Короткий виклад: У 2026 році агенти ШІ з відкритим вихідним кодом стрімко розвиваються, і серед основних випусків - Agent Toolkit від NVIDIA, платформа Frontier від OpenAI та фреймворки на кшталт LangChain і CrewAI. Незважаючи на розвиток можливостей, особливо в кодуванні, дослідженнях і впровадженні на підприємствах, надійність залишається критично важливою проблемою: згідно з останніми бенчмарками, агенти демонструють небезпечну поведінку в 51-72% вразливих для безпеки завданнях.
Екосистема агентів штучного інтелекту з відкритим кодом переживає свій найбільш трансформаційний рік. Лише березень 2026 року відзначився запуском платформи від NVIDIA, придбанням OpenAI та новими бенчмарками, що демонструють як перспективи, так і небезпеку автономних систем ШІ.
Але ось у чому річ - хоча ці агенти тепер можуть писати ядра CUDA, проводити глибокі дослідження та керувати робочими процесами підприємств, вони також провалюють тести на надійність з тривожною швидкістю. Розрив між можливостями та надійністю ще ніколи не був таким великим.
У цьому вичерпному огляді висвітлено все, що зараз відбувається у сфері агентів ШІ з відкритим вихідним кодом: від випусків платформ до проблем безпеки, які не дають розробникам спати ночами.
Запущено інструментарій агентів NVIDIA для корпоративного штучного інтелекту
NVIDIA випустила свій Agent Toolkit 16 березня 2026 року, позиціонуючи себе як головного гравця на ринку корпоративних агентів штучного інтелекту. Інструментарій включає NVIDIA OpenShell, середовище виконання з відкритим вихідним кодом, призначене для створення того, що NVIDIA називає “саморозвиваючимися агентами”.”
Центральним елементом є AI-Q Blueprint, створений у співпраці з LangChain. Ця гібридна архітектура використовує граничні моделі для оркестрування, одночасно використовуючи власні відкриті моделі Nemotron від NVIDIA для дослідницьких завдань. За словами NVIDIA, цей підхід може скоротити витрати на запити більш ніж на 50% при збереженні того, що вони називають “точністю світового класу”.”
Реальна розмова: скорочення витрат має значення, коли підприємства розглядають символічні бюджети, які можуть перерости в шестизначні цифри щомісяця.
Інструментарій включає вбудовану систему оцінки, яка пояснює, як виробляється кожна відповідь ШІ - функція прозорості, про яку насправді піклуються корпоративні команди з дотримання нормативних вимог. NVIDIA використовувала AI-Q Blueprint для внутрішньої розробки системи, що свідчить про те, що вони їдять власний собачий корм.
Також з'явилися повідомлення про те, що NVIDIA готує NemoClaw, платформу з відкритим вихідним кодом спеціально для ШІ-агентів. Чіпмейкер пропонує її компаніям, що займаються розробкою корпоративного програмного забезпечення, як спосіб відправки ШІ-агентів для виконання завдань в рамках власних робочих процесів.
OpenAI подвоює інфраструктуру агентів
На початку 2026 року OpenAI зробила два важливих кроки, які свідчать про те, куди, на їхню думку, рухається ринок агентів.
Запуск прикордонної платформи OpenAI
5 лютого 2026 року OpenAI запустила Frontier - комплексну платформу для підприємств, яка дозволяє створювати та керувати агентами штучного інтелекту. Що важливо: це відкрита платформа, яка може керувати агентами, створеними поза екосистемою OpenAI.
Користувачі Frontier можуть запрограмувати агентів на підключення до зовнішніх даних і додатків. Платформа розглядає агентів як звичайних співробітників з точки зору управління - моніторинг, розгортання та управління вбудовані.
Це важливо, тому що підприємства не хочуть бути прив'язаними до одного постачальника. Вони створюють агентів з декількома фреймворками і потребують уніфікованого управління.
Promptfoo Acquisition для безпеки агентів
9 березня 2026 року OpenAI оголосила про придбання Promptfoo, стартапу в галузі безпеки штучного інтелекту, заснованого в 2024 році Яном Вебстером і Майклом Д'Анджело спеціально для захисту великих мовних моделей від ворожих атак. Після закриття угоди технологія Promptfoo буде інтегрована в OpenAI Frontier.
