Короткий виклад: Фреймворки агентів ШІ забезпечують базову інфраструктуру для побудови автономних систем ШІ, які можуть сприймати, міркувати та діяти. Провідні фреймворки, такі як LangGraph, CrewAI та Microsoft Agent Framework, пропонують різні архітектури - від керованої оркестрації на основі графів до систем спільної роботи з декількома агентами - кожна з яких підходить для конкретних випадків використання, від простої автоматизації завдань до складних корпоративних робочих процесів.
Перехід від традиційних великих мовних моделей до автономних ШІ-агентів є однією з найбільш значущих трансформацій у штучному інтелекті. Але ось агенти, що створюють речі, які дійсно працюють на виробництві, вимагають чогось більшого, ніж просто з'єднання декількох викликів API.
Агентні фреймворки з'явилися саме для вирішення цієї проблеми. Вони надають архітектурні шаблони, інструменти оркестрування та можливості інтеграції, необхідні для перетворення експериментальних прототипів на надійні системи. Згідно з дослідженням, опублікованим на arXiv, ці фреймворки функціонують як “операційна система” для агентів, зменшуючи рівень галюцинацій, перетворюючи неструктурований чат на чіткі робочі процеси.
Ландшафт кардинально змінився. Те, що починалося з експериментальних проектів на кшталт AutoGPT, перетворилося на платформи корпоративного рівня, що підтримують все - від автоматизації обслуговування клієнтів до складних багатоагентних систем ланцюгів поставок. І відмінності між фреймворками мають більше значення, ніж більшість розробників можуть собі уявити.
Цей посібник відсікає зайвий ажіотаж. Ніяких вигадок, ніяких вигаданих критеріїв - лише практичний аналіз, заснований на тому, що насправді потрапляє у виробництво.
Чим відрізняються фреймворки агентів штучного інтелекту
Традиційні LLM-додатки працюють за простим шаблоном: вхідні дані надходять, відповідь виходить. Агенти повністю ламають цю модель.
Фреймворк агентів ШІ забезпечує інфраструктуру для систем, які можуть сприймати навколишнє середовище, приймати автономні рішення, використовувати інструменти, підтримувати стан під час взаємодії та виконувати багатокрокові робочі процеси. Згідно з дослідженням arXiv, яке відрізняє агентів ШІ від агентного ШІ, ці фреймворки є “модульними системами, керованими LLM” з принципово іншою філософією дизайну, ніж у простих чат-ботів.
Основні компоненти, як правило, включають
- Механізми оркестрування, які керують життєвими циклами агентів і виконанням завдань
- Системи пам'яті для короткочасного та довготривалого збереження стану
- Інструментальні рівні інтеграції, які дозволяють агентам взаємодіяти із зовнішніми системами
- Цикли міркувань, які дозволяють планувати та самокоректуватися
- Протоколи мультиагентної координації для спільних робочих процесів
Але не всі фреймворки реалізують ці компоненти однаково. Деякі з них надають перевагу управлінню станами на основі графів, інші зосереджуються на розмовних потоках, а деякі спеціалізуються на мультиагентній оркестровці.
Питання архітектури, яке визначає все
Згідно з таксономією варіантів архітектури для агентів на основі фреймворків arXiv, фундаментальний вибір архітектури визначає все, що відбувається далі. Фреймворки зазвичай поділяються на три категорії:
- Системи на основі графів станів розглядають виконання агента як орієнтований граф, де вузли представляють стани або дії. Цей підхід чудово справляється зі складними робочими процесами з умовним розгалуженням, паралельним виконанням та явним управлінням станами.
- Розмовні фреймворки моделюють агентів як вдосконалених чат-ботів з доступом до інструментів. Вони добре підходять для клієнтських додатків, де природний діалог має більше значення, ніж складна оркестровка.
- Мультиагентні системи розподіляють завдання між спеціалізованими агентами, які спілкуються та співпрацюють. Дослідження показують, що цей патерн особливо добре працює для моделювання організаційних структур, таких як ChatDev, що імітує цілу софтверну компанію, де агенти самоорганізовуються в ролі дизайнерів, програмістів і тестувальників.
Вибір архітектури - це не просто технічні переваги. Він фундаментально обмежує те, які типи додатків стають природними, а які - болючими для створення.
Фреймворки виробничого класу, на які варто звернути увагу
Існує безліч агентських фреймворків. Більшість з них не витримують контакту з виробничими вимогами. Ось ті, що витримують, на основі реального досвіду розгортання, задокументованого в екосистемі.
LangGraph: Коли державне управління має значення
LangGraph підходить до оркестрування агентів за допомогою графів, наповнених станами. Кожна вершина представляє функцію, ребра визначають переходи, а потоки станів проходять через граф з явною сталістю.
Фреймворк має 24,8 тис. зірок на GitHub і щомісяця отримує 34,5 млн завантажень - цифри, які відображають справжнє впровадження у виробництво, а не просто експериментальний інтерес. Згідно з аналізом практиків, які працювали з кількома фреймворками, LangGraph знаходиться у верхньому ешелоні систем, які виживають у виробництві.
Основні можливості включають в себе:
- Явне керування станами з конфігурованим бекендом персистентності
- Робочі процеси з людиною в циклі з воротами узгодження
- Підтримка як одноагентних, так і багатоагентних архітектур
- Налагодження подорожей у часі за допомогою знімків стану
- Вбудована потокова підтримка оновлень у режимі реального часу
Компроміс? LangGraph вимагає більш завчасного архітектурного мислення. Розробники повинні явно моделювати переходи станів, а не покладатися на неявний діалоговий потік. Для складних корпоративних робочих процесів з розгалуженою логікою та вимогами до відновлення після помилок така явність стає перевагою.
Реальна розмова: LangGraph найкраще працює, коли проблемна область має чіткі стани та переходи. Робочі процеси ескалації підтримки клієнтів, багатоетапні процеси затвердження та дослідницькі конвеєри з умовним розгалуженням - все це природно відображається на парадигмі графів.
CrewAI: мультиагентна співпраця на практиці
CrewAI спеціалізується на координації декількох агентів, які працюють над досягненням спільних цілей. Фреймворк моделює агентів як членів команди з визначеними ролями, обов'язками та схемами комунікації.
