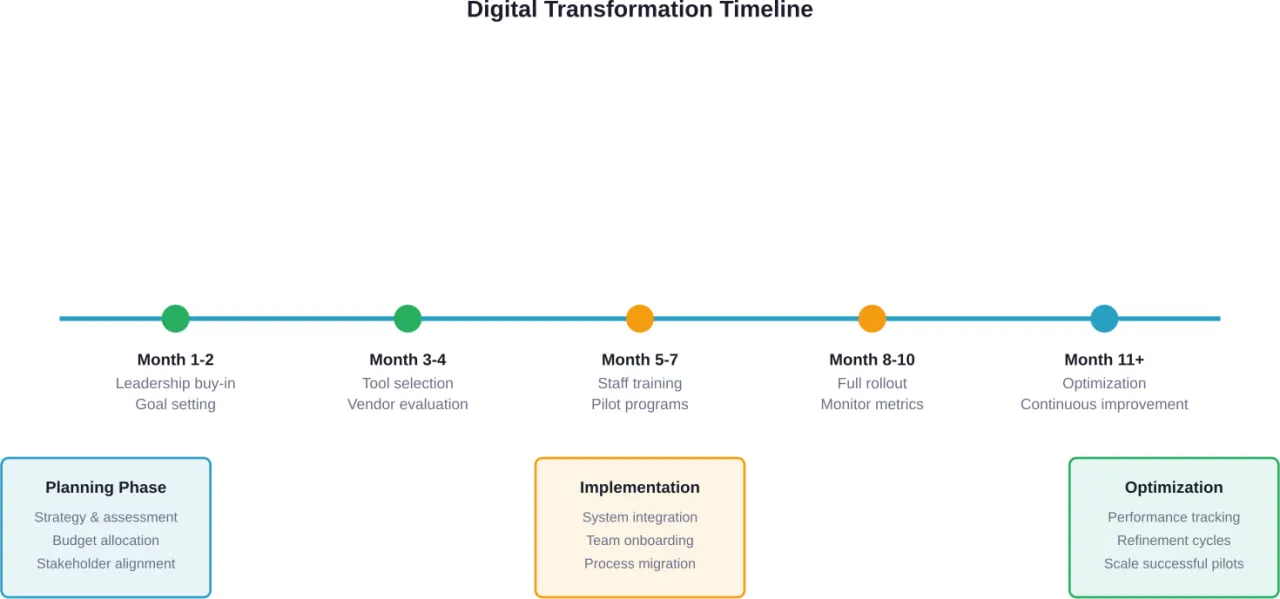
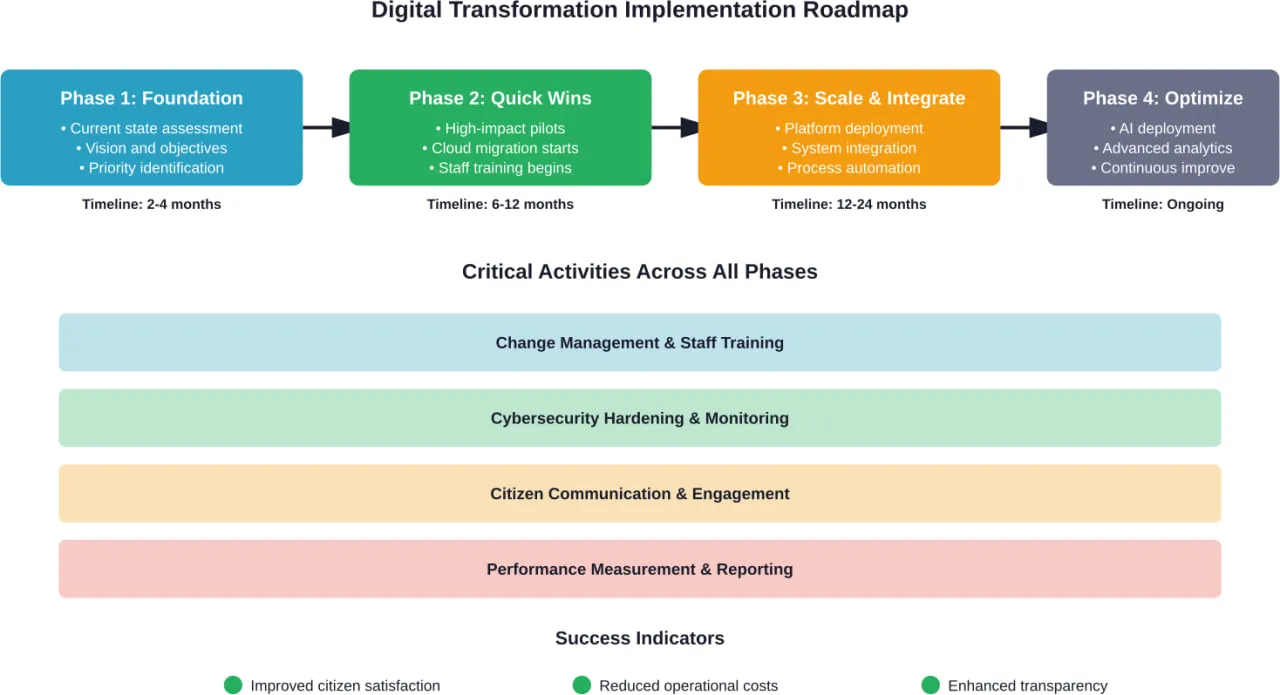
Building a Digital Transformation Roadmap
Successful digital transformation requires systematic planning. A well-designed roadmap provides direction while maintaining flexibility as circumstances change.
Étape 1 : Évaluer la situation actuelle
Where does the municipality currently stand in its digital maturity? What systems exist? What capabilities do they provide? Where are the gaps?
This assessment should cover technology infrastructure, workforce skills, organizational culture, budget availability, and citizen expectations. Honest evaluation of current state grounds realistic planning.
Step 2: Define Vision and Objectives
What should digital transformation achieve for this specific municipality? Goals need to be concrete and measurable rather than generic aspirations.
Objectives might include: reduce permit processing time by 50%, achieve 80% citizen satisfaction with online services, decrease operational costs by 20%, or eliminate paper from three high-volume processes.
Vision should connect to broader municipal strategic priorities rather than treating digital transformation as purely a technology initiative.
Step 3: Identify Priority Use Cases
Which specific services or processes should transform first? Prioritization criteria typically include:
- Citizen impact—high-volume services affecting many residents
- Feasibility—achievable within available resources and constraints
- Value—significant benefit relative to effort required
- Strategic alignment—supports broader organizational objectives
- Learning value—builds capabilities needed for subsequent initiatives
Early wins build momentum and demonstrate value to skeptics. But priorities should also include foundational investments that enable future capabilities even if they lack immediate visibility.
Step 4: Develop Implementation Plan
The roadmap should sequence initiatives across a multi-year timeline. Dependencies matter—some projects must complete before others can begin. Resource constraints limit how many initiatives can proceed simultaneously.
