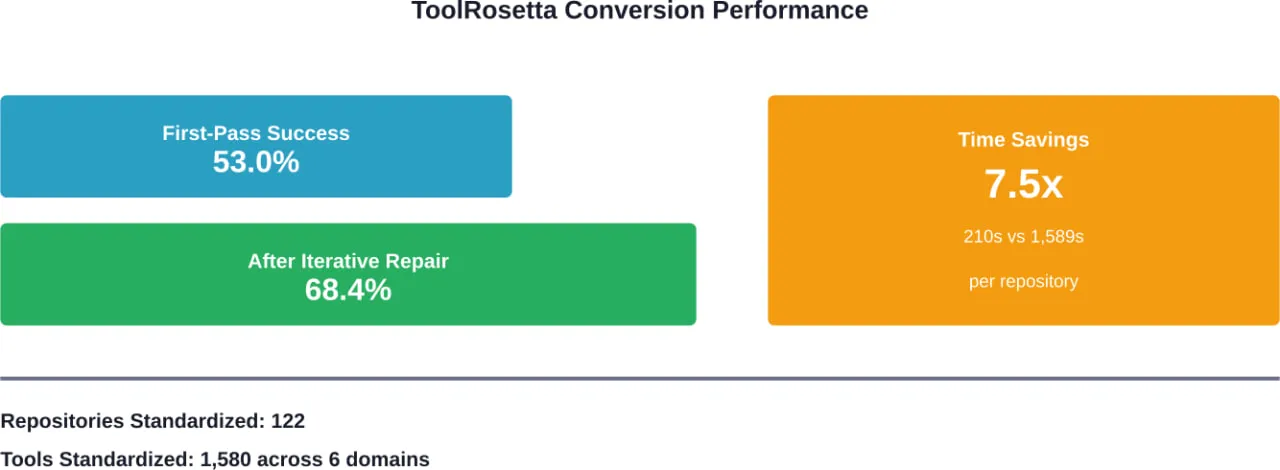
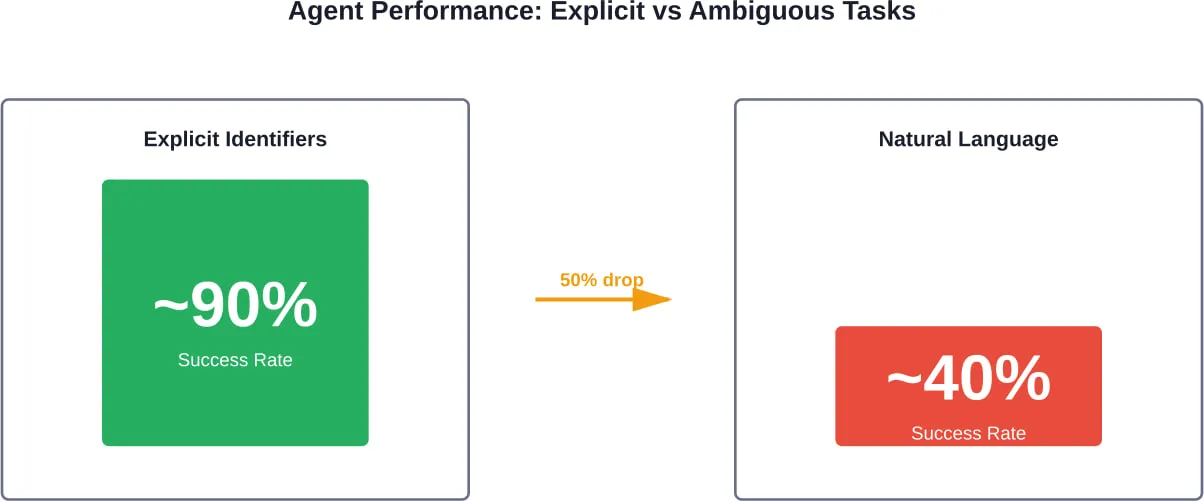
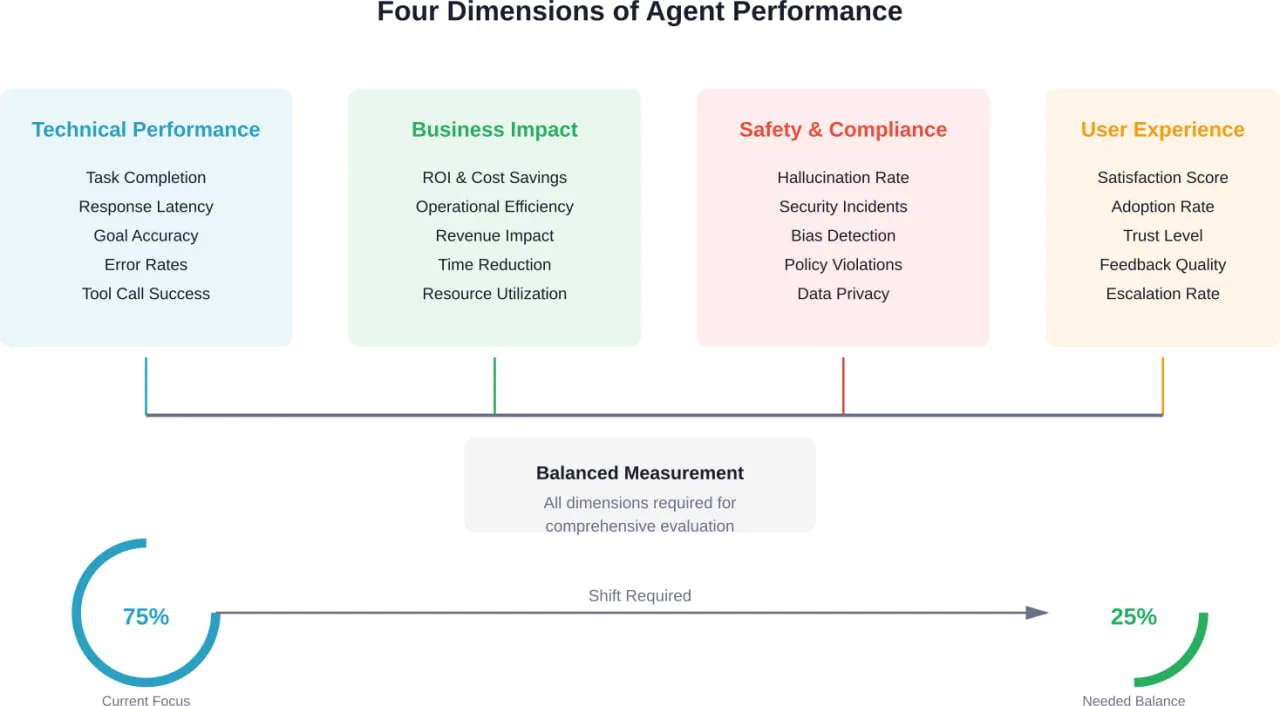
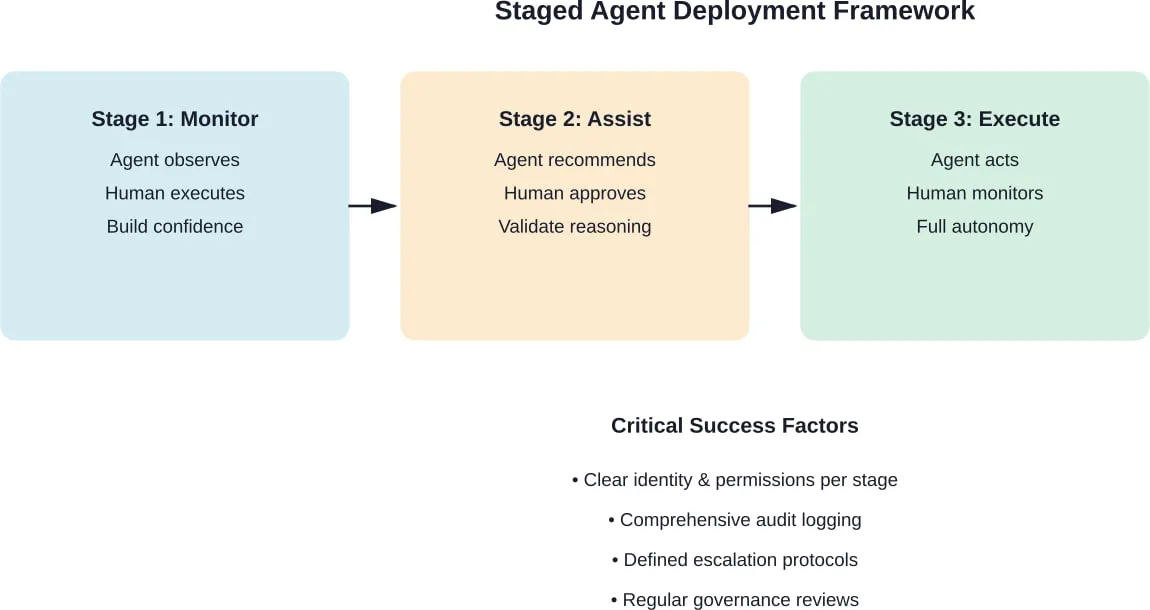
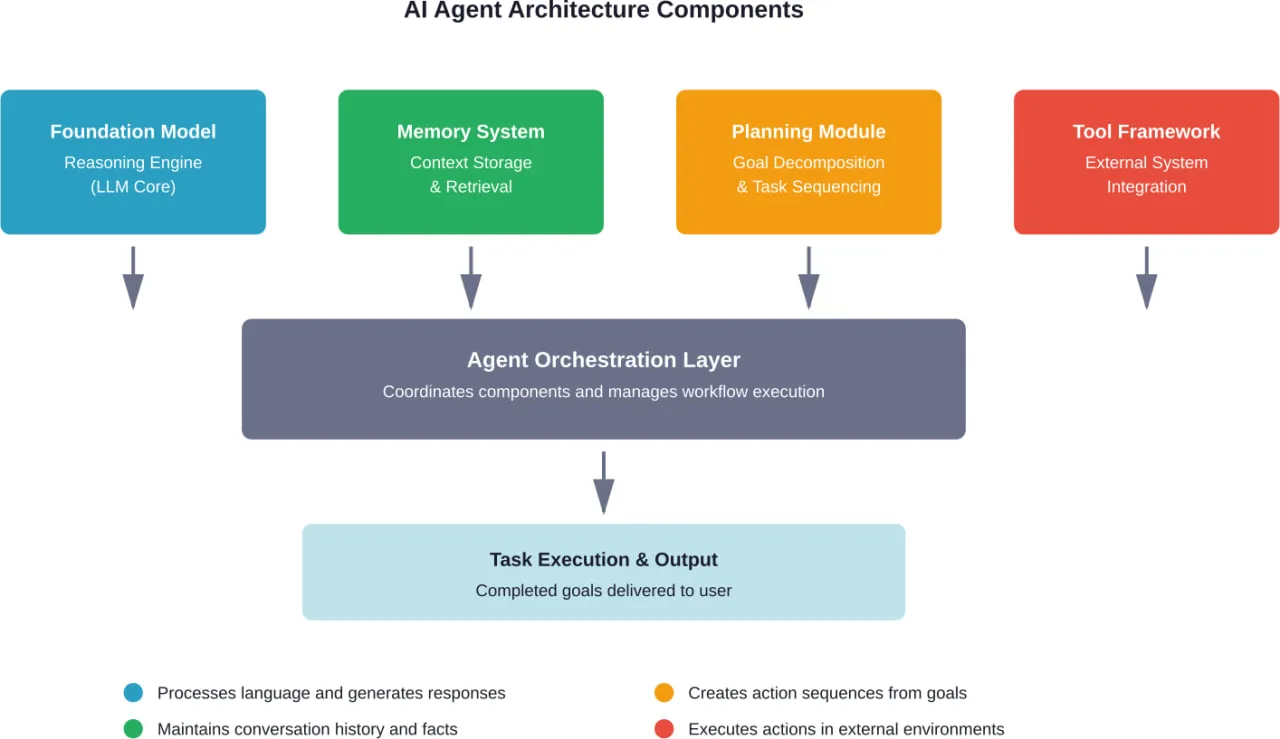
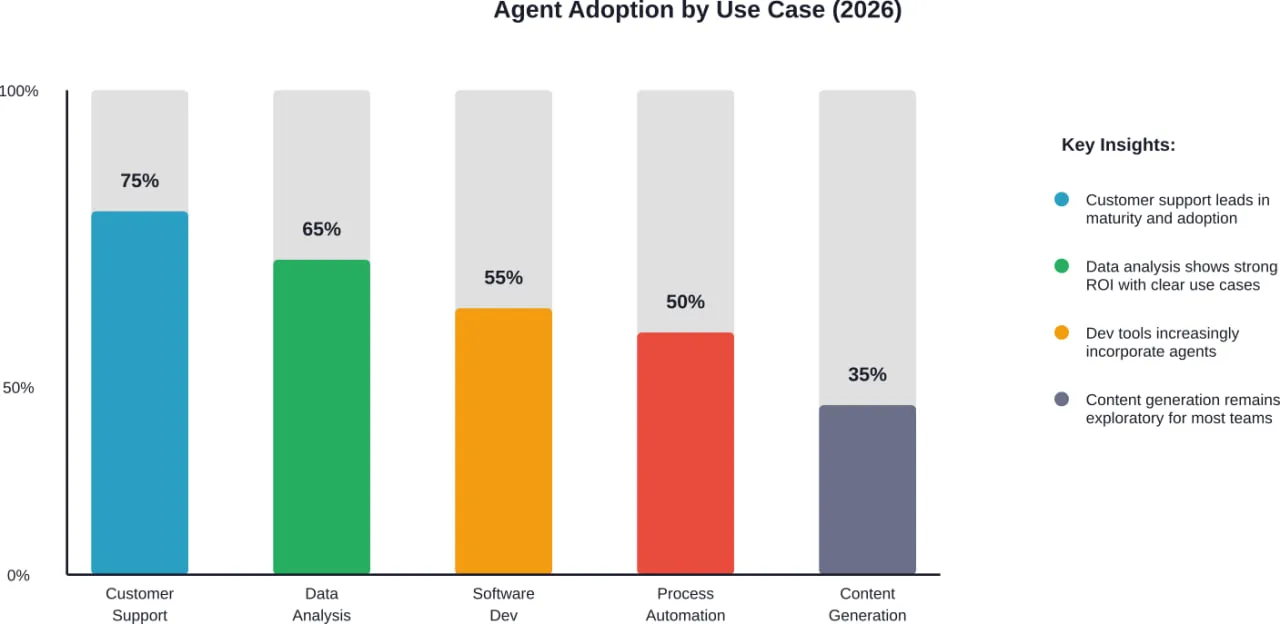