Основна абстракція зосереджена на “екіпажах” - групах агентів, які співпрацюють над завданнями. Кожен агент має роль, мету, інструменти, які він може використовувати, та передісторію, яка впливає на його поведінку. Завдання призначаються агентам на основі їхніх можливостей, а фреймворк керує міжагентною комунікацією.
Цей підхід підходить для завдань, які природним чином розкладаються на спеціалізовані ролі. Робочі процеси створення контенту можуть мати агента-дослідника, агента-письменника та агента-редактора. У фінансовому аналізі можуть бути задіяні агенти зі збору даних, агенти з аналізу та агенти зі звітності.
CrewAI підтримує кілька моделей співпраці:
- Послідовне виконання, коли агенти працюють один за одним
- Ієрархічні структури з делегуванням повноважень менеджерами спеціалістам
- Механізми консенсусу, коли кілька агентів голосують за рішення
Цей фреймворк часто з'являється в рейтингах найкращих агентних фреймворків на 2026 рік, особливо для випадків використання, що вимагають сегрегації доменної експертизи. Але він несе більше накладних витрат на оркестровку, ніж одноагентні системи - підходить для складних робочих процесів, а для простої автоматизації є надмірним.
Microsoft Agent Framework: Інтеграція на рівні підприємства в першу чергу
Microsoft Agent Framework використовує інший підхід, надаючи пріоритет вимогам підприємства, таким як безпека, відповідність вимогам та інтеграція з існуючими екосистемами Microsoft.
Згідно з офіційною документацією, Microsoft Agent Framework підтримує створення агентів і багатоагентних робочих процесів як в .NET, так і в Python. Він включає вбудовану інтеграцію з Azure OpenAI, OpenAI, Anthropic та Ollama, а також власну підтримку серверів Model Context Protocol (MCP).
Ключові особливості підприємства включають
| Особливість | Опис |
|---|---|
| Агенти | Індивідуальні агенти, що використовують LLM для обробки вхідних даних, інструменти виклику та сервери MCP, генерують відповіді |
| Робочі процеси | Мультиагентна оркестрація з визначеними залежностями між завданнями |
| Підтримка MCP | Вбудована інтеграція з Model Context Protocol для стандартизованого доступу до інструментів |
| Безпека | Автентифікація, авторизація та ведення журналів аудиту корпоративного рівня |
Фреймворк орієнтований на організації, які вже інвестували в екосистему Microsoft. Для команд, які використовують інфраструктуру Azure та сервіси штучного інтелекту від Microsoft, тертя інтеграції значно зменшуються. Для всіх інших проблеми, пов'язані з прив'язкою до певного постачальника, потребують ретельної оцінки.
AutoGen: Дослідження назустріч виробництву
AutoGen, розроблений дослідницькою групою Microsoft, фокусується на діалогових мультиагентних системах. Фреймворк дозволяє агентам вести діалоги один з одним для спільного вирішення завдань.
Особливістю AutoGen є його діалогова парадигма. Замість того, щоб явно моделювати робочі процеси або переходи станів, розробники визначають агентів з можливостями і дозволяють їм домовлятися про виконання завдань через діалог. Це особливо добре працює для відкритих проблем, де шлях вирішення не визначений заздалегідь.
Фреймворк підтримує:
- Автоматизована генерація та виконання коду
- Використання інструментів через виклик функцій
- Моделі взаємодії "людина в циклі
- Налаштовувані шаблони розмов та умови завершення
За словами практиків, які працювали з кількома фреймворками, AutoGen добре підходить для створення прототипів. Діалоговий підхід може ускладнити налагодження складних робочих процесів, коли агенти приймають несподівані рішення.
ШІ Pydantic: безпека типу для розробки агентів
Pydantic AI привносить в розробку агентів безпеку типів і можливості валідації Pydantic. Для команд, які вже використовують Pydantic для перевірки даних у додатках на Python, цей фреймворк надає знайомі патерни.
Основна ціннісна пропозиція зосереджена на структурованих результатах. Розробники визначають схеми Pydantic, що описують очікувані реакції агента, а фреймворк обробляє валідацію та примус до типу. Це зменшує проблему галюцинацій, обмежуючи вихідні дані відповідно до очікуваних структур.
Добре працює для..:
- Задачі вилучення даних з визначеними схемами виводу
- Робочі процеси класифікації та категоризації
- Створення структурованих звітів
- Будь-який випадок використання, коли формат виводу має таке ж значення, як і вміст
Обмеження? Pydantic AI залишається переважно орієнтованим на сценарії з одним агентом і структурованими результатами. Складна багатоагентна оркестрація або робочі процеси, що вимагають складного управління станом, потребують додаткових інструментів.
Firecrawl: Збір веб-даних в якості агента
Firecrawl використовує спеціалізований підхід, зосереджуючись саме на зборі веб-даних через агентський інтерфейс. Замість того, щоб створювати універсальних агентів, він оптимізується під загальний шаблон пошуку, навігації та вилучення структурованих даних з веб-сайтів.
Згідно з проектною документацією, розробники описують те, що вони хочуть, простим текстом, за бажанням передають схему Pydantic, а агент здійснює пошук, навігацію і повертає структуровані результати. Firecrawl пропонує кілька моделей з різним співвідношенням продуктивності та вартості для простого та складного вилучення.
Така спеціалізація означає, що Firecrawl найкраще справляється з однією задачею - збором веб-даних - замість того, щоб намагатися підтримувати всі можливі варіанти використання агента. Для команд, які створюють дослідницькі агенти, системи конкурентної розвідки або інструменти моніторингу ринку, така спеціалізація має значну цінність.