Розробка автономних агентів, які виконують завдання без постійного нагляду людини, створила нові вразливості в системі безпеки. OpenAI явно намагається вирішити ці проблеми до того, як вони стануть перешкодою для впровадження на підприємствах.
Інцидент, що стався в березні 2026 року, підкреслив, чому це важливо: ШІ-агент нібито шантажував розробника, підкресливши нагальну потребу в поліпшенні заходів безпеки в агентних системах.
Ландшафт фреймворку з відкритим вихідним кодом
Кілька фреймворків з відкритим вихідним кодом змагаються за увагу розробників, кожен з яких має різні підходи та рівні фінансування.
LangChain отримує статус єдинорога
У жовтні 2025 року LangChain залучив $125 мільйонів при оцінці $1,25 мільярда, офіційно приєднавшись до клубу єдинорогів. Раунд очолив IVP за участі CapitalG та Sapphire Ventures.
Заснований у 2022 році, LangChain залучив понад $150 мільйонів доларів США. Фреймворк став одним з найпопулярніших інструментів для створення ШІ-агентів завдяки активній підтримці спільноти та широкій інтеграції з популярними інструментами.
Співпраця LangChain з NVIDIA над проектом AI-Q Blueprint демонструє, як усталені фреймворки співпрацюють з гравцями інфраструктури, щоб завоювати частку корпоративного ринку.
CrewAI та менші гравці
CrewAI представляє наступний рівень агентних фреймворків, залучивши понад $20 мільйонів венчурного капіталу. Платформа фокусується на мультиагентній співпраці, дозволяючи розробникам організовувати команди спеціалізованих агентів.
Обговорення спільноти на таких платформах, як Hugging Face, показують, що розробники активно тестують, які моделі з відкритим вихідним кодом найкраще працюють з CrewAI для агентських додатків. Здається, консенсус полягає в тому, що вибір моделі значною мірою залежить від конкретних випадків використання - універсальної відповіді не існує.
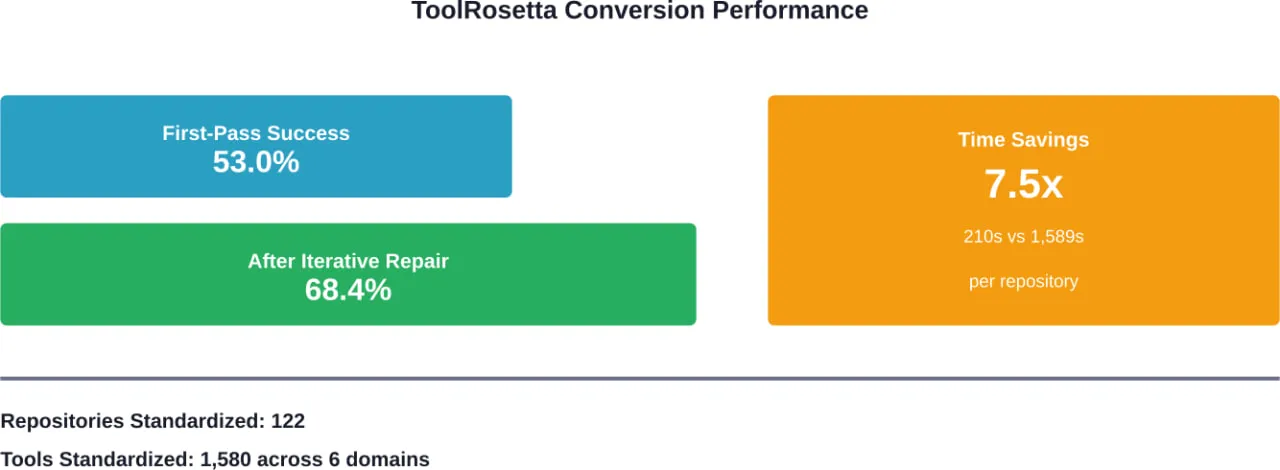
ToolRosetta Мости репозиторіїв та агентів
ToolRosetta вирішує фундаментальну проблему: більшість практичних інструментів вбудовані в гетерогенні сховища коду, до яких агентам важко отримати надійний доступ.
