Короткий виклад: AI agent performance analysis requires tracking metrics across four key dimensions: technical performance (task completion, latency, accuracy), business impact (ROI, operational cost reduction), safety and compliance (hallucination rates, security incidents), and user experience (satisfaction scores, adoption rates). According to research from Stanford and MIT, well-implemented agents achieve 85-95% task completion for structured tasks, though evaluation remains challenging with 95% of AI investments producing no measurable return due to inadequate measurement frameworks.
Building AI agents has become remarkably fast. Some teams now deploy functional agents in weeks. But here’s the catch—speed means nothing if the agent doesn’t deliver measurable value.
The real challenge isn’t building agents anymore. It’s proving they work.
According to research cited in industry analysis, organizations often struggle to demonstrate measurable returns from AI investments. Not because the technology fails, but because organizations can’t track what success actually looks like. Research indicates that AI evaluation often overemphasizes technical metrics relative to user-centered and economic factors.
This imbalance creates serious problems. Technical teams celebrate low latency while business leaders wonder where the ROI went. Safety teams flag edge cases that never get prioritized. Users abandon agents that technically “work” but feel clunky.
Why Traditional Metrics Don’t Work for AI Agents
AI agents aren’t traditional software. They operate with inherent variability—the same input can produce different outputs. They make autonomous decisions, call tools, and handle multi-step workflows.
This introduces failure modes that traditional error tracking can’t detect. Hallucinated tool calls. Infinite loops. Inappropriate actions that are technically successful but contextually wrong.
Standard uptime monitoring won’t catch an agent that responds quickly with completely wrong information. Error rates don’t reveal an agent that completes tasks but takes five times longer than a human would.
The Four Core Dimensions of AI Agent Performance
Effective agent evaluation requires a balanced framework. According to research from Stanford’s Digital Economy Lab and the National Institute of Standards and Technology (NIST), which recently announced the AI Agent Standards Initiative in February 2026, comprehensive evaluation spans four critical dimensions.
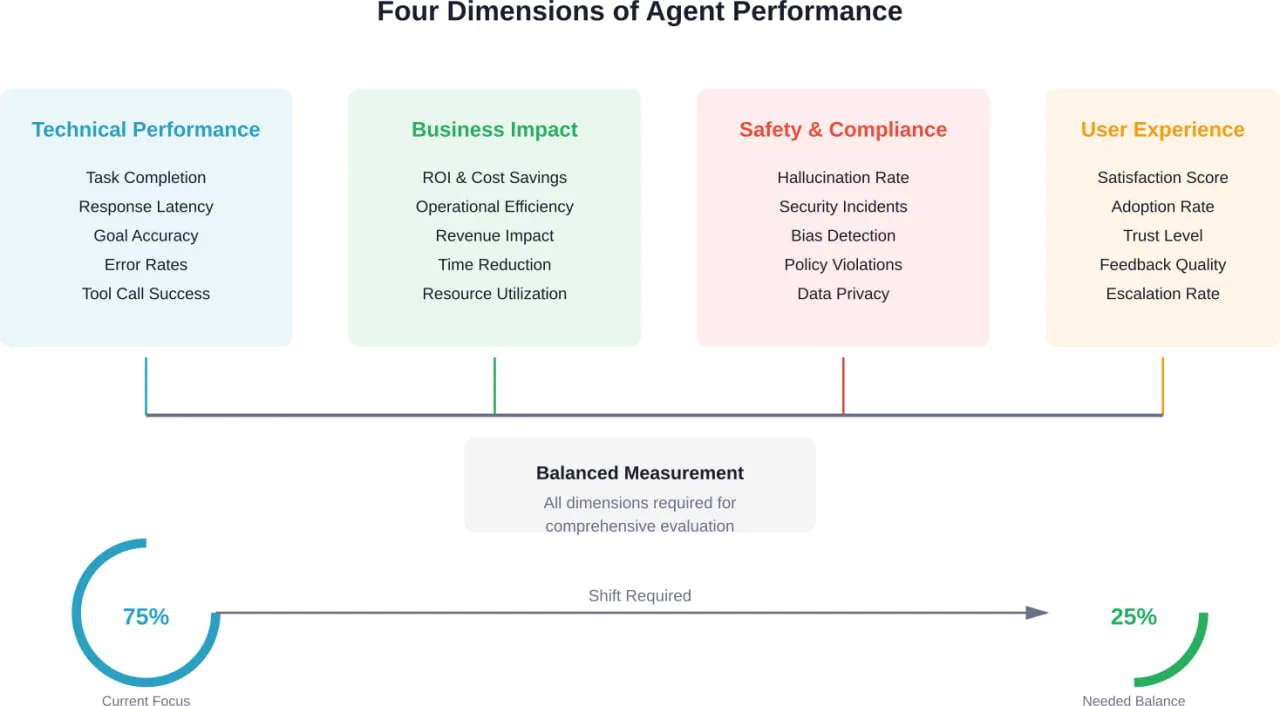
Each dimension addresses different stakeholder needs. Technical teams need operational metrics. Business leaders need financial justification. Compliance teams need safety assurance. End users need practical reliability.