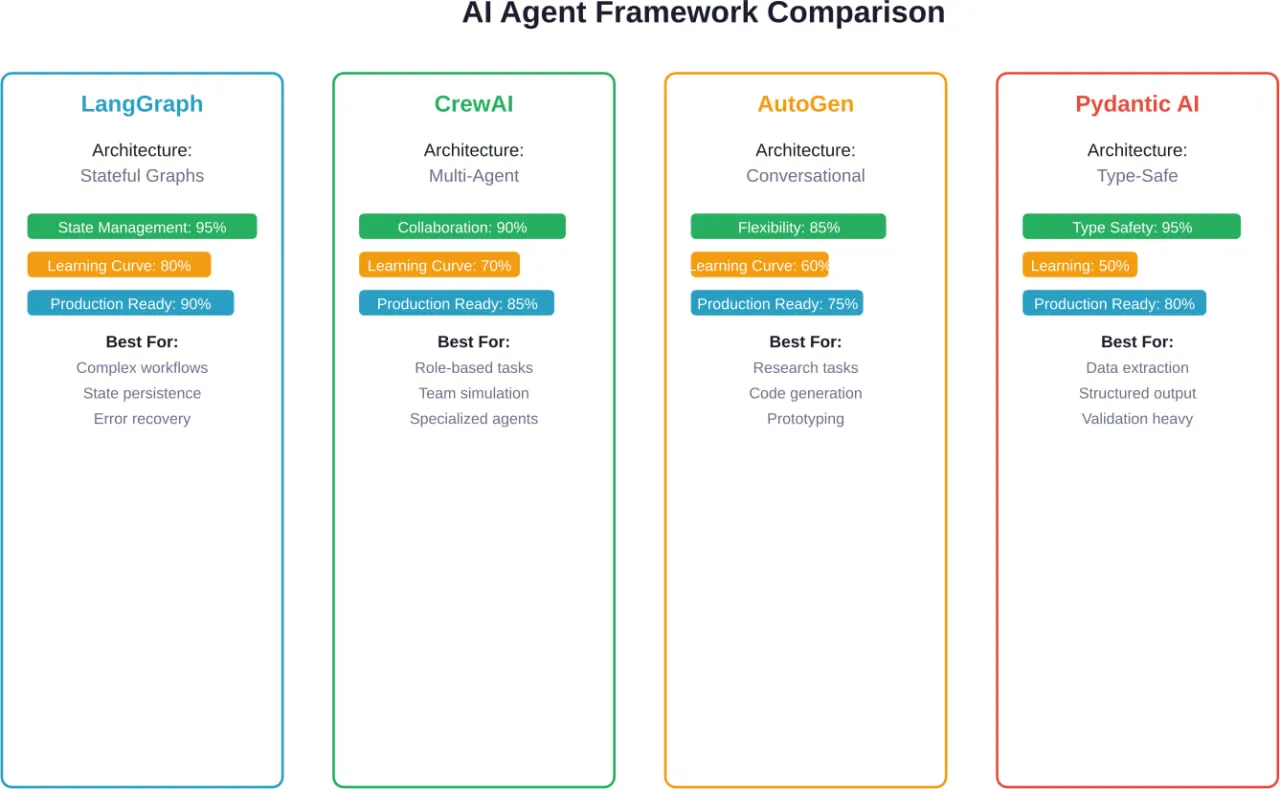
Критерії вибору фреймворку, які дійсно мають значення
Вибір агентського фреймворку на основі зірок GitHub або хайп-циклів призводить до дорогих переробок. Фреймворки, які працюють у продакшені, обирають за іншими критеріями.
Узгодження архітектури з проблемною областю
Перше питання не “який фреймворк найкращий?”. А “чи відповідає архітектура цього фреймворку тому, як ця проблема природно декомпозується?”
Проблеми з чіткими переходами станів, умовними розгалуженнями та вимогами до відновлення помилок природно відображаються на фреймворки на основі графів, такі як LangGraph. Явне керування станами відповідає структурі задачі.
Завдання, що вимагають спеціалізованої експертизи в різних сферах - створення контенту, фінансовий аналіз, дослідження клієнтів - добре вирішуються за допомогою мультиагентних фреймворків, таких як CrewAI. Рольова модель агентів відображає те, як людські команди вирішують ці проблеми.
Відкриті дослідницькі завдання або робочі процеси генерації коду часто краще підходять для діалогових фреймворків, таких як AutoGen. Шлях до рішення з'являється через діалог, а не через заздалегідь визначені робочі процеси.
Видобування даних і створення структурованого виводу узгоджується з фреймворками з безпечним типом, такими як Pydantic AI. Підхід "спочатку схема" зменшує галюцинації для завдань, де формат має значення.
Згідно з дослідженням arXiv, присвяченим варіантам архітектури агентів на основі фундаментальних моделей, ця відповідність між проблемною областю та архітектурною парадигмою є найбільш важливим фактором довгострокового успіху.
Виробничі вимоги виходять за рамки базової функціональності
Експериментальні прототипи та виробничі системи мають принципово різні вимоги. Фреймворки повинні підтримувати:
- Спостережливість: Чи можуть розробники бачити, що роблять агенти, чому вони приймають рішення і де відбуваються збої? Виробничі системи потребують детального логування, трасування та налагодження.
- Обробка помилок: Як фреймворк обробляє збої API, обмеження швидкості, тайм-аути і невірні результати роботи інструментів? Надійне відновлення помилок відокремлює іграшки від інструментів.
- Державна наполегливість: Чи може стан агента пережити перезапуск процесу? Чи зберігаються розмови між сеансами? Виробничі системи потребують тривалого управління станом.
- Контроль витрат: Чи надає фреймворк механізми для обмеження використання токенів, лімітування викликів API та запобігання виконанню, що вибігає з-під контролю? Неконтрольовані агенти швидко стають дорогими.
- Кордони безпеки: Як фреймворк працює з автентифікацією, авторизацією та пісочницею? Агенти з доступом до інструментів потребують контролю безпеки.
Ці вимоги не відображаються у порівнянні фреймворків, зосереджених на функціях. Але вони визначають, чи виживуть агенти у виробництві.
Інтеграційна екосистема та інструментальна підтримка
Агенти отримують вигоду від доступу до інструментів. Фреймворк повинен інтегруватися з конкретними інструментами та сервісами, яких потребує додаток.
Деякі фреймворки надають широкі готові інтеграції. Інші пропонують гнучкі механізми визначення інструментів, але вимагають написання власного інтеграційного коду. Компроміс між зручністю та гнучкістю залежить від того, чи вже існують необхідні інтеграції.
Згідно з дослідженням arXiv, присвяченим фреймворкам агентного ШІ, протокол Model Context Protocol (MCP) стає рівнем стандартизації для доступу до інструментів. Фреймворки з вбудованою підтримкою MCP отримують доступ до зростаючої екосистеми сумісних інструментів без спеціальної інтеграції.
Командні навички та крива навчання
Різні фреймворки вимагають різних ментальних моделей. Графові системи вимагають роздумів про машини станів і переходи. Мультиагентні системи потребують розуміння протоколів зв'язку та моделей координації. Діалогові фреймворки потребують різних підходів до налагодження.