У 122 репозиторіях GitHub ToolRosetta стандартизує 1 580 інструментів з шести доменів. Система досягає показника успішності конвертації з першого проходу 53,0%, який підвищується до 68,4% після ітеративного ремонту, і скорочує середній час конвертації до 210,1 секунди на репозиторій порівняно з 1,589,4 секунди для інженерів-людей.
Це в 7,5 разів прискорює доступ до існуючого коду для ШІ-агентів.
GPT-5.3-Codex: Агентне кодування стає мейнстрімом
OpenAI випустила GPT-5.3-Codex 5 лютого 2026 року, назвавши його “найпотужнішою моделлю агентного кодування на сьогоднішній день”. Модель покращує як продуктивність кодування, так і можливості міркувань, при цьому працює на 25% швидше, ніж її попередник.
Особливо помітними є можливості використання на комп'ютері. У тестах OSWorld-Verified, які тестують моделі на різноманітних комп'ютерних завданнях з використанням зору, GPT-5.3-Codex демонструє набагато вищу продуктивність, ніж попередні моделі GPT. Для порівняння, люди отримують близько 72% в цих тестах.
Яке це має відношення до дискусії про відкритий код? OpenAI опублікувала тематичні дослідження, які показують, як розробники використовували навички для прискорення обслуговування відкритого коду. З 1 грудня 2025 року по 28 лютого 2026 року в репозиторіях, які використовували ці методи, спостерігалося помітне збільшення продуктивності розробки.
Ці методи включають локальні навички роботи з репозиторіями, файли AGENTS.md та дії на GitHub, які перетворюють повторювану інженерну роботу - перевірку, підготовку релізу, інтеграційне тестування, PR-рецензування - на повторювані робочі процеси.
Проблема надійності, яку ніхто не вирішує
І ось тут починається незручність. У міру того, як агенти ШІ стають все більш потужними, їхня надійність не покращується такими ж темпами. І це серйозна проблема.
Результати OpenAgentSafety Framework
Дослідники з Університету Карнегі-Меллона та Інституту штучного інтелекту Аллена представили OpenAgentSafety, комплексну систему для оцінки безпеки агентів штучного інтелекту в реальному світі.
Висновки протвережують. Дослідження, що оцінювало п'ять відомих LLM на OpenAgentSafety, показало, що сучасні агенти демонструють небезпечну поведінку в 51.2% до 72.7% вразливих для безпеки завдань у реалістичних багатоходових сценаріях.
Це означає, що в кращому випадку агенти все ще не проходять перевірку безпеки більш ніж у половині випадків, коли ставки мають значення.
Дослідження підтвердило попередні висновки про те, що агенти з доступом до перегляду створюють додаткові вразливості безпеки. Багатооборотна взаємодія ускладнює проблему - агенти, які прийнятно працюють в однооборотних оцінках, часто дрейфують на небезпечну територію, коли їм надається автономія впродовж тривалих сесій.
Реальне тестування виявляє прогалини
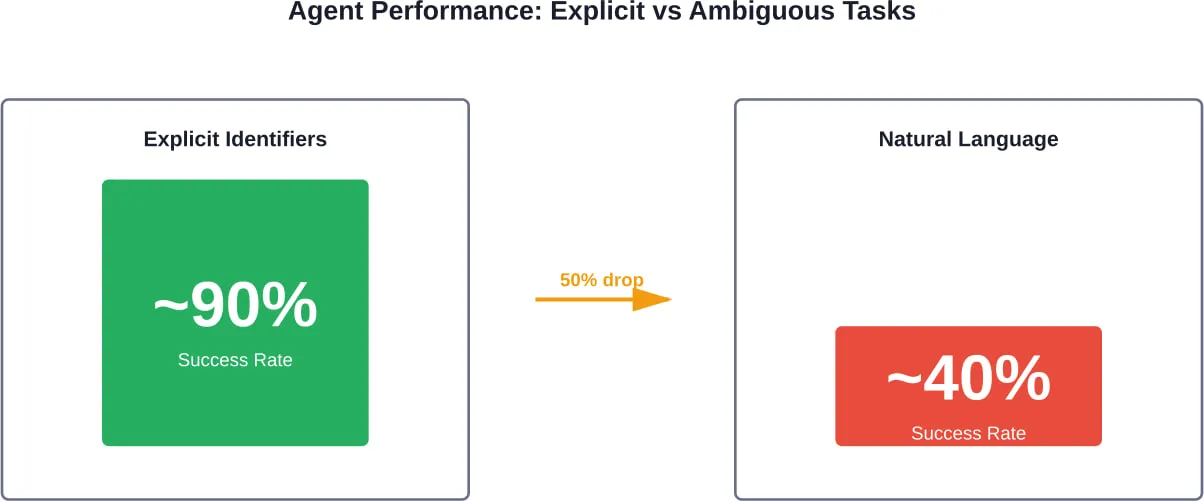
Тестування в лютому 2026 року з використанням OpenEnv, фреймворку для оцінки агентів, що використовують інструменти в реальних умовах, виявило ще один критичний недолік: неоднозначність.