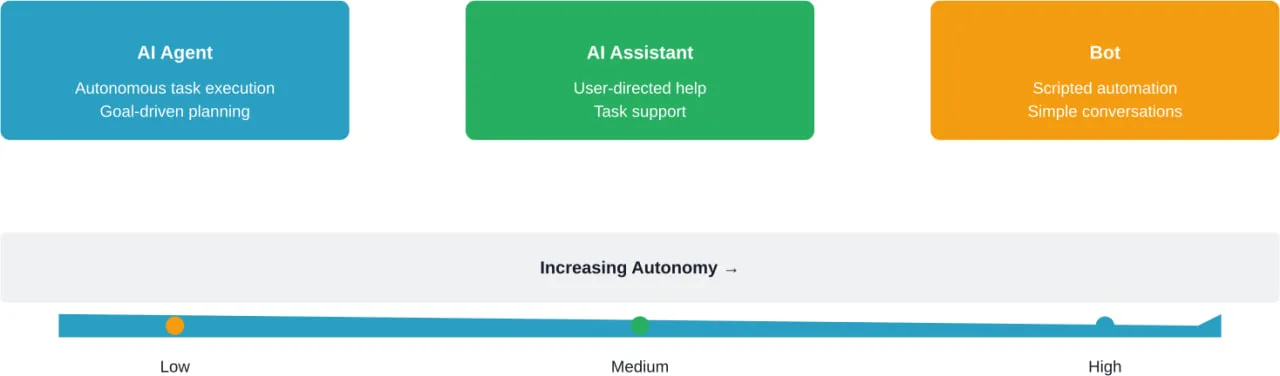
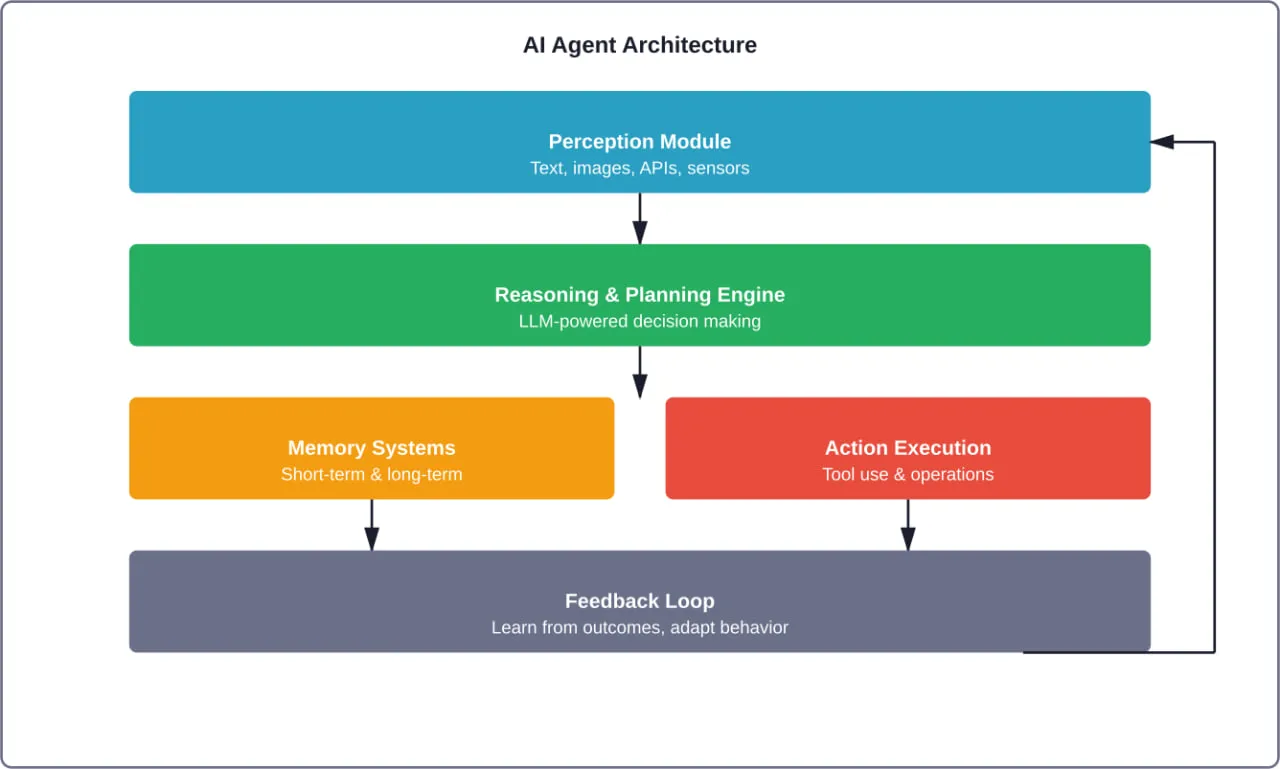
AI agents are starting to show up in places that used to need constant human attention – customer support queues, internal workflows, data lookups, even bits of decision-making. Not as a big replacement, but as something that quietly takes work off people’s plates.
Still, most teams run into the same question pretty quickly: where do these agents actually make sense?
There’s no shortage of platforms claiming to “automate everything,” but in practice, the value tends to come from narrower, well-defined tasks, things that follow patterns, repeat often, and don’t fall apart when handed off.
Below is a look at the current landscape of AI agent tools and platforms. Not a ranking, and not a guide on what to pick, just a way to understand what’s out there and how different approaches are taking shape.