Крива навчання має менше значення для нових проектів, ніж для команд, які підтримують існуючі системи. Перехід на інший фреймворк в середині проекту рідко має сенс, незалежно від того, який фреймворк виглядає краще. Витрати на міграцію зазвичай перевищують вигоду.
Для команд, які вже інвестували в певні екосистеми - Microsoft Azure, LangChain, Pydantic - фреймворки, які відповідають наявним навичкам, значно зменшують тертя.
Зусилля зі стандартизації змінюють ландшафт
Поширення несумісних фреймворків агентів створює проблеми фрагментації. Зусилля зі стандартизації спрямовані на вирішення цієї проблеми.
Ініціатива NIST зі стандартизації агентів ШІ
17 лютого 2026 року Національний інститут стандартів і технологій (NIST) оголосив про створення Ініціативи стандартів агентів ШІ для забезпечення надійних, інтероперабельних і безпечних агентних систем ШІ. Згідно з офіційною заявою, ініціатива “забезпечить широке впровадження наступного покоління ШІ з упевненістю, безпечне функціонування від імені своїх користувачів і безперебійну взаємодію в цифровій екосистемі”.”
Це перша велика державна спроба встановити стандарти для архітектур агентів, протоколів безпеки та механізмів інтероперабельності. Ініціатива спрямована на усунення занепокоєння щодо агентських систем, які працюють без узгодженої системи безпеки або стандартів інтероперабельності.
Стандарти IEEE для бенчмаркінгу агентів
Стандарт IEEE P3777 встановлює уніфіковану структуру для порівняльного аналізу агентів ШІ, включаючи автономні, спільні та спеціалізовані агенти. Він визначає основні показники продуктивності, протоколи оцінювання та вимоги до звітності, щоб забезпечити прозору, відтворювану і порівнянну оцінку потужностей і можливостей агентів.
Окремо IEEE P3154.1 надає рекомендовану практику для фреймворку при застосуванні агентів ШІ для талант-сервісів, описуючи архітектурні фреймворки і домени додатків з протоколами для взаємодії і механізмами зв'язку.
Ці зусилля зі стандартизації продовжують активно розвиватися. Але вони свідчать про визнання галуззю того, що фрагментація фреймворків створює проблеми для розгортання виробництва та впровадження на підприємствах.
Розуміння архітектури агентів та патернів проектування
Окрім конкретних фреймворків, в успішних реалізаціях агентів з'являються повторювані архітектурні патерни. Розуміння цих патернів допомагає оцінювати фреймворки та розробляти власні рішення.
Цикл "Сприйняття-Пізнання-Дія
Згідно з дослідженням arXiv, яке відрізняє ШІ-агентів від агентного ШІ, агенти в основі своєї роботи проходять цикл сприйняття-пізнання-дія. Сприйняття передбачає збір інформації з навколишнього середовища. Пізнання охоплює міркування, планування та прийняття рішень. Дія виконує рішення через використання інструментів або комунікацію.
Різні фреймворки реалізують цей цикл по-різному:
- Графові фреймворки роблять цикл явним через переходи станів
- Розмовні фреймворки вбудовують цикл у діалогові репліки
- Мультиагентні системи розподіляють цикл між спеціалізованими агентами
Вибір реалізації впливає на налагоджуваність, характеристики продуктивності та режими збоїв. Явні цикли легше налагоджувати, але вони вимагають більш ретельного проектування. Неявні цикли зменшують шаблонність, але ускладнюють відстеження потоку керування.
Архітектури пам'яті для стану агента
Агентам потрібна пам'ять, щоб підтримувати контекст взаємодії. Архітектури пам'яті зазвичай включають:
- Робоча пам'ять: Короткостроковий контекст для поточного завдання або розмови
- Епізодична пам'ять: Записи про минулі взаємодії та їхні результати
- Семантична пам'ять: Загальні знання та вивчені факти
- Процедурна пам'ять: Як виконувати завдання та користуватися інструментами
Виробничі фреймворки повинні зберігати пам'ять між сеансами і витончено поводитися з обмеженнями пам'яті. У міру того, як розмова розростається, агенти повинні підсумовувати, забувати несуттєві деталі або відновлювати відповідний історичний контекст.
Деякі фреймворки надають вбудоване управління пам'яттю. Інші надають розробникам можливість реалізовувати механізми збереження та пошуку.
Використання інструментів та шаблони виклику функцій
Доступ до інструментів перетворює агентів з чат-ботів на системи, що приймають рішення. Поширені патерни включають:
- Прямий виклик функцій: LLM генерує структуровані виклики функцій з параметрами, фреймворк виконує їх, а результати повертаються агенту. Це добре працює для детермінованих інструментів з чіткими схемами.
- Описи інструментів природною мовою: Інструменти надають описи можливостей природною мовою. Агент вирішує, коли і як їх використовувати, спираючись на описи, а не на жорсткі схеми. Більш гнучко, але менш надійно.
- Ланцюгове виконання інструментів: Агенти можуть використовувати результати роботи інструментів як вхідні дані для наступних інструментів. Уможливлює складні робочі процеси на кшталт “знайдіть X, прочитайте перший результат, підсумуйте його, а потім перекладіть французькою”.”
- Паралельний виклик інструментів: Одночасне виконання декількох незалежних інструментів. Зменшує затримку для завдань, що потребують інформації з декількох джерел.
Різні фреймворки підтримують ці шаблони з різним рівнем вбудованої підтримки та користувацької реалізації.
