Résumé rapide : Les cadres d'agents d'IA fournissent l'infrastructure de base pour construire des systèmes d'IA autonomes capables de percevoir, de raisonner et d'agir. Les principaux cadres tels que LangGraph, CrewAI et Microsoft Agent Framework offrent différentes architectures - de l'orchestration basée sur des graphes avec état aux systèmes de collaboration multi-agents - chacune adaptée à des cas d'utilisation spécifiques allant de la simple automatisation de tâches aux flux de travail d'entreprise complexes.
Le passage des grands modèles de langage traditionnels à des agents d'IA autonomes représente l'une des transformations les plus importantes dans le domaine de l'intelligence artificielle. Mais voilà, pour créer des agents qui fonctionnent réellement en production, il ne suffit pas d'enchaîner quelques appels d'API.
Les cadres d'agents sont apparus pour résoudre ce problème précis. Ils fournissent les modèles architecturaux, les outils d'orchestration et les capacités d'intégration nécessaires pour transformer les prototypes expérimentaux en systèmes fiables. Selon une recherche publiée sur arXiv, ces cadres fonctionnent comme un “système d'exploitation” pour les agents, réduisant les taux d'hallucination en transformant les discussions non structurées en flux de travail rigoureux.
Le paysage a évolué de manière spectaculaire. Ce qui a commencé par des projets expérimentaux tels qu'AutoGPT a mûri pour devenir des plates-formes d'entreprise prenant en charge tout ce qui va de l'automatisation du service client à des systèmes complexes de chaîne d'approvisionnement multi-agents. Et les différences entre les frameworks sont plus importantes que la plupart des développeurs ne le pensent au départ.
Ce guide ne se contente pas de faire de l'esbroufe. Il ne s'agit pas d'un discours creux, ni de repères inventés, mais d'une analyse pratique basée sur ce qui est réellement mis en production.
Ce qui différencie les cadres d'agents d'IA
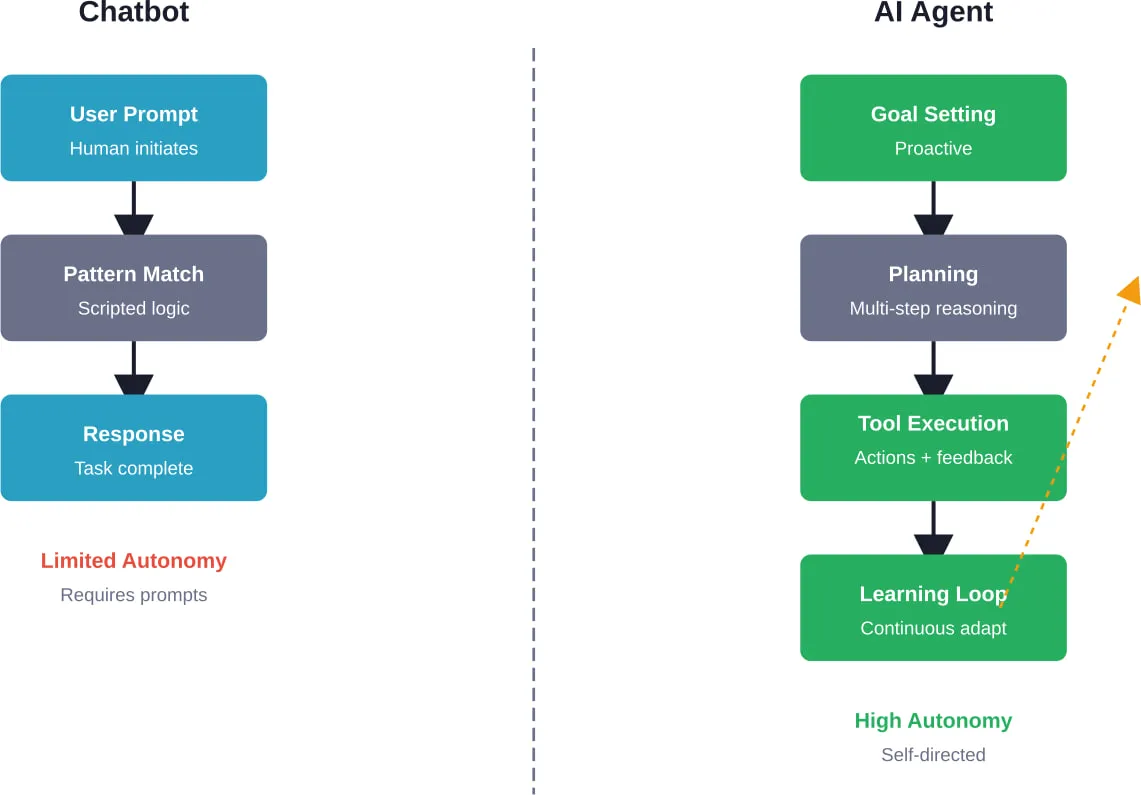
Les applications traditionnelles de gestion du cycle de vie suivent un modèle simple : l'entrée se fait, la réponse sort. Les agents rompent totalement avec ce modèle.
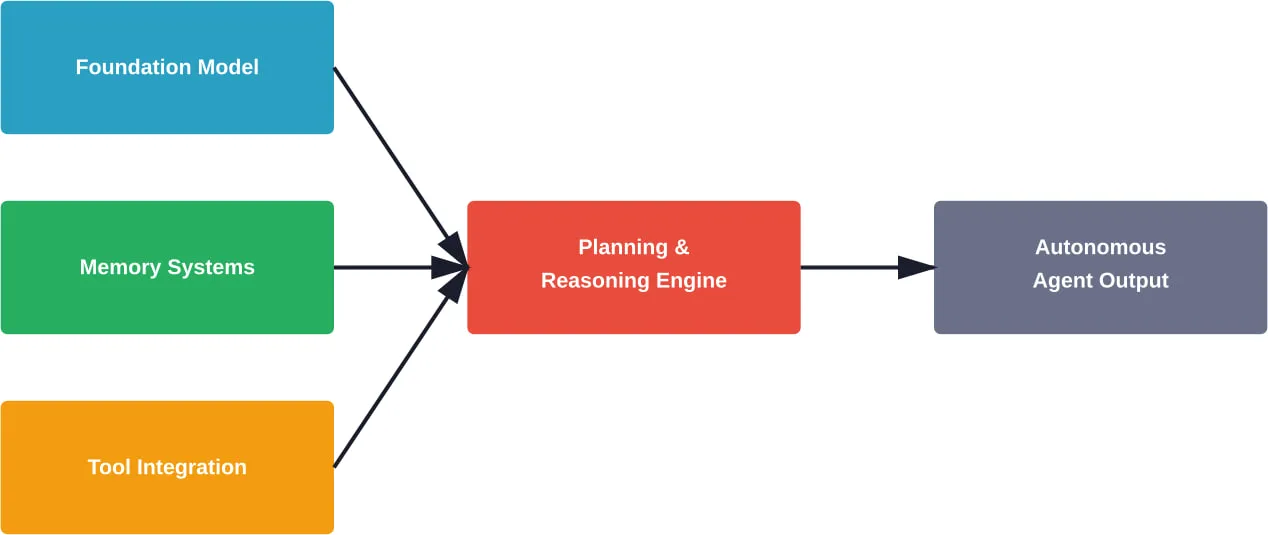
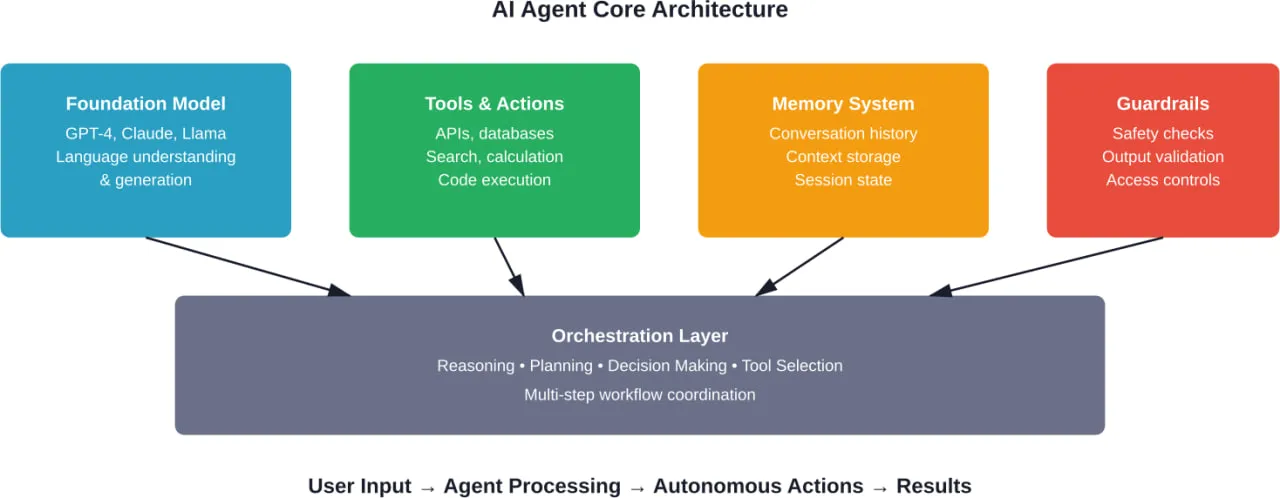
Un cadre d'agent d'IA fournit l'infrastructure pour les systèmes qui peuvent percevoir leur environnement, prendre des décisions autonomes, utiliser des outils, maintenir l'état à travers les interactions, et exécuter des flux de travail à plusieurs étapes. Selon la recherche arXiv qui distingue les agents d'IA de l'IA agentique, ces cadres sont des “systèmes modulaires pilotés par des LLM” dont la philosophie de conception est fondamentalement différente de celle des simples chatbots.