Make AI Agents Work Inside Real Business Systems

AI agents rarely operate on their own. They depend on backend systems, APIs, integrations, and stable infrastructure to function reliably in a business environment.
That’s where Програмне забезпечення списку А comes in. The company focuses on software development and dedicated engineering teams that handle architecture, development, and ongoing support, forming the foundation behind AI-driven features once they move beyond the prototype stage.
If you’re working on AI agents, A-listware can help you:
- connect services, APIs, and internal systems around your agents
- manage data flows and integrations across your business tools
- maintain stability and performance over time
Turn AI agents into a working part of your business with Програмне забезпечення списку А.
![]()
1. Cognigy
Cognigy presents itself as a platform focused on building and running AI agents in customer-facing environments, mostly around support and contact centers. The product is centered on handling conversations across channels like voice, chat, and messaging, while also supporting human agents with tools like real-time assistance and access to internal knowledge. It leans into structured automation – routing requests, resolving common issues, and reducing the need for manual handling in repetitive cases.
What stands out is how the platform ties different parts of customer interaction into one system. There’s an emphasis on combining language understanding with integrations into existing infrastructure, so AI agents can actually complete tasks, not just respond. At the same time, it keeps human agents in the loop through copilots and shared context, which suggests it’s not meant to fully replace support teams but to reduce load and make workflows more manageable.
Основні моменти:
- AI agents for voice, chat, and messaging channels
- Focus on customer service and contact center operations
- Real-time support tools for human agents (copilot)
- Інтеграція з існуючими системами підприємства
- Multilingual support with translation capabilities
- Combines automation with human-assisted workflows
Who It’s Best For:
- Teams managing large volumes of customer support requests
- Companies running multi-channel customer communication
- Organizations looking to reduce repetitive support tasks
- Enterprises with existing contact center infrastructure
Контактна інформація:
- Website: www.cognigy.com
- Email: info-us@cognigy.com
- Facebook: www.facebook.com/cognigy
- Twitter: x.com/cognigy
- LinkedIn: www.linkedin.com/company/cognigy
- Address: 2400 N Glenville Drive, Building B, Suite 400, Richardson , Texas 75082
- Phone: +1 972 301 1300

2. Fellow
Fellow is centered around meetings and everything that happens around them. It records, transcribes, and summarizes conversations, then turns that information into something usable – notes, action items, follow-ups, or updates in other systems. The AI agent layer sits on top of that, letting users search across past meetings or generate outputs based on what was discussed.
There’s a noticeable focus on control and privacy. Recordings and notes are kept centralized, but access is managed quite tightly, which makes sense given how sensitive internal meetings can be. It also connects with tools people already use, so meeting insights don’t just stay as notes but move into workflows like CRM updates or task management.
Основні моменти:
- AI meeting recording, transcription, and summaries
- Searchable meeting history with generated outputs
- Centralized storage with access controls
- CRM and workflow integrations
- Pre-meeting planning and agendas
- Works across major meeting platforms
Who It’s Best For:
- Teams with frequent internal and client meetings
- Organizations that rely on documentation and follow-ups
- Sales, customer success, and leadership teams
- Companies needing structured meeting records
Контактна інформація:
- Website: fellow.ai
- Facebook: www.facebook.com/fellowmeetings
- Twitter: x.com/FellowAInotes
- LinkedIn: www.linkedin.com/company/fellow-ai
- Instagram: www.instagram.com/FellowAInotes
- Address: 532 Montréal Rd #275, Ottawa, ON K1K 4R4, Canada

3. Glean
Glean is built around internal company knowledge and how employees interact with it. It connects to different tools across the organization and makes that information searchable, then layers AI agents on top to help automate tasks or generate outputs based on that data. Instead of focusing on one workflow, it spreads across multiple functions like engineering, support, HR, and sales.
What stands out is the way it treats data as a shared resource. The system pulls from documents, conversations, and tools, then uses that context to answer questions or trigger actions. Agents can be created to handle specific types of work, but they all rely on the same underlying knowledge layer, which keeps things consistent across teams.