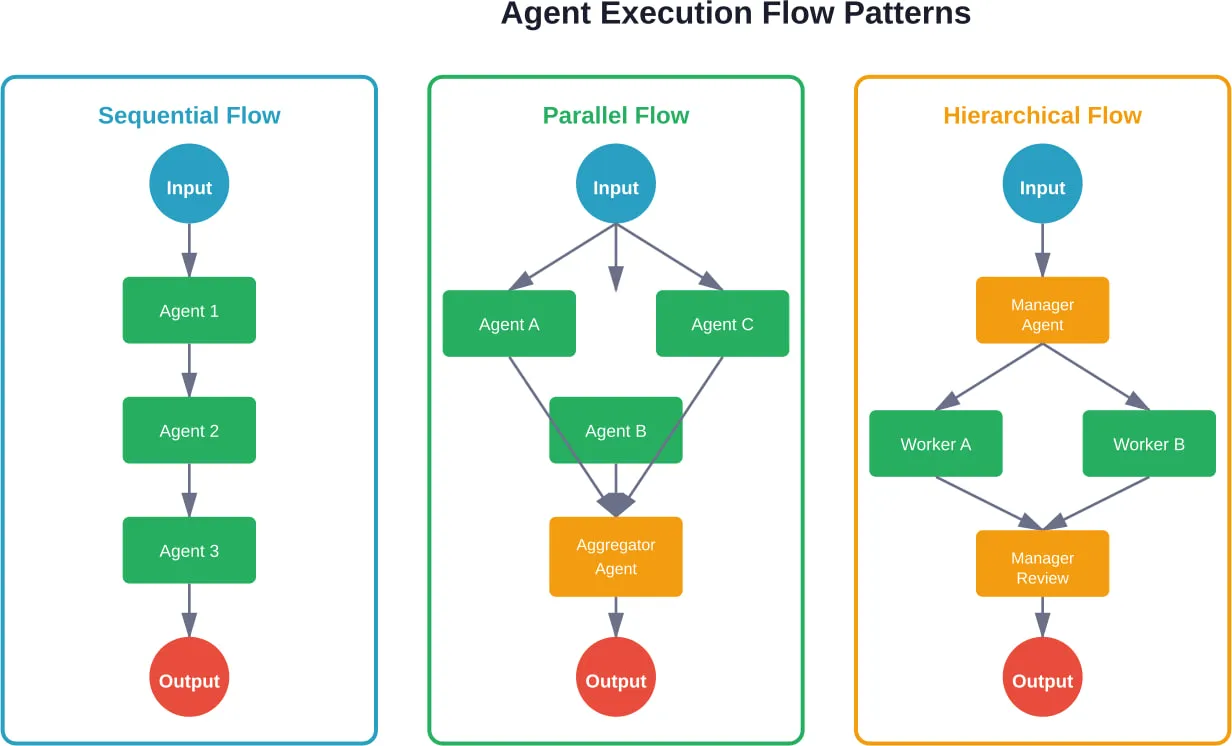
Багатоагентні протоколи зв'язку
Коли кілька агентів співпрацюють, протоколи зв'язку визначають ефективність і надійність. Згідно з дослідженням arXiv, присвяченим фреймворкам агентного ШІ, найпоширеніші протоколи включають в себе:
- Передача повідомлення: Агенти спілкуються за допомогою чітких повідомлень з визначеними схемами. Забезпечує чіткі аудиторські сліди, але вимагає попередньої розробки протоколу.
- Спільна держава: Агенти читають і записують до спільної пам'яті або баз даних. Проста в реалізації, але створює потенційні умови для перегонів та конфліктів.
- Залежно від подій: Агенти публікують події та підписуються на події інших агентів. Роз'єднує агентів, але робить загальну поведінку важче передбачуваною.
- Ієрархічне делегування: Агенти-менеджери призначають завдання агентам-робітникам та узагальнюють результати. Чіткий потік управління, але створює вузькі місця у вузлах менеджерів.
Вибір протоколу впливає на складність налагодження, відновлення після збоїв та характеристики масштабованості. Виробничі системи часто потребують декількох протоколів для різних моделей взаємодії.
Міркування підприємства та розгортання виробництва
Перехід агентів від прототипу до виробництва пов'язаний з проблемами, що виходять за рамки вибору фреймворку. Розгортання на підприємстві вимагає вирішення проблем, пов'язаних з експлуатацією, безпекою та управлінням.
Управління витратами та токенова економіка
Агенти з доступом до інструментів і багатокроковими міркуваннями споживають значно більше токенів, ніж прості чат-боти. Агент служби підтримки може використовувати 10 000+ токенів за одну взаємодію при пошуку в базах знань, перевірці статусу замовлення та генеруванні відповідей.
Виробничі системи потребують:
- Бюджет токенів на кожну взаємодію, щоб запобігти непередбачуваним витратам
- Стратегії кешування для повторюваних запитів або загальних робочих процесів
- Логіка вибору моделі, яка використовує дешевші моделі для простих завдань
- Моніторинг та сповіщення, коли витрати перевищують порогові значення
Деякі фреймворки мають вбудовані засоби контролю витрат. Інші вимагають індивідуальної реалізації бюджетного контролю та модельної маршрутизації.
Межі безпеки та контроль доступу
Агенти з доступом до інструментів діють від імені користувачів. Збої в системі безпеки можуть призвести до витоку конфіденційних даних або уможливити несанкціоновані дії.
Критичні вимоги до безпеки включають:
- Аутентифікація для перевірки особи агента та авторизації користувача
- Авторизація для обмеження доступу агентів до інструментів для певних користувачів
- Перевірка вводу для запобігання швидким ін'єкційним атакам
- Фільтрація вихідних даних для запобігання витоку конфіденційної інформації
- Аудиторський лог всіх дій агентів та викликів інструментів
- Пісочниця для ізоляції виконання агента від критичних систем
Згідно з Ініціативою NIST щодо стандартів ШІ-агентів, стандартизовані протоколи безпеки для агентів все ще перебувають на стадії розробки. Поточні фреймворки реалізують безпеку з різним рівнем складності.
Спостережуваність та налагодження
Коли агенти виходять з ладу, розуміння причин вимагає детального спостереження. На відміну від традиційного програмного забезпечення, де проблеми можна виявити за допомогою трасування стеку, збої в роботі агентів часто пов'язані з семантичними проблемами - агент неправильно зрозумів намір, отримав невірну інформацію або зробив неправильний вибір інструменту.
Для цього потрібна спостережливість виробництва:
- Детальне протоколювання міркувань та рішень агентів
- Відстеження викликів інструментів із входами, виходами та затримками
- Можливості відтворення сесії для відтворення збоїв
- Показники успішності, затримок і витрат на взаємодію
- Інтеграція з існуючою інфраструктурою моніторингу
Фреймворки суттєво відрізняються за підтримкою спостережуваності. Деякі з них надають багаті інструменти налагодження та інтеграцію з платформами спостережливості. Інші залишають інструментарій розробникам.
Оцінка та забезпечення якості
Традиційне тестування програмного забезпечення не перекладається безпосередньо на агентів. Детерміновані модульні тести не можуть перевірити системи, які використовують LLM для міркувань.