Les éléments de base comprennent généralement
- des moteurs d'orchestration qui gèrent les cycles de vie des agents et l'exécution des tâches
- Systèmes de mémoire pour la persistance de l'état à court et à long terme
- Couches d'intégration d'outils permettant aux agents d'interagir avec des systèmes externes
- Boucles de raisonnement permettant la planification et l'autocorrection
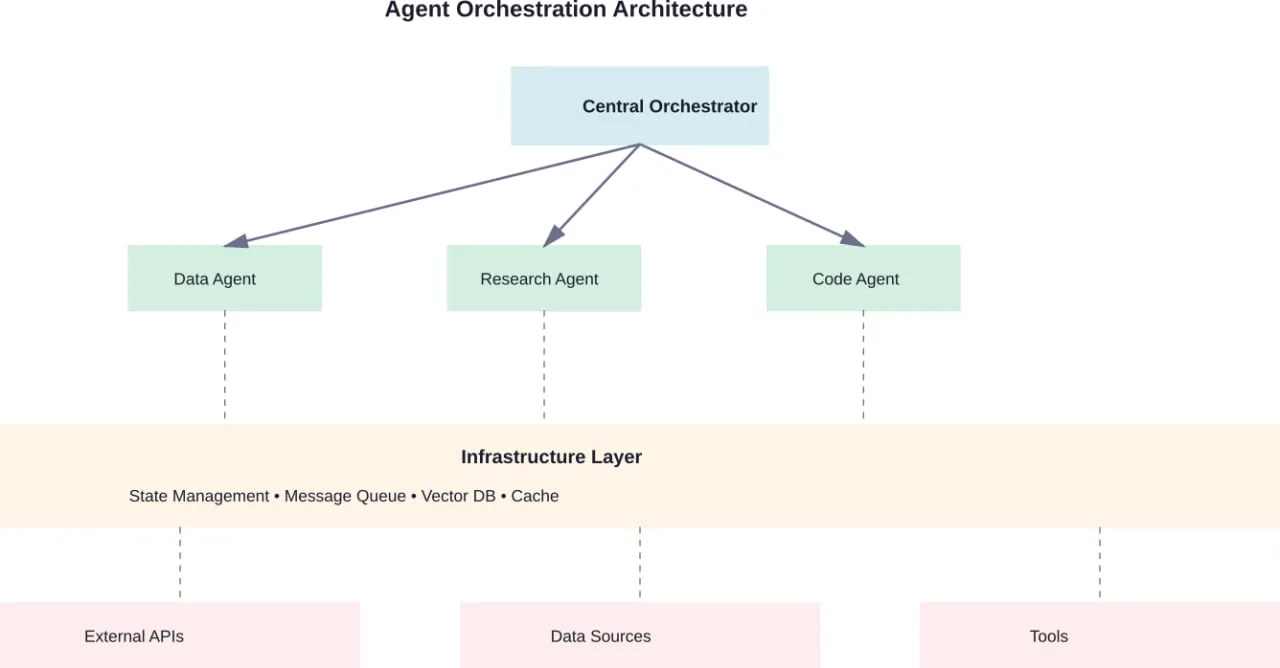
- Protocoles de coordination multi-agents pour les flux de travail collaboratifs
Mais tous les cadres ne mettent pas en œuvre ces composants de la même manière. Certains donnent la priorité à la gestion des états basée sur les graphes, d'autres se concentrent sur les flux conversationnels et d'autres encore se spécialisent dans l'orchestration multi-agents.
La question d'architecture qui définit tout
Selon la taxonomie d'arXiv des options d'architecture pour les agents basés sur des modèles de fondation, le choix fondamental de l'architecture détermine tout ce qui se passe en aval. Les cadres se répartissent généralement en trois catégories :
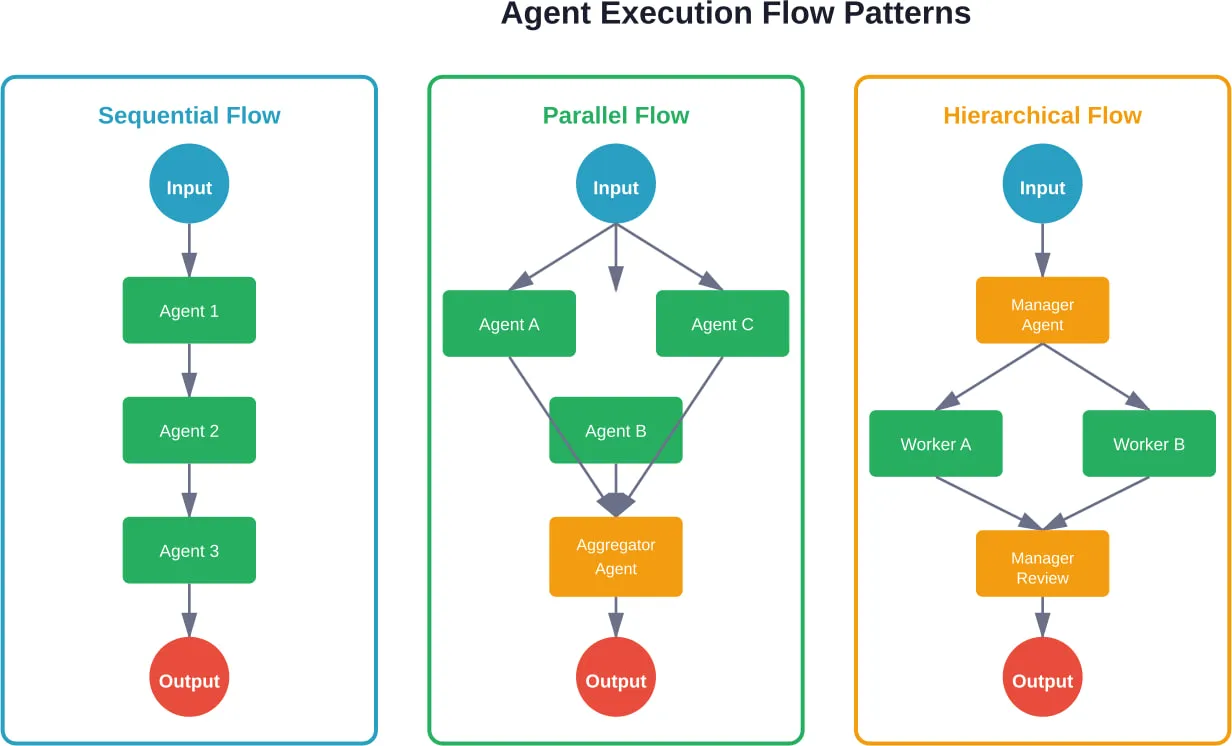
- Les systèmes basés sur des graphes avec état traitent l'exécution de l'agent comme un graphe dirigé où les nœuds représentent des états ou des actions. Cette approche excelle dans les flux de travail complexes avec des branchements conditionnels, une exécution parallèle et une gestion explicite des états.