Plans should identify required funding, staffing, vendor support, training needs, and change management activities for each initiative. Realistic timelines account for procurement processes, budget cycles, and learning curves.
Step 5: Establish Governance Structure
Who makes decisions about digital transformation? How are priorities set and adjusted? How do departments coordinate? What approval processes apply?
Effective governance balances central coordination with departmental autonomy. Executive leadership provides strategic direction and resolves conflicts. Cross-functional teams manage implementation. Clear decision rights prevent paralysis.
Step 6: Implement, Measure, and Adapt
Execute the roadmap with regular progress reviews. Track metrics demonstrating whether initiatives achieve intended outcomes. Gather feedback from staff and citizens.
The roadmap isn’t a static document. As municipalities learn what works, as technology evolves, and as priorities shift, the plan should adapt. Flexibility matters more than rigid adherence to initial plans.
Change Management: The Human Side of Digital Transformation
Technology implementation represents only half the digital transformation challenge. The human dimension often determines success or failure.
Securing Executive Leadership Support
Digital transformation needs visible, active support from municipal leadership—city managers, mayors, department heads. Without executive sponsorship, initiatives stall when they encounter resistance or resource competition.
Leaders must communicate why transformation matters, what the municipality hopes to achieve, and how it aligns with community priorities. They need to model adoption of new technologies and processes.
Engaging Employees Early and Often
Staff who will use new systems daily should participate in design and implementation decisions. Their process knowledge proves invaluable. Their buy-in determines adoption success.