Згідно з дослідженнями фреймворку AutoChain, для оцінювання потрібні фреймворки автоматизованого тестування, які оцінюють можливості агентів у різних сценаріях роботи користувачів. Це включає в себе:
- Тестування на основі сценаріїв з реалістичними користувацькими даними
- Оцінювачі, які оцінюють якість продукції, що випускається
- Регресійне тестування для виявлення деградації можливостей
- A/B-тестування для порівняння конфігурацій агентів
- Людська оцінка для суб'єктивного оцінювання якості
Лише деякі фреймворки надають комплексні інструменти для оцінювання. Більшість виробничих систем потребують спеціальних тестових джгутів.
Нові тенденції та майбутні напрямки
Ландшафт фреймворку агентів продовжує стрімко розвиватися. Кілька тенденцій визначають, куди рухається екосистема.
Прийняття типового контекстного протоколу
Протокол Model Context Protocol (MCP) має на меті стандартизувати доступ агентів до інструментів та зовнішніх систем. Замість того, щоб кожен фреймворк реалізовував власну інтеграцію інструментів, MCP надає загальний протокол.
Фреймворки з вбудованою підтримкою MCP отримують доступ до зростаючої екосистеми сумісних інструментів без інтеграції з конкретним фреймворком. Це зменшує одне з головних джерел прив'язки до фреймворку - перехід між фреймворками стає простішим, коли інтеграція інструментів базується на протоколах, а не на специфіці фреймворку.
Спеціалізовані фреймворки для вертикальних доменів
Універсальні фреймворки, такі як LangGraph та CrewAI, працюють у різних доменах. Але з'являються спеціалізовані фреймворки, орієнтовані на конкретні вертикалі.
Зосередженість Firecrawl на зборі веб-даних відображає цю тенденцію. Замість того, щоб підтримувати всі можливі варіанти використання агента, він оптимізується для одного домену і робить це добре.
Очікуйте більше вертикально-специфічних фреймворків для таких сфер, як підтримка клієнтів, аналіз даних, створення контенту та розробка програмного забезпечення. Спеціалізовані фреймворки можуть робити виважений архітектурний вибір, який покращує досвід розробників для їхньої цільової області.
Краще оцінювання та порівняльний аналіз
Згідно зі стандартом IEEE P3777, галузь визнає необхідність стандартизованого бенчмаркінгу агентів. Поточні підходи до оцінки залишаються спеціальними та непослідовними.
Удосконалення методології оцінювання дозволить це зробити:
- Об'єктивне порівняння фреймворків
- Виявлення регресії, коли оновлення фреймворку впливають на можливості
- Оптимізація продуктивності на основі вимірюваних показників
- Перевірка відповідності для регульованих галузей
Системи, які інтегрують стандартизовані інструменти оцінювання, швидше за все, будуть швидше впроваджуватися на підприємствах.
Інтеграція з традиційною програмною інженерією
Наразі розробка агентів часто відчувається відокремленою від традиційної програмної інженерії. Різні інструменти, різні підходи до тестування, різні моделі розгортання.
Тенденція рухається до інтеграції. Агенти як компоненти більших систем, а не як окремі додатки. Це вимагає:
- Агентські фреймворки, які інтегруються з існуючими конвеєрами CI/CD
- Тестувальні фреймворки, сумісні зі стандартними тестовими бігунами
- Шаблони розгортання, які працюють з платформами оркестрування контейнерів
- Моніторинг, який інтегрується з існуючими стеками спостережень
Фреймворки, які зменшують невідповідність імпедансу між розробкою агентів і традиційною програмною інженерією, набудуть популярності в корпоративних середовищах.
Стратегія вибору практичних рамок
Враховуючи складність та швидку еволюцію, як командам насправді обирати фреймворки? Ось практичний процес прийняття рішення.
Почніть з аналізу архітектури варіантів використання
Перш ніж оцінювати фреймворки, зіставте сценарій використання з архітектурними патернами:
- Чи пов'язана проблема зі складним державним управлінням з умовним розгалуженням? Розглянемо фреймворки на основі графів.
- Чи потрібна співпраця кількох спеціалізованих агентів? Розгляньте мультиагентні фреймворки.
- Чи є це в першу чергу діалоговим доступом до інструментів? Розглянемо діалогові фреймворки.
- Чи структура виводу має таке ж значення, як і вміст? Розглянемо фреймворки з безпечною типізацією.
- Чи орієнтований він на збір веб-даних? Розгляньте спеціалізовані фреймворки.
Це значно звужує поле для оцінки конкретних систем.
Прототип з мінімальною складністю
Створіть найпростішу версію, яка перевіряє основні архітектурні припущення. Не додавайте функцій, інтеграцій чи полірування. Просто перевірте, чи відповідає архітектура фреймворку поставленій задачі.
Для агента служби підтримки створіть прототип найпростішої взаємодії: запитання користувача, пошук у базі знань, генерація відповіді. Пропустіть автентифікацію, ведення журналу, обробку помилок, граничні випадки.
Це показує, чи відповідає ментальна модель фреймворку проблемі, перш ніж інвестувати у виробничі функції.
Оцініть готовність виробництва
Після того, як архітектурна відповідність підтверджена, оцініть виробничі вимоги:
| Вимоги | Чому це важливо | Як оцінити |
|---|---|---|
| Державна персистенція | Агенти повинні витримувати перезавантаження | Відновлення тестової сесії після перезапуску процесу |
| Відновлення після помилок | Поломки інструменту трапляються постійно | Інжектуйте збої та таймаути API, перевірте коректну обробку |
| Спостережливість | Налагодження вимагає видимості | Вивчіть логи на предмет невдалих взаємодій, оцініть налагоджуваність |
| Контроль витрат | Використання токенів стає дорогим | Перевірте виконання бюджету та механізми кешування |
| Безпека | Агенти отримують доступ до чутливих систем | Перегляньте автентифікацію, авторизацію та пісочницю |
Структури, які не проходять таку оцінку, створюють технічний борг, який потім дуже дорого виправляти.
Розглянемо блокування екосистеми
Деякі фреймворки створюють більше обмежень, ніж інші. Оцініть:
- Чи використовує фреймворк стандартні протоколи (MCP) або кастомні інтеграції?
- Чи можна витягти логіку агента та перенести її на інші фреймворки?
- Чи прив'язана структура до конкретних провайдерів LLM або хмарних платформ?
- Чи є фреймворк з відкритим вихідним кодом та активним розвитком спільноти?
Замкненість не обов'язково погана, якщо структура забезпечує достатню цінність. Але рішення має бути обдуманим, а не випадковим.