Essential Technical Performance Metrics
Technical metrics form the foundation. They measure whether the agent executes its core functions reliably.
Task Completion Rate
This measures the percentage of tasks an agent finishes without human intervention. Industry data shows well-implemented agents achieve 85-95% autonomous completion for structured tasks.
But task completion alone doesn’t tell the full story. An agent might complete 90% of tasks while taking twice as long as necessary or making critical errors along the way.
Goal Accuracy
Goal accuracy measures whether agents achieve intended outcomes, not just task completion. This primary metric should benchmark at 85%+ for production agents. Anything below 80% indicates significant problems requiring immediate attention.
The distinction matters. An agent can complete a task (execute all steps) without achieving the goal (produce the correct outcome).
Response Latency and Throughput
Speed directly impacts user experience. Agents handling customer requests need sub-second response times for simple queries. Complex multi-step workflows might take longer, but users need visibility into progress.
Throughput measures how many requests an agent handles concurrently. Production agents typically need to scale to hundreds or thousands of simultaneous operations.
Tool Call Success Rate
Modern agents interact with external tools, APIs, and databases. Each integration point introduces potential failure. Tracking successful versus failed tool calls reveals integration reliability.
According to research published on arXiv analyzing LLM agent evaluation, tool use errors represent a significant failure mode. Hallucinated tool calls—where agents attempt to use non-existent functions—appear frequently in poorly-configured systems.
Error Classification and Recovery
Not all errors carry equal weight. A formatting error differs vastly from a security violation. Effective monitoring categorizes errors by severity and tracks recovery success.
Can the agent detect its own errors? Does it retry appropriately? Does it escalate to humans when needed? Recovery capability often matters more than raw error rates.
| Метрика | Target Range | Warning Threshold | Critical Threshold |
|---|---|---|---|
| Task Completion Rate | 85-95% | <85% | <75% |
| Goal Accuracy | 85%+ | <85% | <80% |
| Response Latency (simple) | <1 second | >2 seconds | >5 seconds |
| Response Latency (complex) | <10 seconds | >20 seconds | >30 seconds |
| Tool Call Success | 95%+ | <90% | <85% |
| Error Recovery Rate | 80%+ | <70% | <60% |
Business Impact Metrics That Drive Decisions
Technical excellence means nothing if the business can’t justify the investment. According to industry surveys, technology leaders view performance quality as a significant concern, but business stakeholders need financial proof.
Return on Investment and Cost Savings
ROI calculation for AI agents requires tracking both direct and indirect costs. Direct costs include infrastructure, API calls, and development time. Indirect costs include monitoring overhead, error correction, and maintenance.
Savings come from reduced labor costs, faster processing times, and improved accuracy. Research from Berkeley’s School of Information emphasizes that ROI tracking should account for the full agent lifecycle, not just initial deployment.
Підвищення операційної ефективності
How much faster does work get done? How many hours of human labor get redirected to higher-value tasks?
Effective measurement compares agent performance against baseline human performance for the same tasks. Teams that deploy agents for invoice processing, customer service, or data entry typically report 60-80% time reduction once agents reach production maturity.
Revenue Impact and Conversion Optimization
For customer-facing agents, revenue impact matters most. Does the agent increase conversion rates? Does it reduce cart abandonment? Does it upsell effectively?
E-commerce agents handling product recommendations should track click-through rates, add-to-cart rates, and purchase completion. Customer service agents should monitor resolution rates and customer lifetime value changes.
Resource Utilization and Scaling Costs
AI agents consume computational resources. Token usage for LLM calls, API rate limits, database queries, and processing time all contribute to operating costs.
Production systems need detailed cost tracking per task, per user, and per time period. This granularity enables optimization—identifying expensive operations, inefficient prompts, or unnecessary tool calls.