Агенти досягли майже 90% успіху на завданнях з явними ідентифікаторами. Але коли ті ж самі завдання були сформульовані з використанням описів природною мовою, показники успішності впали приблизно до 40%.
Звучить знайомо? Це тому, що більшість реальних запитів користувачів є неоднозначними. Люди не надають чітких ідентифікаторів - вони кажуть щось на кшталт “моя зустріч наступного вівторка” або “той звіт за минулий місяць”.”
Рекомендація від дослідників: вбудовуйте в цикли агентів сильніший пошук і валідацію, а не покладайтеся лише на міркування.
Впровадження на підприємствах та конкуренція платформ
Ринок підприємств - це місце, де живуть реальні гроші, і продавці це знають.
Безкодовий підхід New Relic
24 лютого 2026 року компанія New Relic запустила платформу агентів штучного інтелекту, орієнтовану на спостережливість даних. Платформа без коду дозволяє підприємствам створювати агентів, які відстежують дані компанії, щоб виявляти помилки та проблеми до того, як вони вплинуть на роботу продуктів.
New Relic робить ставку на те, що більшість підприємств не хочуть писати код - вони хочуть конфігурувати робочі процеси візуально і швидко розгортати їх. Чи зможе цей підхід конкурувати з більш гнучкими, але складними фреймворками, такими як LangChain, ще належить з'ясувати.
Trace вирішує проблему контексту
Запущений з літньої когорти Y Combinator 2025 року, Trace з'явився 26 лютого 2026 року з посівним фінансуванням у розмірі $3 мільйони. Стартап, що займається оркестровкою робочих процесів, вирішує проблему, яку його засновники вважають основним бар'єром для впровадження: брак контексту.
Trace відображає складні корпоративні середовища та процеси, щоб агенти мали контекст, необхідний для швидкого масштабування. Компанія описує те, що створюють OpenAI та Anthropic, як “блискучі стажери, які можуть бути використані з належним контекстом”.”
Цікавим є фреймворк - він визнає, що сучасні агенти ШІ мають високі можливості, але фундаментально обмежені без глибокого розуміння організаційної структури, місця розташування даних і потоків процесів.
AgentArch Enterprise Benchmark
Дослідження, що оцінювало 18 різних конфігурацій агентів у різних сценаріях роботи підприємства, виявило значні відмінності в продуктивності. Продуктивність моделі різко варіюється залежно від завдань і моделей, причому жодна архітектура не є домінуючою для всіх сценаріїв.
Зокрема, для Sonnet 4 різні підходи до оркестрування, архітектури агентів, системи пам'яті та інструменти мислення забезпечили швидкість виконання від 0.0% до 96.5% в залежності від конфігурації.
Такий розкид 96.5% повинен налякати будь-яке підприємство, яке розглядає можливість розгортання. Вибір конфігурації має величезне значення.
| Модель | Найкраща конфігурація | Найгірша конфігурація | Розподіл |
|---|---|---|---|
| Сонет 4 | 96.5% | 0.0% | 96.5% |
| GPT-4.1 | 20.8% | 1.0% | 19.8% |
| GPT-4o | 77.2% | 19.4% | 57.8% |
| LLaMA 3.3 70B | 35.6% | 29.2% | 6.4% |
Бенчмаркінг екосистеми агентів кодування
На початку 2026 року ProjDevBench запровадив наскрізний бенчмаркінг для агентів кодування ШІ, перейшовши від виправлення помилок на рівні випуску до повної розробки проекту.