Випробування в очікуваному масштабі
Характеристики продуктивності кардинально змінюються зі збільшенням масштабу. Фреймворк агентів, який добре працює при 10 запитах на хвилину, може вийти з ладу при 100.
Навантажувальний тест з реалістичними моделями трафіку перед розгортанням на виробництві. Вимірюйте:
- Процентилі затримки (p50, p95, p99)
- Обмеження пропускної здатності та вузькі місця
- Використання пам'яті та вимоги до ресурсів
- Витрати на взаємодію в масштабі
- Рівень помилок під навантаженням
Масштабне тестування виявляє проблеми, які не з'являються під час розробки.
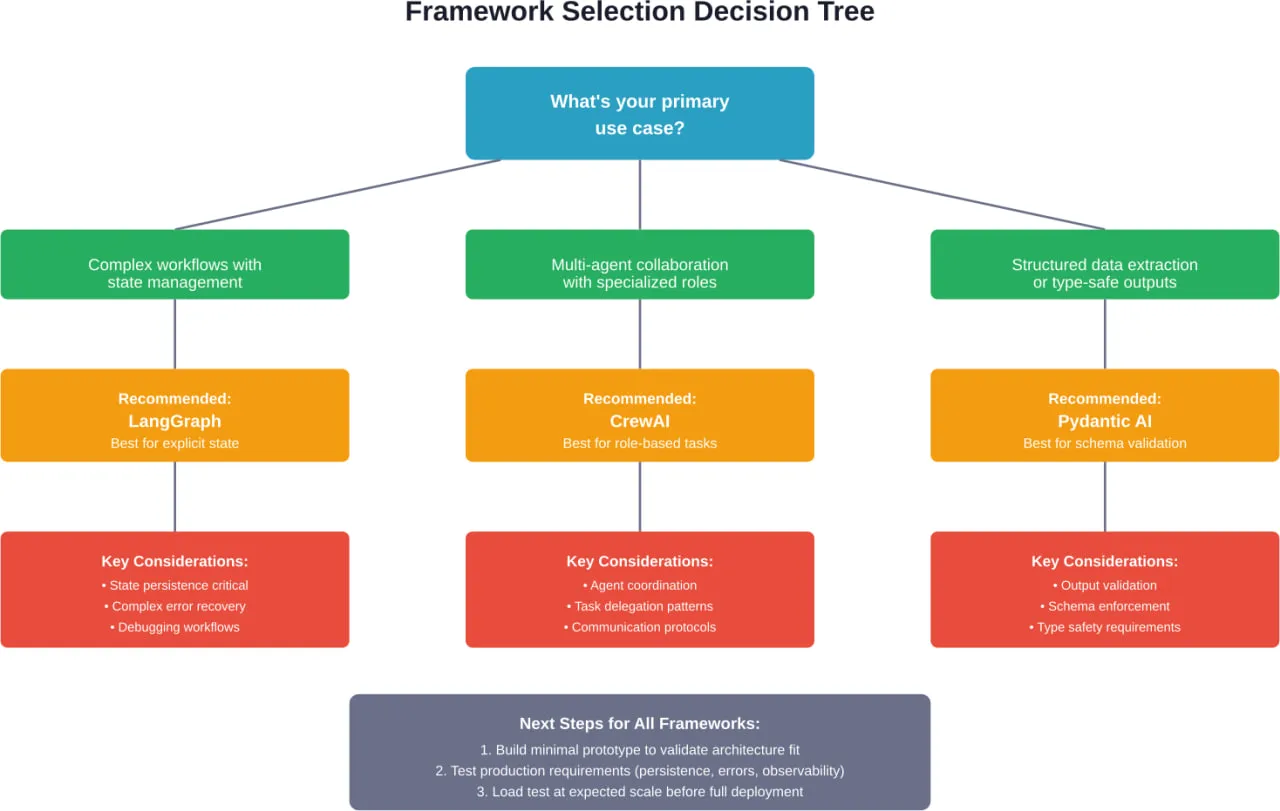
Типові помилки та як їх уникнути
Агенти з формування команд роблять передбачувані помилки. Розпізнавання цих патернів допомагає уникнути дорогих переробок.
Надмірне інжинірингове початкове впровадження
Спокуса створювати складні мультиагентні системи зі складною оркестровкою з першого дня вбиває проекти. Почніть з простого. Один агент, базові інструменти, мінімальне управління станом.
Додавайте складності лише тоді, коли простіші підходи не спрацьовують. Один добре розроблений агент часто перевершує три погано скоординовані спеціалізовані агенти.
Ігнорування токенової економіки до моменту виробництва
Середовища розробки з необмеженим бюджетом API приховують проблеми з витратами. Виробничі середовища з реальним трафіком виявляють їх болісно.
Впроваджуйте токен-бюджети та моніторинг з самого початку. Зробіть витрати видимими під час розробки, а не після розгортання.
Робота з агентами як з традиційним програмним забезпеченням
Традиційні патерни тестування, налагодження та розгортання не перекладаються безпосередньо. Команди, які намагаються вбудувати агентів в існуючі процеси, створюють тертя.
Інвестуйте в інструменти для оцінки, спостереження та розгортання для конкретних агентів. Початкові витрати окупляться скороченням часу налагодження та швидшими ітераціями.
Вибір фреймворків на основі хайпу
Зірки GitHub та згадки в інформаційних бюлетенях не передбачають успіху у виробництві. Фреймворки, які виживають у виробництві, мають інші характеристики, ніж фреймворки, які генерують хайп.
Оцінюйте на основі архітектурної відповідності та виробничої готовності, а не показників популярності.
Недооцінка складності налагодження
Коли агенти виходять з ладу, причиною збою часто є семантичне непорозуміння, а не помилки в коді. Традиційні підходи до налагодження не працюють.
Плануйте значні інвестиції в інструментарій спостережливості, ведення журналів та можливості відтворення сеансів. Налагодження агентів вимагає інших інструментів, ніж налагодження традиційного програмного забезпечення.
Перетворіть свій фреймворк AI-агентів на робочу систему
Вибір фреймворку - це найпростіша частина. Найбільше проблем виникає з інтеграцією - API, потоком даних, внутрішньою логікою та забезпеченням надійної роботи на виробництві.