Change imposed from above without staff input generates resistance. Collaborative approaches that involve employees create advocates who help drive transformation forward.
Addressing Concerns Transparently
Digital transformation raises legitimate concerns about job security, skill requirements, and work changes. Acknowledging and addressing these concerns builds trust.
Will automation eliminate jobs? How will roles change? What training will be provided? What happens if someone can’t learn new systems? Clear, honest answers matter more than unrealistic reassurances.
Providing Adequate Training and Support
New technologies require new skills. Training can’t be an afterthought. Comprehensive onboarding, ongoing support, and opportunities to practice before go-live increase confidence and capability.
Different people learn differently. Some prefer hands-on practice. Others want reference documentation. Video tutorials help visual learners. Multiple training modalities reach more staff effectively.
Celebrating Wins and Learning from Setbacks
Recognition of successful implementations motivates continued effort. Highlighting staff who effectively adopt new approaches creates role models. Sharing positive citizen feedback demonstrates impact.
Setbacks inevitably occur. How the organization responds determines whether teams take appropriate risks or become paralyzed by fear of failure. Treating problems as learning opportunities rather than occasions for blame maintains momentum.
Specific Application Areas Delivering High Impact
While comprehensive transformation affects all municipal operations, certain application areas consistently deliver significant value:
Permitting and Licensing
Permit processes involve multiple reviews, complex rules, and coordination across departments. Digital transformation of permitting typically includes:
- Online application portals replacing paper forms
- Automated routing to appropriate reviewers
- Digital plan review replacing physical document markup
- Real-time status tracking visible to applicants
- Electronic payments and fee calculation
- Automated notifications at key process milestones
These improvements dramatically reduce processing times, improve applicant experience, and free staff from routine administrative tasks to focus on complex reviews requiring judgment.
Citizen Service Requests
Mobile apps and web portals let residents report potholes, request services, and track resolution. Digital service request systems provide:
- GPS-tagged submissions with photos
- Automatic routing to responsible departments
- Work order generation and assignment
- Status updates to requestors
- Analytics identifying problem patterns and response performance
Beyond improving individual request handling, aggregated data reveals systemic issues and helps prioritize preventive maintenance.
Financial Management and Transparency
Cloud-based financial systems integrate budgeting, accounting, procurement, and reporting. Open data portals publish budget information and spending in accessible formats. Citizens can see where tax dollars go and how spending compares to plans.
Digital procurement platforms increase competition, reduce processing time, and create audit trails that enhance accountability.
Infrastructure Asset Management
IoT sensors monitor infrastructure condition continuously. Predictive analytics forecast maintenance needs before failures occur. Digital twins—virtual replicas of physical assets—enable scenario modeling.
Asset management systems track maintenance history, calculate lifecycle costs, and optimize replacement timing. This data-driven approach prevents expensive emergency repairs and extends infrastructure lifespan.
Emergency Services and Public Safety
Computer-aided dispatch systems optimize emergency response. Mobile data terminals give first responders real-time information. Integrated systems coordinate across police, fire, and emergency medical services.
Predictive analytics help allocate resources based on anticipated demand patterns. Community alert systems rapidly disseminate critical information during emergencies.
Parks and Recreation
Online registration replaces paper forms and in-person signups. Digital facility booking shows real-time availability. Mobile apps provide trail maps and park information. Automated payment processing eliminates manual fee collection.
These improvements expand access—residents can register outside office hours—while reducing administrative workload.
Code Enforcement
Mobile apps let inspectors access property histories, file reports, and upload photos from the field. Workflow systems track cases from initial complaint through resolution. Analytics identify chronic violators and problem properties.
Digital systems ensure consistent application of codes and create comprehensive records supporting enforcement actions.