Safety and Compliance Metrics
Safety failures can destroy trust instantly. According to research from Stanford and Princeton on establishing rigorous agentic benchmarks, safety evaluation should be systematic and continuous, not a one-time checkpoint.
Hallucination Detection and Measurement
Hallucinations—when agents generate plausible but incorrect information—represent one of the most dangerous failure modes. In high-stakes domains like finance, a benchmark study found that state-of-the-art models still make critical errors in adversarial environments.
The CAIA benchmark, which tests AI agents in financial markets, revealed significant gaps where models achieve only 12-28% accuracy on tasks junior analysts routinely handle. In 2024 alone, over $30 billion was lost to exploits and scams in cryptocurrency markets.
Measuring hallucination rates requires human evaluation, automated fact-checking against ground truth, and user feedback loops. Production systems should track hallucination frequency per task type and severity level.
Security Incident Tracking
Agents interact with sensitive systems. They access databases, call APIs, and handle user data. Each interaction point represents a potential security vulnerability.
The Cybersecurity AI Benchmark (CAIBench), a meta-benchmark for evaluating cybersecurity AI agents, emphasizes systematic offensive-defensive evaluation. Research shows state-of-the-art AI models reach approximately 70% success on security knowledge metrics but degrade substantially to 20-40% success in multi-step adversarial scenarios., indicating substantial room for improvement.
Security metrics should track unauthorized access attempts, data leakage incidents, prompt injection successes, and policy violations. Zero tolerance thresholds apply—even single incidents require investigation.
Bias Detection and Fairness Evaluation
AI agents can perpetuate or amplify biases present in training data. For customer-facing applications, biased behavior creates legal liability and reputational damage.
Fairness evaluation requires testing agent responses across demographic groups, use cases, and edge cases. The StereoSet dataset, developed by McGill NLP researchers, provides standardized bias measurement frameworks that test for race, gender, profession, and religion stereotypes.
Privacy Preservation and Data Handling
Agents process user data to complete tasks. That data needs protection. Privacy metrics track data retention periods, encryption usage, anonymization effectiveness, and compliance with regulations like GDPR or CCPA.
The CAIBench includes privacy-preserving performance assessment through its CyberPII-Bench component, which evaluates agent handling of personally identifiable information.
User Experience and Adoption Metrics
Technical excellence and business value mean nothing if users won’t use the agent. User experience metrics reveal whether agents deliver practical value in real-world conditions.
User Satisfaction and Net Promoter Score
Direct user feedback provides irreplaceable insight. Post-interaction surveys, satisfaction ratings, and Net Promoter Scores (NPS) quantify user sentiment.
Production systems should collect feedback at multiple touchpoints—after task completion, during extended interactions, and through periodic surveys. Satisfaction targets typically aim for 4+ out of 5 or 70%+ positive ratings.
Adoption Rate and Active Usage
How many intended users actually use the agent? How frequently? Adoption metrics reveal whether agents provide enough value to change user behavior.
Low adoption despite good technical metrics indicates UX problems, insufficient training, or misaligned use cases. High initial adoption with declining usage suggests early enthusiasm followed by disappointment.
Trust Indicators and Escalation Patterns
Do users trust agent outputs? Escalation rates—how often users ask for human verification or override agent decisions—reveal trust levels.
Healthy escalation rates vary by domain. High-stakes decisions (medical diagnoses, financial transactions) should have higher escalation rates than low-stakes tasks (scheduling, data entry).
Feedback Quality and Actionability
User feedback quality matters as much as quantity. Detailed feedback enables specific improvements. Generic “doesn’t work” reports provide limited value compared to “failed to process invoices with international currency codes.”
Systems should capture structured feedback—what task was attempted, what went wrong, what the user expected, and how critical the failure was.
Building a Measurement Framework
Individual metrics provide data points. A framework connects them into actionable intelligence.
Establishing Baseline Performance
Effective measurement requires baselines. What’s the current performance without the agent? How do humans perform the same tasks?
Baseline establishment should capture:
- Current task completion time and cost
- Human error rates and types
- User satisfaction with existing processes
- Operational costs and resource utilization
These baselines enable meaningful comparison and ROI calculation.
Setting Realistic Benchmarks and Goals
According to research from NIST’s AI Risk Management Framework, goal-setting should balance ambition with realism. Aiming for 99.9% accuracy on day one sets teams up for failure.
Phased goals work better. Initial deployment might target 70% task completion with human oversight. Mature systems gradually increase autonomy as reliability improves.