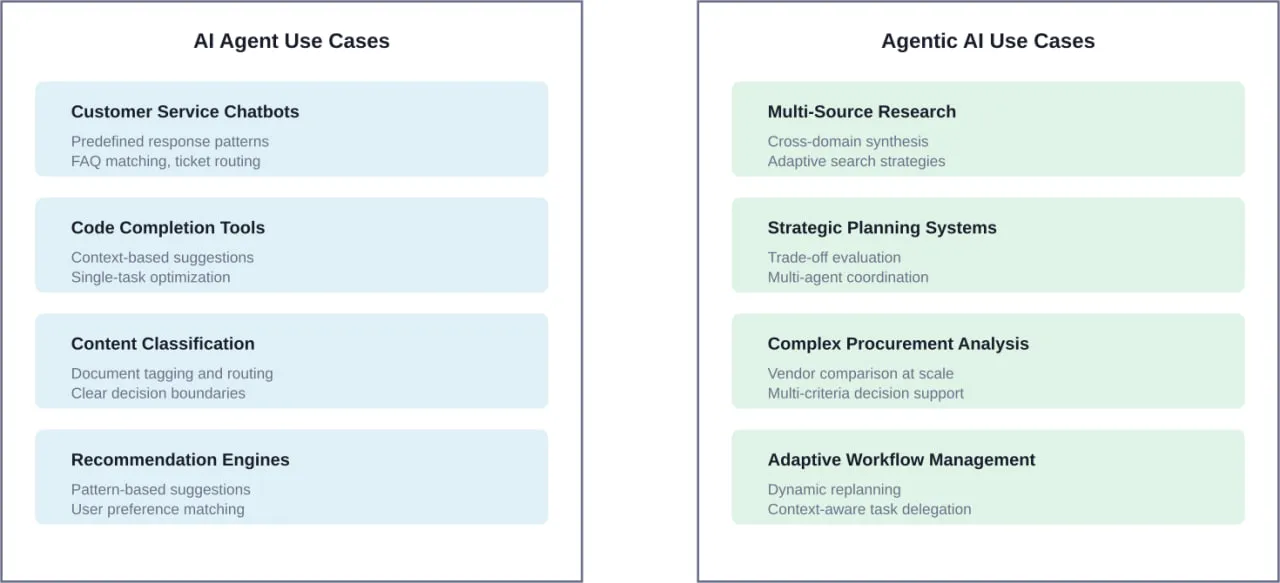
- Les cadres conversationnels modélisent les agents comme des chatbots améliorés ayant accès à des outils. Ils fonctionnent bien pour les applications en contact avec la clientèle où le dialogue naturel est plus important qu'une orchestration complexe.
- Les systèmes multi-agents répartissent les tâches entre des agents spécialisés qui communiquent et collaborent. La recherche montre que ce modèle fonctionne particulièrement bien pour simuler des structures organisationnelles, comme ChatDev, qui simule une entreprise de logiciels où les agents s'organisent eux-mêmes en fonction des rôles de conception, de codage et de test.
Le choix de l'architecture n'est pas qu'une simple préférence technique. Il conditionne fondamentalement les types d'applications qui deviennent naturelles et non pénibles à construire.
Les cadres de production méritent d'être pris en compte
Il existe de nombreux cadres d'agents. La plupart ne survivent pas au contact avec les exigences de production. Voici ceux qui y parviennent, sur la base d'expériences de déploiement réelles documentées dans l'écosystème.
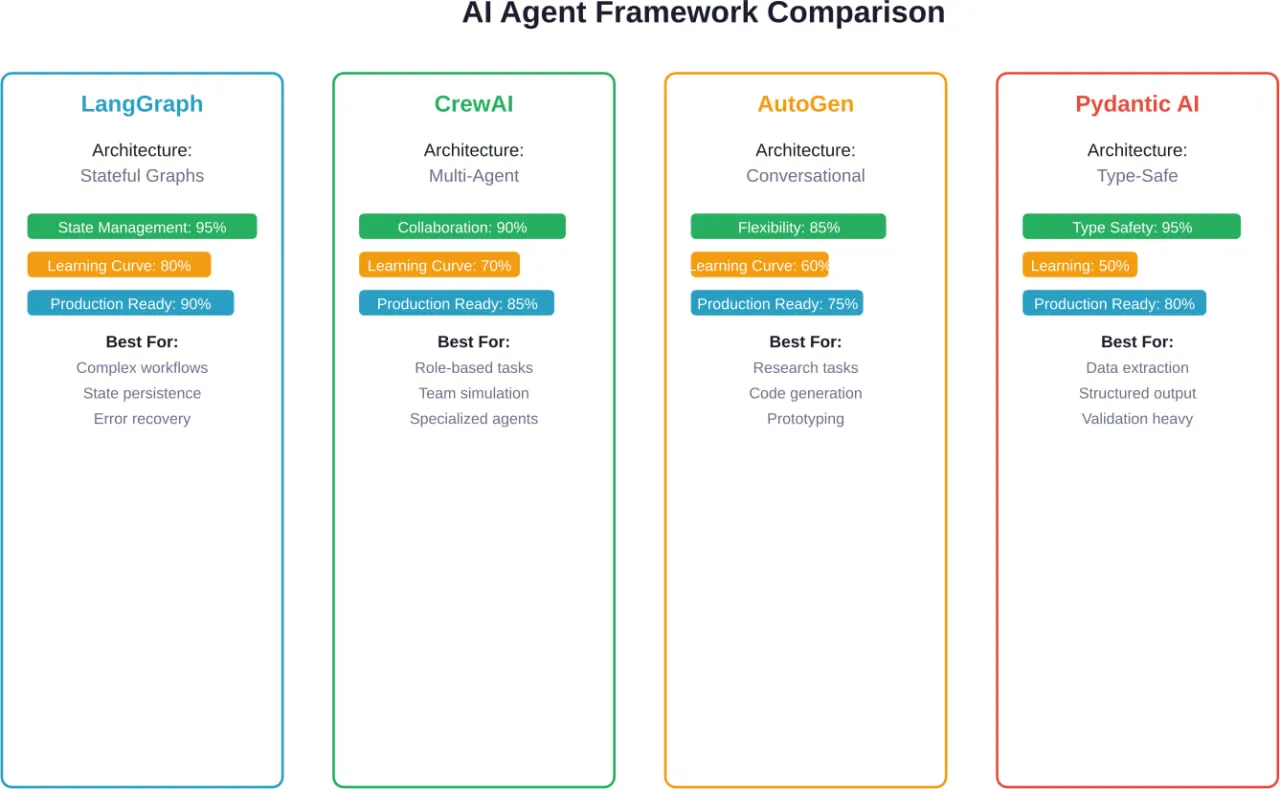
LangGraph : Quand la gestion des états est importante
LangGraph aborde l'orchestration d'agents par le biais de graphes avec état. Chaque nœud représente une fonction, les arêtes définissent les transitions et l'état circule dans le graphe avec une persistance explicite.
Le framework a 24,8k étoiles GitHub et voit 34,5 millions de téléchargements mensuels - des chiffres qui reflètent une véritable adoption en production, et pas seulement un intérêt expérimental. D'après l'analyse des praticiens qui ont utilisé plusieurs frameworks, LangGraph se situe dans le peloton de tête des systèmes qui survivent à la production.
Les principales capacités sont les suivantes
- Gestion explicite de l'état avec des backends de persistance configurables
- Flux de travail en boucle avec des portes d'approbation
- Prise en charge des architectures à agent unique et à agents multiples
- Débogage par voyage dans le temps au moyen d'instantanés d'état
- Prise en charge du streaming natif pour des mises à jour en temps réel
Le compromis ? LangGraph exige une réflexion architecturale plus poussée. Les développeurs doivent modéliser explicitement les transitions d'état plutôt que de s'appuyer sur un flux conversationnel implicite. Pour les flux de travail d'entreprise complexes avec une logique de branchement et des exigences de récupération d'erreurs, cette explicitation devient un avantage.
Parlons franchement : LangGraph fonctionne mieux lorsque le domaine du problème présente des états et des transitions clairs. Les flux d'escalade du support client, les processus d'approbation en plusieurs étapes et les pipelines de recherche avec branchement conditionnel s'adaptent naturellement à son paradigme de graphe.
CrewAI : la collaboration multi-agents en pratique
CrewAI se spécialise dans la coordination de plusieurs agents travaillant à des objectifs communs. Le cadre modélise les agents comme des membres d'une équipe avec des rôles, des responsabilités et des modes de communication définis.
L'abstraction principale est centrée sur les “équipages” - des groupes d'agents qui collaborent à des tâches. Chaque agent a un rôle, un objectif, des outils qu'il peut utiliser et une histoire qui influence son comportement. Les tâches sont assignées aux agents en fonction de leurs capacités, et le cadre gère la communication entre les agents.
Cette approche est idéale pour les problèmes qui se décomposent naturellement en rôles spécialisés. Les flux de travail de création de contenu peuvent comporter un agent chercheur, un agent rédacteur et un agent éditeur. L'analyse financière peut impliquer des agents de collecte de données, des agents d'analyse et des agents de reporting.
CrewAI prend en charge de multiples modèles de collaboration :
- Exécution séquentielle où les agents travaillent les uns après les autres
- Structures hiérarchiques avec des agents gestionnaires qui délèguent à des spécialistes
- Mécanismes de consensus où plusieurs agents votent sur les décisions
Le cadre apparaît fréquemment dans les classements des meilleurs cadres d'agents pour 2026, en particulier pour les cas d'utilisation nécessitant une ségrégation de l'expertise du domaine. Mais il comporte plus de frais généraux d'orchestration que les systèmes à agent unique, ce qui est approprié pour les flux de travail complexes, mais excessif pour l'automatisation simple.
Microsoft Agent Framework : L'intégration d'entreprise d'abord
L'Agent Framework de Microsoft adopte une approche différente, en donnant la priorité aux exigences de l'entreprise telles que la sécurité, la conformité et l'intégration avec les écosystèmes Microsoft existants.
Selon la documentation officielle, Microsoft Agent Framework permet de créer des agents et des flux de travail multi-agents à la fois en .NET et en Python. Il comprend une intégration intégrée avec Azure OpenAI, OpenAI, Anthropic et Ollama, ainsi qu'une prise en charge native des serveurs Model Context Protocol (MCP).