| Application Area | Key Digital Capabilities | Primary Benefits | Complexité de la mise en œuvre |
|---|
| Permitting & Licensing | Online portals, automated workflows, digital plan review | Faster processing, improved applicant experience | High (complex integrations) |
| Service Requests | Mobile apps, GPS tagging, automated routing | Better response tracking, data-driven improvements | Medium (requires mobile development) |
| Gestion financière | Cloud ERP, open data portals, e-procurement | Enhanced transparency, streamlined processes | High (mission-critical systems) |
| Gestion des actifs | IoT sensors, predictive analytics, digital twins | Preventive maintenance, extended asset life | High (sensor deployment, data integration) |
| Emergency Services | CAD systems, mobile terminals, predictive deployment | Faster response, better coordination | Very High (24/7 reliability requirement) |
| Parks & Recreation | Online registration, facility booking, mobile apps | Expanded access, reduced admin burden | Low to Medium (well-defined processes) |
Mesurer le succès de la transformation numérique
How do municipalities know if digital transformation initiatives are working? Clear metrics matter:
Service Delivery Metrics
- Processing time for common transactions
- First-contact resolution rates
- Service completion rates
- Channel shift (online vs. in-person transactions)
- Service availability (uptime/reliability)
Citizen Experience Metrics
- Satisfaction scores for digital services
- Net Promoter Score
- Digital service adoption rates
- Complaint volume and resolution
- Citizen engagement levels
Mesures d'efficacité opérationnelle
- Staff time per transaction
- Cost per service delivered
- Process automation percentage
- Error/rework rates
- Paper consumption reduction
Mesures financières
- Return on investment for initiatives
- Operating cost trends
- Revenue collection improvements
- Avoided costs from preventive maintenance
Workforce Metrics
- Employee satisfaction with digital tools
- Digital skill development
- Staff retention rates
- Time spent on high-value vs. routine tasks
Baseline measurements before transformation enable comparison showing actual impact. Regular tracking reveals whether initiatives deliver expected benefits and where adjustments are needed.
The Role of AI in Municipal Digital Transformation
Artificial intelligence represents both significant opportunity and considerable challenge for municipalities. Understanding realistic applications helps set appropriate expectations.
Current AI Applications in Local Government
Several AI applications have matured enough for municipal deployment:
- Chatbots and virtual assistants handle routine citizen inquiries, provide service information, and direct complex questions to appropriate staff. These systems operate 24/7 and respond instantly.
- Predictive maintenance models analyze sensor data and historical patterns to forecast when infrastructure components will likely fail, enabling proactive intervention.
- Applications de vision par ordinateur analyze images for code enforcement, infrastructure inspection, and traffic monitoring. Automated review identifies issues requiring human attention.
- Natural language processing extracts information from unstructured documents, categorizes service requests, and analyzes citizen feedback for sentiment and themes.
- Optimization algorithms improve routing for municipal fleets, facility scheduling, and resource allocation based on complex constraints and objectives.
AI Implementation Challenges
Despite promise, municipalities face significant obstacles scaling AI adoption:
As RAND research notes, state and local governments are experimenting with AI but lack systematic approaches to scale these efforts effectively. Current efforts remain piecemeal and slow.
Key challenges include:
- Data quality and availability requirements
- Explainability and transparency needs for public sector decisions
- Bias and fairness concerns in algorithmic systems
- Staff skills gaps in AI development and management
- Vendor evaluation and procurement complexity
- Policy and governance framework gaps
According to ICMA research, artificial intelligence is advancing across agencies faster than policies can be written. This creates tension between innovation and appropriate safeguards.
Responsible AI Principles for Municipalities
Municipalities deploying AI need clear principles ensuring responsible use:
- Transparence : Citizens should know when AI systems inform decisions affecting them and understand how those systems work.
- Fairness: AI systems must not discriminate based on protected characteristics. Regular audits should test for bias.
- Accountability: Human decision-makers remain responsible for outcomes even when AI systems provide recommendations.
- Privacy: AI training and deployment must protect personal information and comply with data protection regulations.
- Security: AI systems require robust protection against manipulation and adversarial attacks.
Regional Considerations: Digital Transformation in Smaller Municipalities
Digital transformation strategies must account for significant variations in municipal capacity, resources, and contexts.
Challenges Facing Smaller Municipalities
Communities under 50,000 population—the vast majority of US municipalities—face distinct challenges:
- Limited IT staff or no dedicated technology personnel
- Smaller budgets making major platform investments difficult
- Less vendor attention and fewer reference implementations
- Difficulty attracting specialized technical talent
- Lower digital literacy among some resident populations
Research on digital transformation in developing nations’ municipalities shows that lack of standardized principles presents particular problems for transitioning municipalities into data-driven organizations.