The FinGAIA benchmark, an end-to-end evaluation for AI agents in finance, demonstrates realistic goal-setting. Each task in that benchmark required approximately 90 minutes for manual design and annotation, reflecting the complexity of high-quality evaluation.
Implementing Continuous Monitoring
One-time evaluation isn’t enough. Agent performance shifts as data distributions change, edge cases emerge, and underlying models update.
Production monitoring should be continuous and automated. Real-time dashboards track key metrics. Automated alerts flag anomalies. Regular audits catch drift before it becomes critical.
Creating Feedback Loops for Improvement
Measurement without action wastes resources. Effective frameworks close the loop—metrics inform decisions, decisions drive improvements, improvements get measured again.
According to OpenAI’s evaluation best practices, teams should establish regular review cycles. Weekly reviews for critical metrics. Monthly deep dives into user feedback. Quarterly reassessment of goals and benchmarks.
Evaluation Methods and Testing Strategies
Different evaluation methods serve different purposes. Production monitoring catches live issues. Offline testing validates changes before deployment. Benchmark datasets enable standardized comparison.
Online Evaluation with Production Data
Online evaluation monitors live agent performance with real users. This provides the most accurate view of actual performance but carries risk—errors affect real users.
According to the Langfuse evaluation cookbook for agents, online evaluation should include:
- Real-time metric tracking for all interactions
- User feedback collection mechanisms
- Automated anomaly detection and alerting
- Session replay for debugging problematic interactions
Production data reflects reality. Edge cases that never appear in test datasets surface constantly. User behavior patterns shift. Online evaluation captures this variability.
Offline Evaluation with Benchmark Datasets
Offline evaluation uses curated datasets with known correct answers. This enables controlled testing without risk to users.
The Agentic Benchmark Checklist (ABC), synthesized from benchmark-building experience and best practices, provides guidelines for rigorous offline evaluation. When applied to CVE-Bench, a benchmark with particularly complex evaluation requirements, ABC improved reliability significantly.
Offline datasets should include:
- Representative task samples covering common scenarios
- Edge cases and known failure modes
- Adversarial examples testing robustness
- Ground truth labels for automated scoring
LLM-as-Judge Evaluation
LLM-as-judge evaluation uses one language model to evaluate another’s output. This approach scales efficiently and handles subjective quality assessment that automated metrics struggle with.
According to research from Stanford’s Digital Economy Lab, using an LLM as a judge means evaluating output quality based on specific criteria. This provides scalable, fast quality control for systems like chatbots or content generators.
But LLM judges have limitations. They can perpetuate biases. They sometimes disagree with human evaluators. They work best when combined with other evaluation methods.
The WebJudge framework, developed by researchers and referenced in Berkeley’s School of Information research, provides deeper feedback for agentic runs. It demonstrated >85% concordance between WebJudge and human evaluation when using OpenAI’s o4-mini model.
Human Evaluation and Expert Review
Automated metrics can’t capture everything. Human evaluation remains essential for:
- Subjective quality assessment (helpfulness, clarity, tone)
- Complex reasoning validation
- Safety and ethical considerations
- New failure mode discovery
Human evaluation costs more and scales worse than automation. Strategic use focuses human review on areas where automated metrics provide insufficient signal.
| Evaluation Method | Найкраще для | Limitations | Typical Frequency |
|---|---|---|---|
| Online Production | Real-world performance, user behavior | Risk to users, hard to isolate variables | Continuous |
| Offline Benchmark | Controlled testing, regression detection | May not reflect reality, static datasets | Before each deploy |
| LLM-as-Judge | Subjective quality, scale | Potential bias, disagreement with humans | Daily to weekly |
| Human Review | Nuanced assessment, safety | Expensive, slow, doesn’t scale | Weekly to monthly |
Common Challenges in Agent Performance Measurement
Even with good frameworks, evaluation faces persistent challenges. Understanding them enables better solutions.
Handling Variability and Non-Determinism
Language models are non-deterministic. The same input can produce different outputs. This makes traditional software testing inadequate.
Evaluation must account for acceptable variation. A customer service agent might answer the same question multiple ways—all correct but differently phrased.
Techniques for handling variability include:
- Semantic similarity scoring instead of exact matching
- Multiple reference answers for comparison
- Confidence intervals instead of point estimates
- Aggregation across multiple runs
Evaluating Multi-Step Reasoning and Tool Use
Modern agents perform complex multi-step workflows. They break problems into subtasks, call tools, and chain operations together.