Les principales caractéristiques de l'entreprise sont les suivantes
| Fonctionnalité | Description |
|---|
| Agents | Les agents individuels utilisent les LLM pour traiter les données d'entrée, les outils d'appel et les serveurs MCP, et générer des réponses. |
| Flux de travail | Orchestration multi-agents avec des dépendances de tâches définies |
| Support MCP | Intégration native avec Model Context Protocol pour un accès normalisé aux outils |
| Sécurité | Authentification, autorisation et enregistrement d'audit de niveau entreprise |
Le cadre vise les organisations déjà investies dans l'écosystème de Microsoft. Pour les équipes qui utilisent l'infrastructure Azure et les services d'IA de Microsoft, les frictions d'intégration diminuent considérablement. Pour tous les autres, les problèmes de verrouillage des fournisseurs nécessitent une évaluation minutieuse.
AutoGen : La recherche rencontre la production
Issu de Microsoft Research, AutoGen se concentre sur les systèmes multi-agents conversationnels. Le cadre permet aux agents d'avoir des conversations entre eux pour résoudre des tâches en collaboration.
La caractéristique distinctive d'AutoGen est son paradigme conversationnel. Plutôt que de modéliser explicitement des flux de travail ou des transitions d'état, les développeurs définissent des agents avec des capacités et les laissent négocier l'exécution des tâches par le dialogue. Cela fonctionne particulièrement bien pour les problèmes ouverts dont la solution n'est pas prédéterminée.
Le cadre soutient :
- Génération et exécution automatisées du code
- Utilisation d'outils par appel de fonction
- Modèles d'interaction entre l'homme et la boucle
- Modèles de conversation et conditions de fin de conversation configurables
Selon les praticiens qui ont utilisé plusieurs cadres, AutoGen fonctionne bien pour le prototypage. L'approche conversationnelle peut rendre difficile le débogage de flux de travail complexes lorsque les agents prennent des décisions inattendues.
Pydantic AI : Sécurité des types pour le développement d'agents
Pydantic AI apporte la sécurité des types et les capacités de validation de Pydantic au développement d'agents. Pour les équipes qui utilisent déjà Pydantic pour la validation des données dans les applications Python, ce cadre fournit des modèles familiers.
La proposition de valeur principale est centrée sur les résultats structurés. Les développeurs définissent des schémas pydantiques décrivant les réponses attendues de l'agent, et le cadre gère la validation et la coercition de type. Cela réduit le problème de l'hallucination en contraignant les sorties à correspondre aux structures attendues.
Fonctionne bien pour :
- Tâches d'extraction de données avec des schémas de sortie définis
- Flux de travail de classification et de catégorisation
- Génération de rapports structurés
- Tout cas d'utilisation où le format de sortie importe autant que le contenu
La limite ? L'IA de Pydantic reste principalement axée sur des scénarios à agent unique avec des résultats structurés. L'orchestration multi-agent complexe ou les flux de travail nécessitant une gestion d'état sophistiquée requièrent des outils supplémentaires.
Firecrawl : Collecte de données Web en tant qu'agent
Firecrawl adopte une approche spécialisée, en se concentrant spécifiquement sur la collecte de données web par le biais d'une interface agentique. Plutôt que de construire des agents polyvalents, il optimise le modèle commun de recherche, de navigation et d'extraction de données structurées à partir de sites web.
Selon la documentation du projet, les développeurs décrivent ce qu'ils veulent en texte clair, transmettent éventuellement un schéma Pydantique, et l'agent recherche, navigue et renvoie des résultats structurés. Firecrawl propose plusieurs modèles avec différents compromis performance-coût pour des extractions simples ou complexes.
Cette spécialisation signifie que Firecrawl excelle dans un domaine - la collecte de données Web - plutôt que d'essayer de prendre en charge tous les cas d'utilisation possibles de l'agent. Pour les équipes qui créent des agents de recherche, des systèmes de veille concurrentielle ou des outils de surveillance du marché, cette spécialisation apporte une valeur significative.

Des critères de sélection du cadre qui comptent vraiment
Le choix d'un framework d'agent basé sur les étoiles de GitHub ou les cycles d'engouement conduit à des réécritures coûteuses. Les frameworks qui fonctionnent en production sont sélectionnés sur la base de critères différents.
Alignement de l'architecture sur le domaine du problème
La première question n'est pas “quel est le meilleur cadre ?”. Il s'agit de savoir si l'architecture de ce cadre correspond à la manière dont ce problème se décompose naturellement.“
Les problèmes comportant des transitions d'état claires, des branchements conditionnels et des exigences en matière de reprise sur erreur s'inscrivent naturellement dans des cadres basés sur les graphes comme LangGraph. La gestion explicite des états correspond à la structure du problème.
Les tâches nécessitant une expertise spécialisée dans différents domaines - création de contenu, analyse financière, recherche de clients - fonctionnent bien avec des cadres multi-agents tels que CrewAI. Le modèle d'agent basé sur les rôles reflète la manière dont les équipes humaines abordent ces problèmes.
Les tâches de recherche ouvertes ou les flux de génération de code s'adaptent souvent mieux aux cadres conversationnels tels qu'AutoGen. Le chemin de la solution émerge du dialogue plutôt que de flux de travail prédéterminés.
L'extraction de données et la génération de sorties structurées s'alignent sur des cadres à sécurité de type tels que Pydantic AI. L'approche "schéma d'abord" réduit les hallucinations pour les tâches où le format est important.
Selon la recherche arXiv sur les options d'architecture pour les agents basés sur des modèles de fondation, cet alignement entre le domaine du problème et le paradigme architectural représente le facteur le plus important pour le succès à long terme.
Exigences de production au-delà de la fonctionnalité de base
Les prototypes expérimentaux et les systèmes de production ont des exigences fondamentalement différentes. Les cadres doivent être compatibles :
- Observabilité : Les développeurs peuvent-ils voir ce que font les agents, pourquoi ils prennent des décisions et où se produisent les défaillances ? Les systèmes de production nécessitent des capacités de journalisation, de traçage et de débogage détaillées.
- Gestion des erreurs : Comment le cadre gère-t-il les échecs de l'API, les limites de taux, les dépassements de délai et les sorties d'outils non valides ? Une récupération robuste des erreurs sépare les jouets des outils.
- Persistance de l'état : L'état de l'agent peut-il survivre au redémarrage du processus ? Les conversations persistent-elles d'une session à l'autre ? Les systèmes de production ont besoin d'une gestion durable des états.
- Contrôle des coûts : Le cadre fournit-il des mécanismes permettant de limiter l'utilisation des jetons, de plafonner les appels à l'API et d'empêcher une exécution incontrôlée ? Les agents non contrôlés deviennent rapidement coûteux.
- Limites de sécurité : Comment le framework gère-t-il l'authentification, l'autorisation et le sandboxing ? Les agents ayant accès à des outils ont besoin de contrôles de sécurité.
Ces exigences n'apparaissent pas dans les comparaisons de cadres axées sur les fonctionnalités. Mais elles déterminent la survie des agents en production.
Ecosystème d'intégration et support d'outils
Les agents tirent de la valeur de l'accès aux outils. Le cadre doit s'intégrer aux outils et services spécifiques dont l'application a besoin.
Certains cadres fournissent des intégrations préétablies étendues. D'autres offrent des mécanismes de définition d'outils flexibles mais nécessitent un code d'intégration personnalisé. Le compromis entre commodité et flexibilité dépend de l'existence ou non des intégrations nécessaires.
Selon la recherche arXiv sur les cadres d'IA agentique, le protocole de contexte de modèle (MCP) émerge comme une couche de normalisation pour l'accès aux outils. Les cadres qui prennent en charge le MCP de manière native ont accès à un écosystème croissant d'outils compatibles sans avoir à effectuer de travail d'intégration personnalisé.
Compétences d'équipe et courbe d'apprentissage
Différents cadres nécessitent différents modèles mentaux. Les systèmes basés sur des graphes nécessitent une réflexion sur les machines d'état et les transitions. Les systèmes multi-agents nécessitent une compréhension des protocoles de communication et des modèles de coordination. Les cadres conversationnels nécessitent différentes approches de débogage.
La courbe d'apprentissage est moins importante pour les nouveaux projets que pour les équipes chargées de la maintenance des systèmes existants. Il est rarement judicieux de changer de cadre en cours de projet, quel que soit le cadre qui semble le plus performant. Le coût de la migration est généralement supérieur aux avantages qu'elle procure.
Pour les équipes déjà investies dans des écosystèmes spécifiques - Microsoft Azure, LangChain, validation des données Pydantic - les cadres qui s'alignent sur les compétences existantes réduisent considérablement les frictions.
Les efforts de normalisation remodèlent le paysage
La prolifération de cadres d'agents incompatibles crée des problèmes de fragmentation. Les efforts de normalisation visent à résoudre ce problème.