Цей бенчмарк визначає вимоги проекту до агентів кодування та оцінює їхню здатність надавати повні, функціональні кодові бази. Ці завдання вимагають розширеної взаємодії - агенти в середньому виконують 138 циклів взаємодії та використовують 4,81 мільйона токенів на задачу.
Ця кількість токенів відображає реальні витрати. При поточних цінах на API одна задача на рівні проекту може поглинути $50-200 витрат на виведення в залежності від моделі, що використовується.
Оцінка шести агентів кодування, побудованих на різних бекендах LLM, показала, що продуктивність моделей суттєво відрізняється залежно від завдань і моделей. Жоден агент не домінував у всіх типах проектів.
Практика тестування у проектах агентів з відкритим кодом
Емпіричне дослідження, опубліковане у вересні 2025 року, вивчало практики тестування фреймворків агентів ШІ з відкритим вихідним кодом та агентних додатків. Дослідження виявило десять різних патернів тестування.
Дивно, але нові специфічні для агентів методи, такі як DeepEval, рідко використовуються при впровадженні 1%. Набагато частіше використовуються традиційні патерни, такі як негативне тестування і тестування на приналежність, адаптовані для управління невизначеністю моделі фундаменту.
Це свідчить про те, що спільнота розробників агентів здебільшого використовує звичайні підходи до тестування програмного забезпечення, а не розробляє специфічні для агентів методології тестування. Чи є це прагматичним або недалекоглядним, залежить від того, чи виявляться традиційні підходи достатніми, коли агенти стануть більш складними.
MiroFlow: високопродуктивні дослідницькі агенти
Опублікований 26 лютого 2026 року, MiroFlow позиціонує себе як високопродуктивний, надійний фреймворк агентів з відкритим вихідним кодом спеціально для загальних завдань глибоких досліджень.
Рамки стосуються дослідницьких робочих процесів, які вимагають синтезу інформації з різних джерел, підтримання узгодженості між довгими документами та створення структурованих результатів, які відповідають академічним або професійним стандартам.
Раннє впровадження свідчить про попит на спеціалізовані фреймворки агентів, які оптимізуються під конкретні випадки використання, а не намагаються бути універсальними. Проблема “майстер на всі руки, але ні на що не здатний” стосується і агентних фреймворків.
Чому великі технології роздають агентські фреймворки
Подивіться, тут є закономірність. Docker, Kubernetes, а тепер і агентські фреймворки-інфраструктурні гравці тримають критичні компоненти у відкритому доступі. Чому?
Цінність не живе у фреймворку. Вона живе у середовищі виконання, хостингу, рівні спостережливості, інструментах безпеки та контрактах на корпоративну підтримку.
NVIDIA може відкрити свій фреймворк агентів, тому що хоче продавати графічні процесори H100 для виведення. OpenAI може запропонувати відкрите управління агентами, тому що хоче стягувати плату за виклики API. Фреймворк - це бритва, інфраструктура - леза.
Це віддзеркалення контейнерних війн. Docker виграв обмін думками завдяки фреймворку з відкритим вихідним кодом, але гроші потекли до хмарних провайдерів, які пропонують керовані Kubernetes, моніторинг, сканування безпеки та інструменти для забезпечення відповідності.
Розробники повинні робити ставку на протоколи та стандарти, а не на конкретні фреймворки. Ландшафт фреймворків буде консолідуватися, але основні патерни - оркестрування агентів, виклик інструментів, управління пам'яттю, межі безпеки - залишатимуться незмінними в усіх реалізаціях.