Evaluating intermediate steps matters as much as final outcomes. An agent might reach the correct answer through flawed reasoning—a problem that manifests later when contexts shift.
The Very Large-Scale Multi-Agent Simulation framework in AgentScope demonstrates evaluation complexity for multi-agent systems. Enhancements to the platform improve scalability and ease of use for large-scale simulations through distributed architecture.
Balancing Automation with Human Oversight
Full automation enables scale but misses nuance. Full human review captures nuance but can’t scale.
Effective approaches blend both. Automated metrics flag potential issues. Human reviewers investigate flagged cases. Edge cases inform automated metric improvements.
Domain-Specific Evaluation Requirements
Different domains have different requirements. Financial agents need extreme accuracy. Customer service agents need empathy and tone management. Code generation agents need functional correctness.
The FinGAIA benchmark demonstrates domain-specific evaluation for finance agents. All tasks were formulated through discussions with financial experts, and each question required approximately 90 minutes for complete design, annotation, and verification.
Generic evaluation frameworks need domain customization. What counts as “good” varies dramatically across use cases.
Tools and Platforms for Agent Evaluation
Multiple platforms now provide agent evaluation infrastructure. Capabilities vary significantly.
Langfuse for Observability and Testing
Langfuse provides comprehensive tracing and evaluation for LLM applications and agents. It captures internal agent steps, enabling detailed performance analysis.
The platform supports both online production monitoring and offline dataset evaluation. Teams use it to compare prompt variants, track costs, and identify performance regressions.
Weights & Biases for Experiment Tracking
Weights & Biases (W&B) offers experiment tracking, model evaluation, and visualization. Teams use it to compare agent configurations, track metrics over time, and share results across organizations.
W&B integrates with common agent frameworks, enabling automated metric logging and visualization without custom instrumentation.
OpenAI Evals for Standardized Testing
OpenAI’s Evals framework provides standardized evaluation templates and datasets. It enables consistent testing across model versions and configurations.
According to OpenAI’s evaluation best practices documentation, teams should use a mix of production data and expert-created datasets. For summarization tasks, implementations should achieve a ROUGE-L score of at least 0.40 and coherence score of at least 80% using G-Eval on held-out sets.
Custom Evaluation Pipelines
Some teams build custom evaluation infrastructure. This provides maximum flexibility but requires significant engineering investment.
Custom pipelines make sense when:
- Domain requirements don’t fit existing tools
- Integration with proprietary systems is critical
- Scale exceeds commercial platform limits
- Regulatory requirements mandate specific controls
Make Your AI Agent Metrics Actually Useful
Performance metrics only matter if the system behind them is reliable. In practice, issues often come from how data is collected, how services interact, and whether the backend can support consistent measurement over time.
A-listware works on that layer with dedicated development teams. The focus is on backend systems, integrations, and infrastructure that support stable data flow and reporting, so performance metrics reflect real conditions rather than partial results. Contact Програмне забезпечення списку А to support system setup and keep your metrics accurate in production.
Future Directions in Agent Evaluation
Agent evaluation continues evolving as agents become more capable and widespread.
Standardization Efforts and Industry Benchmarks
NIST’s AI Agent Standards Initiative, announced in February 2026, aims to ensure next-generation AI is widely adopted with confidence, functions securely, and interoperates smoothly across the digital ecosystem.
This initiative represents growing recognition that standardized evaluation frameworks benefit the entire industry. Consistent benchmarks enable meaningful comparison and accelerate improvement.
Adversarial Testing and Red Teaming
As agents handle higher-stakes tasks, adversarial testing becomes critical. The CAIA benchmark exposes a critical blind spot in AI evaluation—inability to operate in adversarial, high-stakes environments where misinformation is weaponized and errors are costly.
Research shows significant gaps in adversarial robustness. Agents that perform well in benign conditions often fail dramatically when facing intentional manipulation.
Multi-Agent System Evaluation
Many production systems now use multiple agents collaborating. The TradingAgents framework demonstrates multi-agent LLM systems for stock trading, simulating real-world trading firms.
Multi-agent evaluation requires new metrics—coordination effectiveness, communication overhead, emergent behaviors, and system-level outcomes beyond individual agent performance.
Continuous Learning and Adaptation Metrics
Static agents will give way to systems that learn from interactions. Evaluation must track learning effectiveness—how quickly agents improve, whether improvements generalize, and if adaptation introduces new failure modes.
Поширені запитання
- What’s the single most important metric for AI agent performance?