Initiative de normalisation des agents d'intelligence artificielle du NIST
Le 17 février 2026, le National Institute of Standards and Technology (NIST) a annoncé l'initiative AI Agent Standards pour garantir des systèmes d'IA agentiques fiables, interopérables et sécurisés. Selon l'annonce officielle, l'initiative “garantira que la prochaine génération d'IA sera largement adoptée en toute confiance, qu'elle pourra fonctionner en toute sécurité au nom de ses utilisateurs et qu'elle pourra interopérer sans heurts dans l'écosystème numérique”.”
Il s'agit du premier effort gouvernemental majeur visant à établir des normes pour les architectures d'agents, les protocoles de sécurité et les mécanismes d'interopérabilité. L'initiative répond aux préoccupations concernant les systèmes d'agents fonctionnant sans cadres de sécurité cohérents ni normes d'interopérabilité.
Normes IEEE pour l'évaluation comparative des agents
La norme IEEE P3777 établit un cadre unifié pour l'évaluation comparative des agents d'intelligence artificielle, y compris les agents autonomes, collaboratifs et spécifiques à une tâche. Elle définit les principales mesures de performance, les protocoles d'évaluation et les exigences en matière de rapports pour permettre une évaluation transparente, reproductible et comparable des capacités et des compétences des agents.
Par ailleurs, la norme IEEE P3154.1 fournit une pratique recommandée pour un cadre d'application des agents d'intelligence artificielle aux services de gestion des talents, décrivant des cadres architecturaux et des domaines d'application avec des protocoles pour les mécanismes d'interaction et de communication.
Ces efforts de normalisation sont toujours en cours de développement. Mais ils montrent que l'industrie reconnaît que la fragmentation des cadres crée des problèmes pour le déploiement en production et l'adoption par les entreprises.
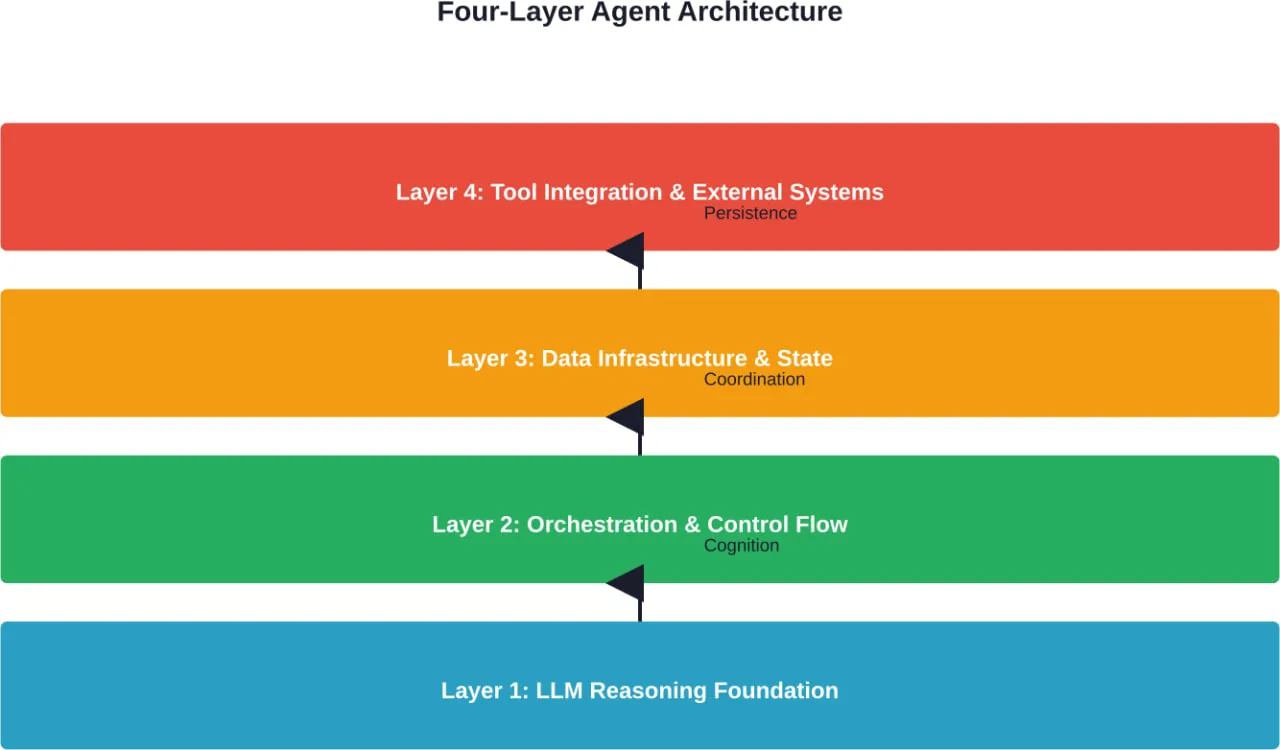
Comprendre les architectures d'agents et les modèles de conception
Au-delà des cadres spécifiques, des modèles architecturaux récurrents apparaissent dans les mises en œuvre réussies d'agents. La compréhension de ces modèles permet d'évaluer les cadres et de concevoir des solutions personnalisées.
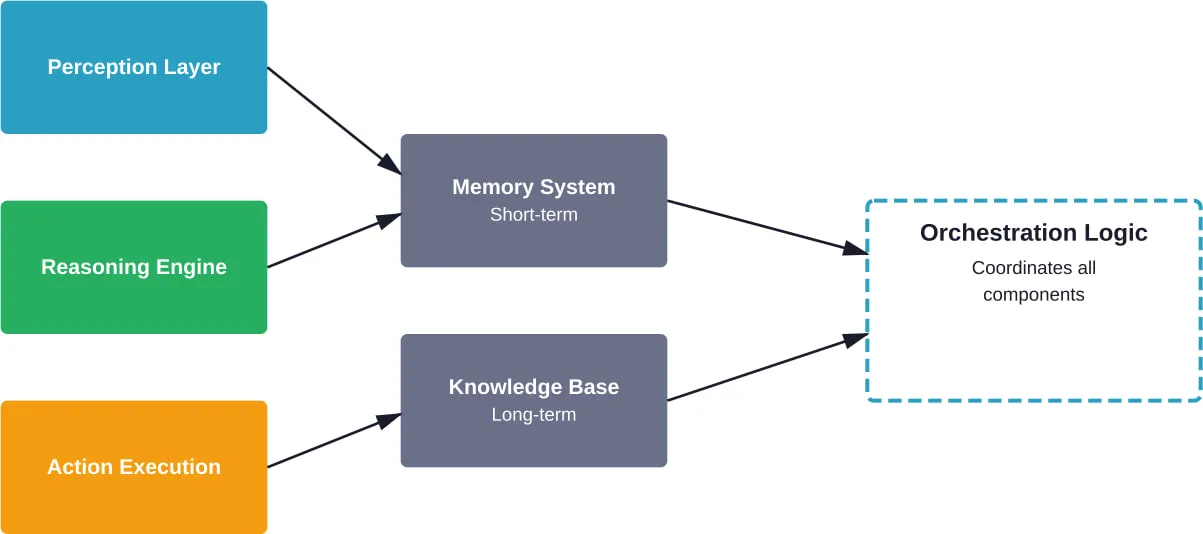
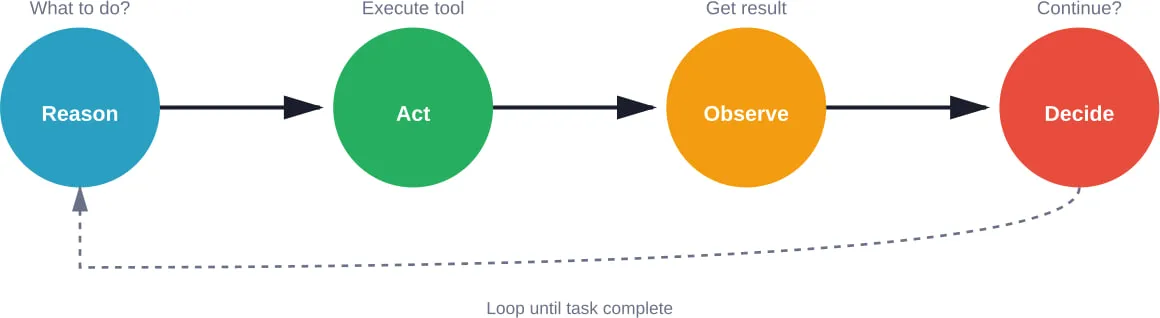
La boucle perception-cognition-action
Selon la recherche arXiv qui distingue les agents d'IA de l'IA agentique, les agents fonctionnent fondamentalement selon des cycles perception-cognition-action. La perception consiste à recueillir des informations sur l'environnement. La cognition englobe le raisonnement, la planification et la prise de décision. L'action exécute les décisions par l'utilisation d'outils ou la communication.
Cette boucle est mise en œuvre différemment d'un cadre à l'autre :
- Les cadres basés sur les graphes rendent la boucle explicite par le biais de transitions d'état.