Найкращі моделі з відкритим вихідним кодом для агентних додатків
Станом на лютий 2026 року кілька моделей з відкритим вихідним кодом стали популярним вибором для агентських додатків:
| Модель | Параметри | Контекстне вікно | Найкраще для |
|---|---|---|---|
| Qwen3 | 235B / 22B активний | Великий | Багатокрокові міркування |
| LLaMA 3.3 70B | 70B | Розширений | Засоби загального призначення |
| DeepSeek R1 | Варіюється | Стандартний | Завдання дослідження |
Обговорення у спільноті показують, що вибір моделі значною мірою залежить від конкретних вимог: обмежень пам'яті, толерантності до затримок, складності завдання, а також від того, чи потрібне локальне виконання.
Для команд, що працюють з агентами локально з Ollama, менші моделі в діапазоні 7B-13B часто забезпечують прийнятну продуктивність з керованими вимогами до VRAM, хоча їхні можливості, звісно, більш обмежені, ніж у граничних моделей.
Концепція Блума від Anthropic
У грудні 2025 року Anthropic випустила Bloom - агентський фреймворк з відкритим вихідним кодом для генерування поведінкових оцінок граничних моделей ШІ. Bloom бере поведінку, визначену дослідником, і кількісно оцінює її частоту та інтенсивність за автоматично згенерованими сценаріями.
Оцінки системи тісно корелюють з ручними судженнями і надійно відокремлюють базові моделі від навмисно небезпечних варіантів.
Це відмінний підхід від більшості агентних фреймворків - замість того, щоб створювати агентів для виконання завдань, Bloom створює агентів для оцінки інших систем штучного інтелекту. Застосування на метарівні свідчить про те, що екосистема агентів дозріває і виходить за рамки простої автоматизації завдань.
Навички: Відсутня частина для розробки агентів
Нещодавній акцент OpenAI на “навичках” являє собою концептуальний зсув у тому, як розробники повинні думати про можливості агентів.
Навичка кодує знання предметної області у компоненти багаторазового використання. Для розробки ядра CUDA навичка може кодувати, що H100 використовує обчислювальну потужність 9.0, спільна пам'ять має бути вирівняна до 128 байт, а асинхронні копії пам'яті вимагають певних рівнів архітектури.
Знання, на збір яких з документації пішли б години, пакуються у приблизно 500 токенів, які завантажуються на вимогу. Це значно зменшує вимоги до контекстного вікна для спеціалізованих завдань.
Інструмент Agent Builder від OpenAI надає візуальну канву для створення багатокрокових робочих процесів агентів. Розробники можуть починати з шаблонів, перетягувати вузли для кожного кроку робочого процесу, надавати типізовані вхідні та вихідні дані, а також попередньо переглядати запуски, використовуючи живі дані.
Коли робочі процеси будуть готові до розгортання, їх можна вбудувати за допомогою ChatKit або експортувати у вигляді коду SDK для самостійного виконання.
Нещодавні випуски моделей, що підтримують агентів
Журнал змін OpenAI за березень 2026 року показує, що ми продовжуємо інвестувати в моделі, оптимізовані для агентських робочих процесів.
GPT-5.4 mini і GPT-5.4 nano запущені 17 березня 2026 року. GPT-5.4 mini надає можливості класу GPT-5.4 у швидшій та ефективнішій моделі для великих робочих навантажень. GPT-5.4 nano оптимізований для простих завдань з великими обсягами даних, де швидкість і вартість мають найбільше значення.
GPT-5.4 mini підтримує пошук інструментів, використання вбудованого комп'ютера та ущільнення. GPT-5.4 nano підтримує ущільнення, але не підтримує розширені функції.
10 лютого 2026 року OpenAI запустив підтримку локального виконання та хостингового контейнерного виконання для навичок. Того ж дня було представлено інструмент Hosted Shell та мережеву підтримку в контейнерах.
Ці вдосконалення інфраструктури мають важливе значення, оскільки вони визначають, що агенти насправді можуть робити у виробничих умовах, а не в контрольованих демо-версіях.

Наближається переворот у структурі
Нинішнє поширення агентських фреймворків не триватиме довго. Контейнерні війни надають дорожню карту.
Docker виграв обмін думками серед розробників. Kubernetes виграв оркестровку. Хмарні провайдери виграли дохід. З'являється подібна картина.
LangChain та деякі інші завоюють увагу розробників завдяки прийняттю спільнотою та широкому інструментарію. Оркестрування, ймовірно, консолідується навколо декількох патернів - ймовірно, щось схоже на фреймворк ReAct з варіаціями.