There isn’t one. Goal accuracy (85%+ for production agents) provides the best single technical metric, but comprehensive evaluation requires balancing technical performance, business impact, safety, and user experience. According to research, 83% of evaluation focuses on technical metrics while only 30% considers user-centered or economic factors—this imbalance causes problems. The most important metric depends on your agent’s purpose and stakeholders.
- How often should AI agents be evaluated in production?
Continuously. Critical metrics should be monitored in real-time with automated alerting for anomalies. Weekly reviews should analyze trends and user feedback. Monthly deep dives should examine edge cases and failure modes. Quarterly assessments should reevaluate goals and benchmarks. The Langfuse evaluation framework recommends this cadence for production systems handling significant user volume.
- What’s a realistic task completion rate for a new AI agent?
Industry data shows well-implemented agents achieve 85-95% autonomous completion for structured tasks. But new agents typically start lower—60-70% is common during initial deployment with human oversight. As teams refine prompts, improve error handling, and expand training data, completion rates increase. Anything below 75% for mature production agents indicates significant problems requiring attention.
- How do you measure ROI for AI agents?
Track both costs (infrastructure, API calls, development time, monitoring overhead, maintenance) and benefits (reduced labor costs, faster processing, improved accuracy, revenue impact). Many organizations report reaching positive ROI within several months as cumulative savings exceed development and operational costs. Calculate cost per task completed and compare against human baseline. Include both direct financial impact and indirect benefits like employee satisfaction from eliminating tedious work.
- What’s the difference between task completion and goal accuracy?
Task completion measures whether the agent finishes all steps. Goal accuracy measures whether it achieves the intended outcome. An agent can complete a task (execute all operations) without achieving the goal (produce the correct result). For example, an agent might successfully query a database, process results, and format output (100% task completion) but return irrelevant information due to query construction errors (0% goal accuracy). Goal accuracy should benchmark at 85%+ for production systems.
- How do you evaluate subjective qualities like agent helpfulness or tone?
Combine LLM-as-judge evaluation with human review and user feedback. LLM-as-judge approaches scale efficiently—using one language model to evaluate another’s output based on specific criteria. But they need validation against human judgments. User satisfaction surveys, Net Promoter Scores, and qualitative feedback capture subjective experience. For tone-sensitive applications like customer service, expert human evaluation of a representative sample (100-500 interactions monthly) provides ground truth for calibrating automated scoring.
- What tools exist for monitoring AI agent performance?
Several platforms provide agent evaluation infrastructure. Langfuse offers comprehensive tracing and evaluation with support for both online monitoring and offline testing. Weights & Biases provides experiment tracking and visualization across configurations. OpenAI’s Evals framework offers standardized templates and datasets. Many teams also build custom pipelines when domain requirements don’t fit existing tools or when integration with proprietary systems is critical. The best choice depends on agent complexity, scale, and team expertise.
Висновок
AI agent performance analysis isn’t optional anymore—it’s the difference between successful deployment and expensive failure.
The metrics that matter span four dimensions. Technical performance ensures agents execute reliably. Business impact justifies investment. Safety and compliance prevent catastrophic failures. User experience drives adoption.
No single metric captures everything. Balanced evaluation frameworks combine automated monitoring, offline testing, user feedback, and expert review. They establish baselines, set realistic goals, track continuously, and close feedback loops.
According to MIT research, 95% of AI investments produce no measurable return. Not because the technology doesn’t work, but because organizations can’t prove it does. Rigorous performance analysis changes that equation.
Start with goal accuracy and task completion rates—these provide immediate signal. Expand to business metrics that stakeholders care about. Layer in safety guardrails and user experience tracking. Build incrementally rather than trying to measure everything at once.
The agent evaluation landscape continues evolving. NIST’s standardization efforts, emerging benchmarks like FinGAIA and CAIA, and new frameworks like the Agentic Benchmark Checklist indicate growing maturity.
Organizations that master agent performance measurement will deploy AI confidently, optimize systematically, and scale successfully. Those that don’t will struggle to justify investments, miss critical failures, and watch adoption stagnate despite technical capability.
The challenge isn’t building agents anymore. It’s proving they work, keeping them working, and making them better. That requires measurement—comprehensive, continuous, and connected to decisions.
Ready to evaluate your agents properly? Start by identifying the three metrics that matter most to your key stakeholders. Implement monitoring for those metrics first. Expand from there. Measurement doesn’t have to be perfect from day one. It just needs to start.