- Les cadres conversationnels intègrent la boucle dans les tours de dialogue
- Les systèmes multi-agents répartissent la boucle entre des agents spécialisés.
Le choix de l'implémentation affecte la débogabilité, les caractéristiques de performance et les modes de défaillance. Les boucles explicites sont plus faciles à déboguer mais nécessitent une conception plus poussée. Les boucles implicites réduisent le nombre d'éléments parasites, mais rendent le flux de contrôle plus difficile à retracer.
Architectures de mémoire pour l'état des agents
Les agents ont besoin de mémoire pour conserver le contexte au fil des interactions. Les architectures de mémoire comprennent généralement
- Mémoire de travail : Contexte à court terme de la tâche ou de la conversation en cours
- Mémoire épisodique : Enregistrements des interactions passées et de leurs résultats
- La mémoire sémantique : Connaissances générales et faits appris
- Mémoire procédurale : Comment effectuer des tâches et utiliser des outils
Les cadres de production doivent conserver la mémoire entre les sessions et gérer les limites de la mémoire de manière gracieuse. Au fur et à mesure que les conversations prennent de l'ampleur, les agents doivent les résumer, oublier les détails non pertinents ou retrouver un contexte historique pertinent.
Certains frameworks proposent une gestion intégrée de la mémoire. D'autres laissent aux développeurs le soin de mettre en œuvre des mécanismes de persistance et de récupération.
Utilisation d'outils et modèles d'appel de fonctions
L'accès aux outils transforme les agents de chatbots en systèmes d'action. Les modèles les plus courants sont les suivants :
- Appel direct de fonctions : Le LLM génère des appels de fonction structurés avec des paramètres, le cadre les exécute et les résultats sont renvoyés à l'agent. Cela fonctionne bien pour les outils déterministes avec des schémas clairs.
- Descriptions d'outils en langage naturel : Les outils exposent des descriptions de capacités en langage naturel. L'agent décide quand et comment les utiliser sur la base des descriptions plutôt que de schémas rigides. Plus souple mais moins fiable.
- Exécution en chaîne des outils : Les agents peuvent utiliser les résultats de l'outil comme entrées pour les outils suivants. Permet des flux de travail complexes tels que “rechercher X, lire le premier résultat, le résumer, puis le traduire en français”.”
- Invocation d'outils en parallèle : Exécution simultanée de plusieurs outils indépendants. Réduit le temps de latence pour les tâches nécessitant des informations provenant de sources multiples.
Différents frameworks prennent en charge ces modèles avec des niveaux variables de prise en charge native et d'implémentation personnalisée.

Protocoles de communication multi-agents
Lorsque plusieurs agents collaborent, les protocoles de communication déterminent l'efficacité et la fiabilité. Selon la recherche arXiv sur les cadres d'IA agentique, les protocoles courants sont les suivants :
- Passage de messages : Les agents communiquent par le biais de messages explicites avec des schémas définis. Cela permet d'obtenir des pistes d'audit claires, mais nécessite la conception d'un protocole en amont.
- État partagé : Les agents lisent et écrivent dans la mémoire partagée ou dans les bases de données. Cette solution est simple à mettre en œuvre, mais elle crée des conditions de course et des conflits potentiels.
- Axé sur les événements : Les agents publient des événements et s'abonnent aux événements d'autres agents. Cela permet de découpler les agents mais rend le comportement global plus difficile à prévoir.
- Délégation hiérarchique : Les agents gestionnaires assignent des tâches aux agents travailleurs et regroupent les résultats. Le flux de contrôle est clair mais crée des goulets d'étranglement au niveau des nœuds gestionnaires.
Le choix du protocole a une incidence sur la complexité du débogage, la reprise sur panne et les caractéristiques d'évolutivité. Les systèmes de production ont souvent besoin de plusieurs protocoles pour différents modèles d'interaction.
Considérations relatives à l'entreprise et au déploiement de la production
Faire passer les agents du prototype à la production implique des défis qui vont au-delà de la sélection d'un cadre. Le déploiement en entreprise nécessite de répondre à des préoccupations en matière d'exploitation, de sécurité et de gouvernance.
Gestion des coûts et économie des jetons
Les agents disposant d'un accès aux outils et d'un raisonnement en plusieurs étapes consomment beaucoup plus de jetons que les simples chatbots. Un agent du service clientèle peut utiliser plus de 10 000 jetons par interaction lorsqu'il consulte des bases de connaissances, vérifie l'état d'une commande et génère des réponses.
Les systèmes de production ont besoin :
- Budget de jetons par interaction pour éviter l'explosion des coûts
- Stratégies de mise en cache pour les requêtes répétées ou les flux de travail courants
- Logique de sélection des modèles qui utilise des modèles moins coûteux pour des tâches simples
- Suivi et alerte lorsque les coûts dépassent les seuils
Certains cadres fournissent des contrôles de coûts intégrés. D'autres requièrent une mise en œuvre personnalisée de l'application du budget et de l'acheminement du modèle.
Limites de sécurité et contrôle d'accès
Les agents disposant d'un accès aux outils agissent au nom des utilisateurs. Les failles de sécurité peuvent exposer des données sensibles ou permettre des actions non autorisées.
Les exigences essentielles en matière de sécurité sont les suivantes
- Authentification pour vérifier l'identité de l'agent et l'autorisation de l'utilisateur
- Autorisation pour limiter les outils auxquels les agents peuvent accéder pour des utilisateurs spécifiques
- Validation des entrées pour prévenir les attaques par injection de données
- Filtrage des sorties pour éviter les fuites d'informations sensibles
- Enregistrement de toutes les actions de l'agent et de toutes les invocations d'outils
- Sandboxing pour isoler l'exécution de l'agent des systèmes critiques
Selon l'initiative de normalisation des agents d'IA du NIST, les protocoles de sécurité normalisés pour les agents sont toujours en cours d'élaboration. Les cadres actuels mettent en œuvre la sécurité avec des niveaux de sophistication variables.
Observabilité et débogage
Lorsque les agents échouent, il faut pouvoir les observer en détail pour en comprendre les raisons. Contrairement aux logiciels traditionnels où les traces de pile révèlent les problèmes, les défaillances des agents impliquent souvent des problèmes sémantiques - l'agent a mal compris l'intention, a récupéré des informations erronées ou a fait de mauvais choix d'outils.
L'observabilité de la production est nécessaire :
- Enregistrement détaillé du raisonnement de l'agent et des points de décision
- Traçage des appels d'outils avec les entrées, les sorties et les temps de latence
- Capacités de relecture des sessions pour reproduire les échecs
- Mesures des taux de réussite, des temps de latence et du coût par interaction
- Intégration à l'infrastructure de surveillance existante
Les cadres diffèrent considérablement en ce qui concerne la prise en charge de l'observabilité. Certains proposent de riches outils de débogage et une intégration avec les plateformes d'observabilité. D'autres laissent l'instrumentation aux développeurs.
Évaluation et assurance de la qualité
Les tests de logiciels traditionnels ne s'appliquent pas directement aux agents. Les tests unitaires déterministes ne peuvent pas valider les systèmes qui utilisent les LLM pour le raisonnement.
Selon les recherches menées dans le cadre du projet AutoChain, l'évaluation nécessite des cadres de test automatisés qui évaluent la capacité de l'agent dans différents scénarios d'utilisation. Cela implique
- Tests basés sur des scénarios avec des entrées utilisateur réalistes
- LLM d'évaluateurs qui évaluent la qualité des résultats
- Tests de régression pour détecter les dégradations de capacité
- Tests A/B pour comparer les configurations des agents
- Évaluation humaine pour l'évaluation subjective de la qualité
Peu de cadres fournissent des outils d'évaluation complets. La plupart des systèmes de production nécessitent des harnais de test personnalisés.
Tendances émergentes et orientations futures
Le paysage de l'encadrement des agents continue d'évoluer rapidement. Plusieurs tendances déterminent l'orientation de l'écosystème.
Modèle Contexte Protocole Adoption
Le protocole de contexte de modèle (MCP) vise à normaliser la manière dont les agents accèdent aux outils et aux systèmes externes. Au lieu que chaque cadre mette en œuvre une intégration d'outils personnalisée, le MCP fournit un protocole commun.
Les frameworks qui prennent en charge MCP en natif ont accès à un écosystème croissant d'outils compatibles sans avoir à effectuer le travail d'intégration spécifique au framework. Cela réduit l'une des principales sources d'enfermement dans un cadre : il est plus facile de passer d'un cadre à l'autre lorsque les intégrations d'outils sont basées sur un protocole plutôt que sur un cadre spécifique.
Cadres spécialisés pour les domaines verticaux
Les cadres à usage général tels que LangGraph et CrewAI fonctionnent dans tous les domaines. Mais des cadres spécialisés ciblant des secteurs verticaux spécifiques sont en train d'émerger.
L'accent mis par Firecrawl sur la collecte de données web illustre cette tendance. Plutôt que de prendre en charge tous les cas d'utilisation possibles de l'agent, il optimise pour un domaine et le fait bien.