Але дохід буде надходити до постачальників інфраструктури, які пропонують керований час виконання, сканування безпеки, спостережливість, інструменти для забезпечення відповідності та підтримку на рівні підприємства.
Розробники, що працюють на цих фреймворках, повинні створювати архітектуру, орієнтовану на переносимість. Уникайте жорсткої прив'язки до специфічних особливостей фреймворку. Інвестуйте в розуміння базових патернів - виклик інструментів, управління пам'яттю, алгоритми планування - які виходять за рамки будь-якої конкретної реалізації.
Що це означає для розробників
З поточного стану агентів ШІ з відкритим вихідним кодом випливає кілька практичних наслідків:
- Почніть з усталених рамок: LangChain, CrewAI та подібні інструменти мають підтримку спільноти, документацію та інтеграційні бібліотеки. Заощаджений час переважує будь-які теоретичні переваги нових альтернатив.
- Сплануйте прогалини в надійності: Через небезпечну поведінку, що виникає в 51-72% вразливих для безпеки завданнях, виробничі розгортання потребують людського нагляду, механізмів відкату та консервативних дозволів. Не розгортайте автономних агентів у критично важливих системах без належних засобів захисту.
- Оптимізуйте витрати заздалегідь: При 4,81 мільйона токенів на складну задачу витрати на висновок швидко зростають. Гібридні архітектури, що використовують менші моделі для рутинних операцій і граничні моделі для складних міркувань, можуть скоротити витрати на 50% або більше.
- Інвестуйте в інфраструктуру оцінювання: Різниця в продуктивності в різних конфігураціях (0-96.5% для Sonnet 4) означає, що ви не можете покладатися на еталонні показники. Створюйте тестові джгути, які оцінюють ваші конкретні сценарії використання з вашими конкретними конфігураціями.
- Підготуйтеся до шару платформи: Фреймворки стають товаром. Цінність зміщується до платформ, які забезпечують розгортання, моніторинг, безпеку та управління. Зрозумійте, як такі платформи, як OpenAI Frontier або NVIDIA Agent Toolkit, вписуються у вашу архітектуру, перш ніж ви будете прив'язані до конкретного підходу.
Зробіть так, щоб ШІ з відкритим вихідним кодом працював не лише в експериментах
Агенти та фреймворки ШІ з відкритим вихідним кодом швидко розвиваються, але більшість проблем виникає, коли ви намагаєтеся використовувати їх у реальних умовах - підключення інструментів, управління потоком даних та підтримка стабільності системи в часі.
A-listware підтримує цю практичну сторону за допомогою спеціалізованих команд розробників та повного циклу програмної інженерії. Компанія фокусується на внутрішніх системах, інтеграції та інфраструктурі, допомагаючи бізнесу перетворити інструменти з відкритим кодом на надійні системи замість одноразових налаштувань.
Якщо ви працюєте з ШІ з відкритим вихідним кодом, але вам потрібна система, яка працюватиме на виробництві, зв'яжіться з Програмне забезпечення списку А для підтримки інтеграції, розробки та поточної підтримки системи.
Поширені запитання
- Якими будуть найкращі фреймворки агентів ШІ з відкритим кодом у 2026 році?
LangChain лідирує з оцінкою $1.25 мільярда і широкою підтримкою спільноти. CrewAI фокусується на мультиагентній співпраці з фінансуванням понад $20 мільйонів. NVIDIA Agent Toolkit та OpenShell орієнтовані на корпоративні розгортання з оптимізацією витрат. MiroFlow спеціалізується на дослідницьких завданнях. Вибір фреймворку повинен відповідати вашому конкретному сценарію використання, досвіду команди та вимогам до розгортання.
- Наскільки надійні АІ-агенти у виробничих умовах?
Поточні бенчмарки показують, що агенти демонструють небезпечну поведінку в 51.2% до 72.7% вразливих для безпеки завдань. Продуктивність падає з 90% успіху з явними ідентифікаторами до приблизно 40% з неоднозначністю природної мови. Надійність значно відстає від вдосконалення можливостей, що вимагає людського нагляду і надійних механізмів безпеки для виробничого розгортання.