Strategies for Resource-Constrained Municipalities
Smaller municipalities can pursue digital transformation through adapted strategies:
- Regional shared services: Multiple municipalities jointly procure and operate common platforms, sharing costs and technical expertise.
- State-provided platforms: Some states offer digital government platforms that municipalities can adopt rather than building their own.
- Cloud-first approaches: Software-as-a-service eliminates infrastructure investment and shifts costs from capital to operating budgets.
- Incremental implementation: The micro-transformation framework particularly suits smaller municipalities, delivering value through manageable steps.
- Managed service providers: Outsourcing technical operations lets municipalities access expertise they can’t afford to employ directly.
- Peer learning networks: Organizations like ICMA facilitate knowledge sharing, helping municipalities learn from each other’s experiences.
Cybersecurity Considerations in Municipal Digital Transformation
Digital transformation expands cybersecurity exposure. Municipalities must address security proactively rather than reactively.
Common Threat Vectors
Municipalities face several cybersecurity threats:
- Attaques par ransomware encrypt municipal data and systems, demanding payment for restoration. These attacks can paralyze operations for weeks.
- Data breaches expose sensitive citizen information, creating privacy violations and liability.
- Distributed denial of service attacks overwhelm systems, making services unavailable to citizens.
- Insider threats from employees accidentally or maliciously compromising security.
- Supply chain compromises where vendors or their software introduce vulnerabilities.
Security-by-Design Principles
Effective cybersecurity gets built into digital transformation rather than added afterward:
- Zero-trust architecture: Verify every access request regardless of source. Never assume network location implies trustworthiness.
- Defense in depth: Multiple security layers ensure that single-point failures don’t compromise entire systems.
- Least privilege access: Grant users and systems only the minimum permissions required for their functions.
- Continuous monitoring: Automated systems detect anomalous behavior and potential threats in real time.
- Regular security audits: Independent assessment identifies vulnerabilities before attackers exploit them.
- Incident response planning: Clear procedures enable rapid, effective responses when breaches occur.
Cybersecurity Funding and Support
Federal programs recognize municipal cybersecurity needs. The State and Local Cybersecurity Grant Program provides funding support, though current authorization expires September 30, 2026.
Municipalities should pursue available grants while building cybersecurity into regular IT budgets rather than treating it as optional or one-time expense.

Looking Ahead: Future Trends in Municipal Digital Transformation
Several emerging trends will shape municipal digital transformation in coming years:
Increased AI Adoption
As AI technologies mature and municipalities develop governance frameworks, adoption will accelerate. More sophisticated applications will move from experimentation to production deployment.
However, scaling requires addressing current gaps in policy development, funding mechanisms, procurement processes, workforce capabilities, and safeguards.
5G and Enhanced Connectivity
Fifth-generation wireless networks enable new applications requiring high bandwidth and low latency. Real-time video analytics, autonomous vehicles, and dense IoT sensor networks become more feasible.
Municipalities will need to balance benefits against infrastructure investment requirements and ensure equitable access across communities.
Digital Twins for Urban Planning
Virtual replicas of cities enable scenario modeling before making physical changes. Planners can test traffic patterns, simulate development impacts, and optimize infrastructure investments in digital space first.
These capabilities require substantial data integration and computational resources but promise improved decision-making for major investments.
La blockchain au service de la confiance et de la transparence
Distributed ledger technologies offer tamper-proof records for land titles, permits, licenses, and contracts. Smart contracts automate enforcement of agreed-upon terms.
Real-world municipal blockchain adoption remains limited, but pilot programs continue exploring applications where cryptographic verification adds value.
L'informatique en périphérie pour le traitement en temps réel
Processing data at the network edge—near where it’s generated—reduces latency and bandwidth requirements. Traffic systems, emergency response, and infrastructure monitoring benefit from immediate analysis rather than cloud round-trips.
Edge architectures add complexity but enable applications where split-second decisions matter.
Greater Regional Collaboration
Shared platforms and services will expand as municipalities recognize economies of scale. Regional approaches become more common for specialized capabilities and expensive infrastructure.
This trend particularly benefits smaller municipalities accessing capabilities they couldn’t justify individually.
Questions fréquemment posées
- What’s the difference between digitization and digital transformation in local government?