Il faut s'attendre à davantage de cadres verticaux spécifiques pour des domaines tels que l'assistance à la clientèle, l'analyse de données, la création de contenu et le développement de logiciels. Les frameworks spécialisés peuvent faire des choix architecturaux qui améliorent l'expérience des développeurs dans leur domaine cible.
Amélioration de l'évaluation et de l'étalonnage des performances
Selon la norme IEEE P3777, l'industrie reconnaît la nécessité d'une évaluation comparative normalisée des agents. Les méthodes d'évaluation actuelles restent ad hoc et incohérentes.
L'amélioration des méthodes d'évaluation permettra
- Comparaison objective entre les cadres
- Détection de la régression lorsque les mises à jour du cadre affectent les capacités
- Optimisation des performances sur la base de paramètres mesurables
- Vérification de la conformité pour les industries réglementées
Les cadres qui intègrent des outils d'évaluation normalisés seront probablement adoptés plus rapidement par les entreprises.
Intégration avec le génie logiciel traditionnel
Actuellement, le développement d'agents semble souvent séparé de l'ingénierie logicielle traditionnelle. Outils différents, approches de test différentes, modèles de déploiement différents.
La tendance est à l'intégration. Les agents sont des composants de systèmes plus vastes plutôt que des applications autonomes. Cela nécessite
- Des frameworks d'agents qui s'intègrent aux pipelines CI/CD existants
- Cadres de test compatibles avec les programmes de test standard
- Les modèles de déploiement qui fonctionnent avec les plateformes d'orchestration de conteneurs
- Une surveillance qui s'intègre aux piles d'observabilité existantes
Les cadres qui réduisent le décalage entre le développement d'agents et l'ingénierie logicielle traditionnelle gagneront du terrain dans les environnements d'entreprise.
Stratégie de sélection du cadre pratique
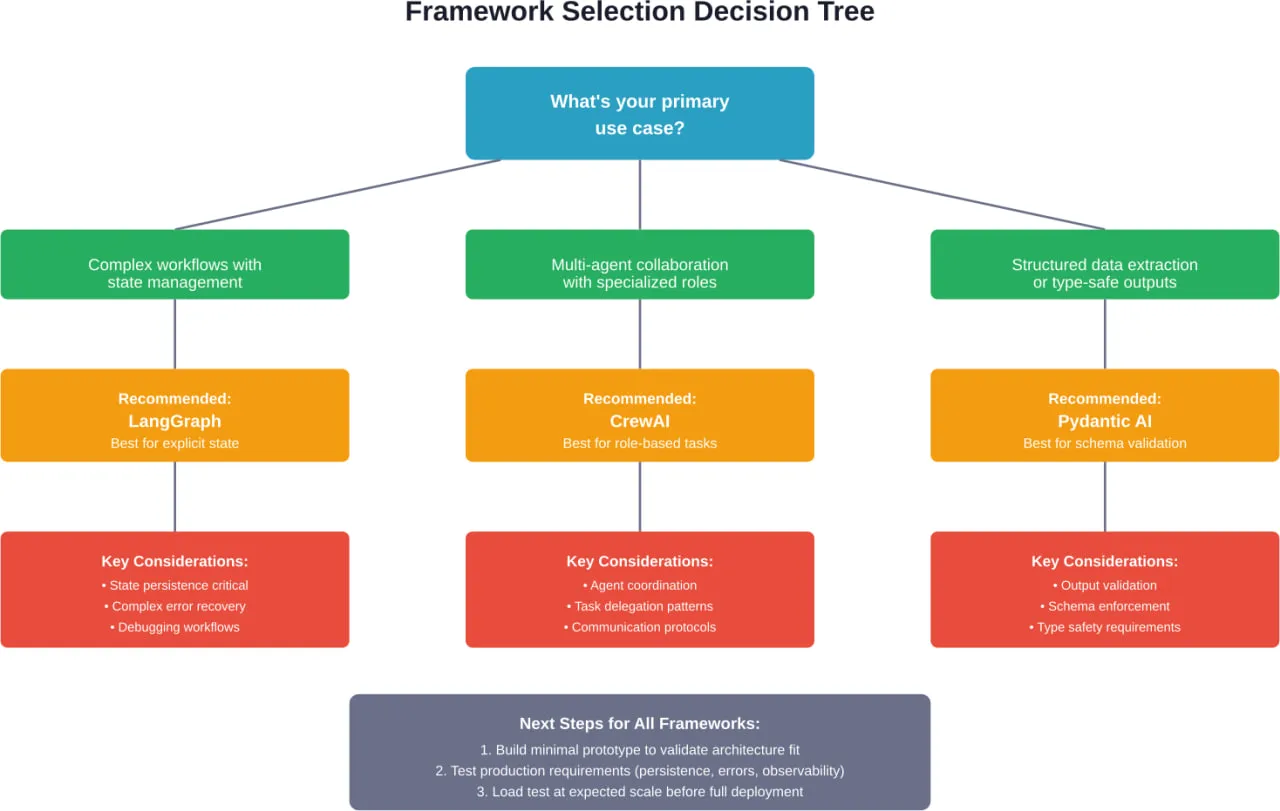
Compte tenu de la complexité et de l'évolution rapide, comment les équipes doivent-elles choisir les cadres ? Voici un processus de décision pratique.
Commencer par l'analyse de l'architecture des cas d'utilisation
Avant d'évaluer les cadres, il convient de faire correspondre le cas d'utilisation aux modèles architecturaux :
- Le problème implique-t-il une gestion d'état complexe avec des branchements conditionnels ? Envisagez des cadres basés sur les graphes.
- Cela nécessite-t-il la collaboration de plusieurs agents spécialisés ? Envisagez des cadres multi-agents.
- S'agit-il principalement d'une conversation avec accès à des outils ? Envisager des cadres conversationnels.
- La structure de sortie est-elle aussi importante que le contenu ? Envisagez des cadres à sécurité typographique.
- Est-il axé sur la collecte de données en ligne ? Envisagez des cadres spécialisés.
Cela permet de réduire considérablement le champ d'application avant d'évaluer des cadres spécifiques.
Prototype d'une complexité minimale
Construisez la version la plus simple possible qui teste l'hypothèse architecturale de base. N'ajoutez pas de fonctionnalités, d'intégrations ou d'améliorations. Validez simplement que l'architecture du framework est adaptée au problème.
Pour un agent d'assistance à la clientèle, le prototype de l'interaction la plus simple : question de l'utilisateur, recherche dans la base de connaissances, génération d'une réponse. Oubliez l'authentification, la journalisation, la gestion des erreurs, les cas limites.
Cela permet de déterminer si le modèle mental du cadre correspond au problème avant d'investir dans des fonctions de production.
Évaluer l'état de préparation de la production
Une fois l'adéquation architecturale validée, il convient d'évaluer les exigences de production :
| Exigence | Pourquoi c'est important | Comment évaluer |
|---|
| Persistance de l'État | Les agents doivent survivre aux redémarrages | Test de reprise de session après redémarrage du processus |
| Récupération des erreurs | Les pannes d'outils sont fréquentes | Injecter des échecs et des délais d'attente dans l'API, vérifier le traitement gracieux. |
| Observabilité | Le débogage nécessite de la visibilité | Examiner les journaux pour détecter les interactions qui ont échoué, évaluer la possibilité de débogage |
| Contrôle des coûts | L'emballement de l'utilisation des jetons devient coûteux | Vérifier l'application du budget et les mécanismes de mise en cache |
| Sécurité | Les agents accèdent aux systèmes sensibles | Examiner l'authentification, l'autorisation et le sandboxing |
Les cadres qui échouent à ces évaluations créent une dette technique dont la réparation ultérieure devient coûteuse.
Tenir compte de l'enfermement de l'écosystème
Certains cadres sont plus verrouillés que d'autres. Évaluer :
- Le cadre utilise-t-il des protocoles standard (MCP) ou des intégrations personnalisées ?
- La logique de l'agent peut-elle être extraite et portée à d'autres cadres ?
- Le cadre est-il lié à des fournisseurs de LLM ou à des plates-formes en nuage spécifiques ?
- Le cadre est-il ouvert à tous et la communauté est-elle active dans son développement ?
Le verrouillage n'est pas nécessairement mauvais si le cadre offre une valeur suffisante. Mais la décision doit être délibérée plutôt qu'accidentelle.
Test à l'échelle prévue
Les caractéristiques de performance changent radicalement à l'échelle. Un cadre d'agent qui fonctionne bien pour 10 demandes par minute peut échouer à 100.
Testez la charge avec des modèles de trafic réalistes avant de vous engager dans le déploiement de la production. Mesurer :
- Percentiles de latence (p50, p95, p99)
- Limites de débit et goulets d'étranglement
- Utilisation de la mémoire et besoins en ressources
- Coût par interaction à l'échelle
- Taux d'erreur sous charge
Les tests d'échelle révèlent des problèmes qui n'apparaissent pas lors du développement.

Les pièges les plus courants et comment les éviter
Les équipes qui créent des agents commettent des erreurs prévisibles. Reconnaître ces schémas permet d'éviter des réécritures coûteuses.