A-listware надає командам розробників допомогу на цьому рівні. Компанія підтримує бекенд, інтеграцію та інфраструктуру навколо систем штучного інтелекту, допомагаючи командам перейти від обраних фреймворків до стабільного розгортання. Якщо ваш фреймворк обрано, але не впроваджено, зверніться до Програмне забезпечення списку А для підтримки інтеграції та розгортання.
Поширені запитання
- У чому різниця між фреймворком AI-агентів і звичайним LLM API?
API-інтерфейси LLM надають можливості генерації тексту - вхідний текст надходить на вхід, вихідний текст виходить на вихід. Фреймворки агентів ШІ додають до LLM оркестровку, управління станом, інтеграцію інструментів та багатокрокові міркування. Вони дозволяють агентам сприймати середовище, приймати рішення, використовувати інструменти та виконувати робочі процеси автономно, а не просто генерувати текстові відповіді.
- Який фреймворк AI-агентів найкращий для початківців?
Pydantic AI пропонує найнижчу криву навчання для розробників, які вже знайомі з Python та Pydantic. Він забезпечує безпеку типів і структуровані результати, не вимагаючи глибокого розуміння патернів оркестрування агентів. Для команд, які не знайомі з агентами та Python, діалогові фреймворки, такі як AutoGen, мають більш м'який вступний курс, ніж системи на основі графів, такі як LangGraph.
- Чи потрібен мені багатоагентний фреймворк або достатньо одного агента?
Почніть з архітектури з одним агентом, якщо тільки проблема явно не вимагає спеціалізованого досвіду в декількох областях. Багатоагентні системи збільшують витрати на координацію, складність налагодження та вартість. Вони мають сенс, коли завдання природно розкладаються на окремі ролі з різними вимогами до знань - наприклад, дослідження, аналіз і звітність - але більшість варіантів використання чудово працюють з одним добре спроектованим агентом.
- Як вирішити проблеми, пов'язані з блокуванням фреймворку?
Надавайте перевагу фреймворкам з підтримкою стандартних протоколів, таких як Model Context Protocol (MCP), для інтеграції інструментів. Відокремлюйте бізнес-логіку від коду оркестрування, специфічного для фреймворку. Використовуйте рівні абстракції для доступу до провайдерів LLM, щоб зміна провайдера не вимагала зміни фреймворку. Оцініть, чи виправдовують переваги фреймворку витрати на прив'язку до нього перед тим, як укладати угоду - іноді прив'язка є прийнятною, якщо фреймворк надає достатню цінність.
- Які типові витрати на запуск ШІ-агентів на виробництві?
Витрати суттєво різняться залежно від складності агента, використання токенів на одну взаємодію, обсягу трафіку та вибору моделі. Простий агент служби підтримки може використовувати 5,000-15,000 токенів за одну розмову. При ціноутворенні GPT-4 це становить $0,15-$0,45 за взаємодію. Складні дослідницькі агенти з широким використанням інструментів можуть витрачати понад 50 000 токенів на одне завдання. Виробничі витрати вимагають ретельного моніторингу, стратегій кешування та модельної маршрутизації для оптимізації співвідношення ціни та якості.
- Як стандарти NIST впливають на вибір фреймворку агента ШІ?
Відповідно до Ініціативи зі стандартизації агентів штучного інтелекту, оголошеної в лютому 2026 року, NIST розробляє стандарти безпеки, інтероперабельності та достовірності агентів. Поки ці стандарти перебувають на стадії розробки, фреймворки, які відповідають новим стандартам щодо протоколів автентифікації, ведення журналів аудиту та механізмів інтероперабельності, швидше за все, будуть легше впроваджуватися на підприємствах. Для регульованих галузей, відповідність фреймворків майбутнім стандартам NIST може стати жорсткою вимогою.
- Чи можу я змінити фреймворк після створення продакшн-агента?
Технічно так, але витрати на міграцію значні. Специфічні для фреймворку схеми оркестрування, підходи до управління станом та інтеграції інструментів не переносяться безпосередньо. Під час міграції слід очікувати переписування значної частини логіки агентів. Рішення про перехід має ґрунтуватися на чітких технічних обмеженнях, які виправдовують вартість міграції, а не на незначних відмінностях у функціях чи ажіотажі навколо нових фреймворків.
Прийняття Рамкового рішення
Жоден фреймворк не домінує над усіма варіантами використання. LangGraph чудово справляється зі складними робочими процесами з явним управлінням станами. CrewAI - для багатоагентної співпраці зі спеціалізацією ролей. Microsoft Agent Framework оптимізує інтеграцію на рівні підприємства. Pydantic AI забезпечує безпеку типів для структурованих результатів. Спеціалізовані фреймворки, такі як Firecrawl, оптимізують для конкретних доменів.
Правильний вибір залежить від архітектурного узгодження між проблемною областю та парадигмою фреймворку, виробничих вимог щодо збереження стану та відновлення після помилок, потреб в інтеграційній екосистемі та інструментальній підтримці, а також від навичок команди та кривої навчання.
Згідно з дослідженням arXiv, присвяченим фреймворкам агентного ШІ, таке архітектурне узгодження є найважливішим фактором успіху. Фреймворки, які відповідають природній декомпозиції проблем, призводять до більш чистих реалізацій, легшого налагодження та більш зручних для обслуговування систем.
Почніть з простого. Перевірте відповідність архітектури за допомогою мінімальних прототипів, перш ніж створювати виробничі функції. Тестуйте в очікуваному масштабі, перш ніж приступати до розгортання. Інвестуйте в інструменти спостереження та оцінки з самого початку.
Ландшафт фреймворків агентів продовжує розвиватися. Стандарти NIST та IEEE розвиваються завдяки зусиллям індустрії сигналізації. Прийняття протоколу Model Context Protocol зменшує прив'язку до фреймворку. З'являються спеціалізовані вертикальні фреймворки для конкретних доменів.
Але основи залишаються незмінними: розуміння архітектури проблеми, вибір фреймворків, які відповідають цій архітектурі, і перевірка виробничої готовності перед розгортанням. Команди, які дотримуються цього підходу, створюють агенти, які виживають у виробництві. Ті ж, хто женеться за хайповими циклами, закінчують переписуванням.
Готові створити свій перший продакшн-агент? Почніть з фреймворку, який відповідає природній архітектурі вашої проблеми. Створіть найпростішу версію, яка підтвердить концепцію. Потім ітерації на основі того, чого вас навчить продакшн.