Digitization simply converts analog information to digital format—like scanning paper documents into PDFs. Digital transformation fundamentally reimagines how municipalities operate and deliver services using digital technologies. It changes processes, workflows, and organizational culture rather than just creating digital copies of existing paper-based systems.
- How long does municipal digital transformation typically take?
Digital transformation is an ongoing journey rather than a project with a fixed endpoint. Initial quick wins can occur within 6-12 months. Foundational platform implementations typically require 12-24 months. Comprehensive transformation spanning multiple departments and systems evolves over 3-5 years. The timing depends heavily on scope, available resources, organizational complexity, and existing technology baseline.
- What budget should municipalities allocate for digital transformation?
Budget requirements vary dramatically based on municipality size, current technology state, and transformation ambitions. Generally speaking, municipalities should expect to invest 3-5% of operating budgets in technology, with digital transformation initiatives requiring additional investment during implementation years. Cloud-based software-as-a-service models shift spending from large capital investments to ongoing operational expenses, making transformation more accessible for budget-constrained municipalities.
- How can small municipalities with limited IT staff pursue digital transformation?
Smaller municipalities can successfully transform through several strategies: participating in regional shared service arrangements, adopting cloud platforms that eliminate infrastructure management, leveraging state-provided digital government services, using managed service providers for technical operations, following micro-transformation frameworks that implement changes incrementally, and joining peer learning networks to benefit from other municipalities’ experiences. These approaches make digital transformation feasible without large internal IT departments.
- What security risks does digital transformation create for municipalities?
Digital transformation expands cybersecurity exposure through increased connectivity, cloud data storage, IoT device proliferation, and integrated systems. Key threats include ransomware attacks that encrypt critical systems, data breaches exposing citizen information, denial-of-service attacks disrupting services, insider threats from employees, and supply chain compromises through vendors. Municipalities must implement zero-trust security architectures, continuous monitoring, regular audits, and incident response planning alongside transformation initiatives.
- How do municipalities ensure digital equity while pursuing transformation?
Digital equity requires intentional strategies alongside digital transformation. Municipalities should maintain alternative channels for residents without internet access or digital skills, provide public access points with internet and assistance, design services for accessibility by people with disabilities, offer multilingual interfaces serving diverse populations, conduct digital literacy training programs, and partner with community organizations reaching underserved populations. Digital services should expand rather than limit access to government.
- What role should citizens play in municipal digital transformation?
Citizen involvement proves critical for successful transformation. Residents should participate in needs assessment identifying service friction points, user testing of digital interfaces before launch, feedback collection after implementation, co-creation of service designs, and oversight ensuring transparency and accountability. This citizen-centered approach ensures digital transformation actually addresses real needs rather than implementing technology for technology’s sake.
Conclusion: Taking the First Steps Toward Transformation
Digital transformation offers municipalities substantial opportunities to improve service delivery, increase operational efficiency, enhance transparency, and better serve their communities. But the path forward requires realistic planning, sustained commitment, and careful attention to both technology and human factors.
Successful transformation doesn’t require being first or most ambitious. It requires understanding where your municipality currently stands, defining clear objectives aligned with community priorities, and systematically building capabilities over time.
Start with assessment. What are the biggest pain points in current operations? Where do citizens express frustration? Which processes waste the most staff time? What data could inform better decisions if it were accessible?
Focus on achievable wins that build momentum and demonstrate value. A successful pilot creates advocates. Documented benefits secure funding for subsequent phases. Visible improvements build staff confidence in transformation.
Address the human dimension as seriously as technology. Change management, training, communication, and stakeholder engagement determine whether digital transformation succeeds or stalls. Technology is the easy part. Organizational change is where most initiatives struggle.
Remember that digital transformation is a journey, not a destination. Technologies evolve. Citizen expectations rise. New opportunities emerge. Municipalities that build capacity for continuous adaptation position themselves to thrive regardless of how the digital landscape changes.
The question isn’t whether municipalities should pursue digital transformation. It’s how to do so effectively given unique constraints and capabilities. With thoughtful strategy, realistic expectations, and sustained commitment, municipalities of all sizes can harness digital technologies to better serve their communities.
Ready to begin your municipality’s digital transformation journey? Start by assessing your current state, engaging stakeholders across your organization, and identifying one high-impact area where digital capabilities could deliver clear benefits. That first step begins a transformation that will reshape how your municipality serves its community for years to come.