Sur-ingénierie des mises en œuvre initiales
La tentation de construire des systèmes multi-agents sophistiqués avec une orchestration complexe dès le premier jour tue les projets. Commencez simplement. Un seul agent, des outils de base, une gestion minimale des états.
N'ajoutez de la complexité que lorsque les approches plus simples échouent. Un seul agent bien conçu est souvent plus performant que trois agents spécialisés mal coordonnés.
Ignorer l'économie des jetons jusqu'à la production
Les environnements de développement avec des budgets API illimités cachent les problèmes de coûts. Les environnements de production avec un trafic réel les révèlent douloureusement.
Mettre en place des budgets symboliques et un suivi dès le départ. Rendre les coûts visibles pendant le développement, et non après le déploiement.
Traiter les agents comme des logiciels traditionnels
Les modèles traditionnels de test, de débogage et de déploiement ne se traduisent pas directement. Les équipes qui tentent d'intégrer de force les agents dans les processus existants créent des frictions.
Investir dans des outils spécifiques aux agents pour l'évaluation, l'observabilité et le déploiement. Le coût initial est rentabilisé par la réduction du temps de débogage et l'accélération des itérations.
Choisir un cadre de travail en fonction de l'engouement qu'il suscite
Les étoiles GitHub et les mentions dans les bulletins d'information ne permettent pas de prédire le succès de la production. Les frameworks qui survivent à la production ont des caractéristiques différentes de celles des frameworks qui font l'objet d'un battage médiatique.
L'évaluation se fonde sur l'adéquation architecturale et l'aptitude à la production, et non sur des critères de popularité.
Sous-estimer la complexité du débogage
Lorsque les agents échouent, le mode d'échec est souvent lié à un malentendu sémantique plutôt qu'à des bogues dans le code. Les approches traditionnelles de débogage ne fonctionnent pas.
Prévoir des investissements importants dans les outils d'observabilité, la journalisation et les capacités de relecture des sessions. Le débogage des agents nécessite des outils différents de ceux utilisés pour le débogage des logiciels traditionnels.
Transformez votre cadre d'agent d'IA en un système opérationnel
Le choix d'un cadre est la partie la plus facile. La plupart des défis viennent de l'intégration - API, flux de données, logique de backend, et faire en sorte que tout fonctionne de manière fiable en production.
A-listware fournit des équipes de développement pour gérer cette couche. L'entreprise prend en charge le backend, les intégrations et l'infrastructure autour des systèmes d'IA, en aidant les équipes à passer des cadres sélectionnés à des déploiements stables. Si votre cadre a été choisi mais n'a pas été mis en œuvre, contactez Logiciel de liste A pour soutenir l'intégration et le déploiement.
Questions fréquemment posées
- Quelle est la différence entre un cadre d'agent d'IA et une API LLM ordinaire ?
Les API LLM fournissent des capacités de génération de texte - le texte d'entrée entre, le texte de sortie sort. Les cadres d'agents d'IA ajoutent l'orchestration, la gestion des états, l'intégration d'outils et le raisonnement en plusieurs étapes aux LLM. Ils permettent aux agents de percevoir les environnements, de prendre des décisions, d'utiliser des outils et d'exécuter des flux de travail de manière autonome plutôt que de simplement générer des réponses textuelles.
- Quel est le meilleur système d'agent d'IA pour les débutants ?
Pydantic AI offre la courbe d'apprentissage la plus basse pour les développeurs déjà familiers avec Python et Pydantic. Il offre une sécurité de type et des résultats structurés sans nécessiter une compréhension approfondie des modèles d'orchestration d'agents. Pour les équipes qui découvrent à la fois les agents et Python, les cadres conversationnels tels qu'AutoGen offrent une prise en main plus douce que les systèmes basés sur les graphes tels que LangGraph.
- Ai-je besoin d'un cadre multi-agents ou un seul agent suffit-il ?
Commencez par des architectures à agent unique, à moins que le problème ne nécessite clairement une expertise spécialisée dans plusieurs domaines. Les systèmes multi-agents ajoutent une surcharge de coordination, une complexité de débogage et des coûts. Ils sont utiles lorsque les tâches se décomposent naturellement en rôles distincts avec des exigences différentes en matière de connaissances - comme la recherche, l'analyse et la rédaction de rapports - mais la plupart des cas d'utilisation fonctionnent bien avec un seul agent bien conçu.
- Comment gérer les problèmes d'enfermement dans un cadre ?
Privilégier les frameworks avec un support de protocole standard comme le Model Context Protocol (MCP) pour l'intégration d'outils. Séparer la logique métier du code d'orchestration spécifique au framework. Utiliser des couches d'abstraction pour l'accès aux fournisseurs LLM afin que le changement de fournisseur ne nécessite pas de modification du framework. Évaluer si les avantages du cadre justifient les coûts de verrouillage avant de s'engager - parfois le verrouillage est acceptable si le cadre fournit une valeur suffisante.
- Quels sont les coûts typiques de l'exploitation d'agents d'intelligence artificielle en production ?
Les coûts varient considérablement en fonction de la complexité de l'agent, de l'utilisation des jetons par interaction, du volume de trafic et du choix du modèle. Un simple agent d'assistance à la clientèle peut utiliser entre 5 000 et 15 000 jetons par conversation. Avec la tarification GPT-4, cela représente $0.15-$0.45 par interaction. Les agents de recherche complexes qui utilisent beaucoup d'outils peuvent utiliser plus de 50 000 jetons par tâche. Les coûts de production nécessitent un contrôle minutieux, des stratégies de mise en cache et un routage des modèles afin d'optimiser le compromis coût-qualité.
- Comment les normes du NIST influencent-elles la sélection du cadre de travail des agents d'IA ?
Selon l'initiative de normalisation des agents d'IA annoncée en février 2026, le NIST élabore des normes pour la sécurité, l'interopérabilité et la fiabilité des agents. Bien que ces normes soient encore en cours d'élaboration, les cadres qui s'alignent sur les normes émergentes relatives aux protocoles d'authentification, à l'enregistrement des audits et aux mécanismes d'interopérabilité auront probablement plus de facilité à être adoptés par les entreprises. Pour les secteurs réglementés, la conformité du cadre aux normes éventuelles du NIST pourrait devenir une exigence stricte.
- Puis-je changer de cadre après avoir créé un agent de production ?
Techniquement, oui, mais les coûts de migration sont importants. Les modèles d'orchestration, les approches de gestion des états et les intégrations d'outils spécifiques au cadre ne sont pas portés directement. Il faut s'attendre à réécrire des parties substantielles de la logique de l'agent pendant la migration. La décision de changer de framework doit être basée sur des limitations techniques claires qui justifient le coût de la migration, et non sur des différences de fonctionnalités mineures ou sur le battage médiatique autour de frameworks plus récents.
Prendre la décision-cadre
Aucun cadre ne domine tous les cas d'utilisation. LangGraph excelle dans les flux de travail complexes avec une gestion explicite des états. CrewAI brille pour la collaboration multi-agents avec spécialisation des rôles. Microsoft Agent Framework optimise l'intégration dans l'entreprise. Pydantic AI assure la sécurité des types pour les résultats structurés. Des cadres spécialisés comme Firecrawl optimisent les domaines spécifiques.
Le bon choix dépend de l'alignement architectural entre le domaine du problème et le paradigme du cadre, des exigences de production concernant la persistance de l'état et la récupération des erreurs, de l'écosystème d'intégration et des besoins en matière d'outils, ainsi que des compétences de l'équipe et des considérations relatives à la courbe d'apprentissage.
Selon la recherche arXiv sur les cadres d'IA agentique, cet alignement architectural représente le facteur de réussite le plus important. Les cadres qui correspondent à la manière dont les problèmes se décomposent naturellement conduisent à des implémentations plus propres, à un débogage plus facile et à des systèmes plus faciles à maintenir.
Commencer simple. Validez l'adéquation de l'architecture avec des prototypes minimaux avant de créer des fonctionnalités de production. Tester à l'échelle prévue avant de s'engager dans le déploiement. Investir dès le départ dans des outils d'observation et d'évaluation.
Le paysage des cadres d'agents continue d'évoluer. Les efforts de normalisation du NIST et de l'IEEE signalent la maturation de l'industrie. L'adoption du protocole de contexte de modèle réduit l'enfermement dans le cadre. Des cadres verticaux spécialisés apparaissent pour des domaines spécifiques.
Mais les principes fondamentaux restent constants : comprendre l'architecture du problème, choisir les cadres qui correspondent à cette architecture et valider l'état de préparation à la production avant le déploiement. Les équipes qui suivent cette approche produisent des agents qui survivent à la production. Celles qui suivent les cycles d'engouement finissent par réécrire.
Prêt à créer votre premier agent de production ? Commencez par le cadre qui correspond à l'architecture naturelle de votre problème. Construisez la version la plus simple qui prouve le concept. Ensuite, itérez en fonction de ce que la production vous apprend.