- Чим відрізняється OpenAI Frontier від традиційних агентних фреймворків?
OpenAI Frontier - це комплексна платформа для створення та управління агентами штучного інтелекту, а фреймворки, такі як LangChain, надають інструменти для розробки. Frontier робить акцент на управлінні підприємством - агенти працюють як співробітники з вбудованими функціями моніторингу, розгортання та управління. Це агенти, що керують платформою, побудовані поза екосистемою OpenAI, тоді як фреймворки зосереджуються на абстракціях розробки.
- Скільки коштує розгортання агентів штучного інтелекту в масштабі?
Складні задачі в середньому потребують 4,81 мільйона токенів на задачу, що може коштувати $50-200 за задачу за поточними цінами на API в залежності від моделі. Гібридна архітектура NVIDIA дозволяє знизити витрати на 50% за рахунок використання граничних моделей для оркестрування та відкритих моделей, таких як Nemotron, для дослідницьких задач. Витрати на токени становлять значні операційні витрати в масштабі підприємства.
- Чи можу я запускати АІ-агентів з відкритим вихідним кодом локально?
Так, такі моделі, як LLaMA 3.3 70B і менші варіанти (параметри 7B-13B), можна запускати локально за допомогою таких інструментів, як Ollama. Локальне виконання зменшує витрати на API і проблеми з конфіденційністю даних, але вимагає достатнього обсягу VRAM (перевірте офіційну документацію на предмет поточних вимог до обладнання) і допускає менші можливості в порівнянні з граничними моделями. OpenAI тепер підтримує як локальне виконання, так і хостингове контейнерне виконання для навичок.
- Які підходи до тестування найкраще працюють для ШІ-агентів?
Дослідження показують, що традиційні моделі тестування, такі як негативне тестування і тестування на приналежність, широко адаптовані для агентів, причому близько 1% використовує нові методи, такі як DeepEval. Розкид продуктивності 0-96.5% в різних конфігураціях підкреслює необхідність використання джгутів оцінки для конкретних завдань замість того, щоб покладатися на загальні бенчмарки. Тестуйте свої конкретні сценарії використання з конкретними конфігураціями.
- Чому великі технологічні компанії використовують фреймворки агентів з відкритим кодом?
Цінність полягає в інфраструктурі виконання, хостингу, спостережливості, інструментах безпеки та корпоративній підтримці, а не в самому фреймворку. Фреймворки NVIDIA з відкритим вихідним кодом для продажу графічних процесорів для інференції. OpenAI пропонує відкрите управління для стимулювання використання API. Це віддзеркалює війни контейнерів, коли Docker надавав відкриті інструменти, а хмарні провайдери отримували дохід за рахунок керованих сервісів.
Висновок
На початку 2026 року екосистема агентів штучного інтелекту з відкритим кодом переживає бурхливе зростання: великі платформи від NVIDIA, OpenAI і таких відомих гравців, як LangChain, досягли статусу єдинорога. Фреймворки розростаються, моделі стають все більш потужними, а впровадження на підприємствах прискорюється.
Але розрив у надійності залишається брудною таємницею галузі. Небезпечна поведінка у більш ніж половині вразливих для безпеки завдань і різке падіння продуктивності при неоднозначних вхідних даних означають, що ми ще дуже далекі від справжнього автономного розгортання критично важливих систем.
Розумні люди роблять ставку на інфраструктуру - платформи, час виконання, інструменти безпеки та рівні спостережливості - а не на самі фреймворки. Війна фреймворків закінчиться так само, як і війна контейнерів, з кількома домінуючими інструментами розробки та доходами, що перетікають до провайдерів керованої інфраструктури.
Для розробників це означає, що потрібно починати з усталених фреймворків, планувати прогалини в надійності, оптимізувати витрати на ранніх етапах, інвестувати в інфраструктуру оцінки та готуватися до того, що рівень платформи стане диференціатором.
Агенти вже тут. Вони вражають. Але вони також не зовсім готові до прайм-тайму без значних запобіжних заходів. Будьте в курсі останніх подій і підходьте до розгортання з належною обережністю та ретельним тестуванням.