Основні моменти:
- Unified search across company tools and data
- AI agents for automating internal workflows
- Connectors to a wide range of applications
- Content generation and summarization
- Support for multiple departments and use cases
- Centralized knowledge layer
Who It’s Best For:
- Companies with fragmented internal tools and data
- Teams that rely on documentation and shared knowledge
- Organizations looking to automate internal processes
- Mid to large teams with cross-functional workflows
Контактна інформація:
- Website: www.glean.com
- App Store: apps.apple.com/us/app/glean-work/id1582892407
- Google Play: play.google.com/store/apps/details?id=com.glean.app
- Twitter: x.com/glean
- LinkedIn: www.linkedin.com/company/gleanwork
- Instagram: www.instagram.com/gleanwork
- Address: 634 2nd Street, San Francisco, CA 94107, United States

4. Decagon
Decagon is built around customer-facing AI agents, with a focus on handling interactions across channels like chat, voice, and email. The platform leans into the idea of agents acting more like a front layer for customer communication – not just answering questions, but completing actions like rebooking, updating accounts, or handling requests that usually require a human operator.
Instead of relying on rigid configuration, the system introduces workflows defined in more natural language, which makes iteration a bit less technical. There’s also a clear emphasis on ongoing adjustment – testing, observing, and refining how agents behave over time. The setup suggests that agents are expected to evolve alongside the business, not stay fixed after deployment.
Основні моменти:
- AI agents for chat, voice, and email
- Focus on customer interaction and task completion
- Workflow definition using natural language
- Built-in testing and iteration tools
- Analytics tied to conversations and behavior
- Omnichannel support from a single system
Who It’s Best For:
- Customer support and service operations
- Businesses handling requests across multiple channels
- Teams that need flexible, evolving workflows
- Companies aiming to automate repetitive interactions
Контактна інформація:
- Website: decagon.ai
- Twitter: x.com/DecagonAI
- LinkedIn: www.linkedin.com/company/decagon-ai

5. HubSpot Breeze Data Agent
HubSpot Breeze Data Agent is an AI agent built around customer data rather than direct conversations. It pulls information from different sources like CRM records, emails, calls, and documents, then uses that context to answer questions or surface insights. The goal is to reduce the time spent manually searching across tools when trying to understand customers or track what’s going on.
Inside the HubSpot environment, it works as part of existing workflows instead of sitting separately. Outputs are structured in a way that feeds back into the system – updating records, filling gaps in data, or helping teams act on information that already exists but is spread across different places.
Основні моменти:
- AI agent focused on customer data analysis
- Pulls information from CRM, emails, calls, and documents
- Answers custom business questions based on available data
- Creates and updates structured customer records
- Works within existing HubSpot workflows
- Connects fragmented data into a unified view
Who It’s Best For:
- Teams working closely with CRM systems
- Marketing and sales operations
- Organizations with data spread across multiple tools
- Teams that need quick access to customer insights
Контактна інформація:
- Веб-сайт: www.hubspot.com
- Facebook: www.facebook.com/hubspot
- Twitter: x.com/HubSpot
- LinkedIn: www.linkedin.com/company/hubspot
- Instagram: www.instagram.com/hubspot
- Адреса: 2 Canal Park, Cambridge, MA 02141, United States
- Телефон: +1 888 482 7768

6. ClickUp Super Agents
ClickUp approaches AI agents as part of a broader work environment rather than a separate tool. Super Agents are designed to take on a wide range of tasks – writing, analyzing, managing workflows, updating records, and more – all within the same workspace where teams already manage projects and communication.
There’s a strong focus on flexibility. Agents can be created for almost any type of work, and they can interact with tasks, documents, and people directly. The system also allows multiple agents to operate together, which makes it feel less like a single assistant and more like a layer of automation across the entire workflow.
Основні моменти:
- AI agents embedded in a project management workspace
- Handles tasks like writing, analysis, and coordination
- Custom agents for different types of work
- Multi-agent collaboration within workflows
- Integration with tasks, docs, and communication
- Continuous learning and context awareness
Who It’s Best For:
- Teams managing projects and workflows in one platform
- Organizations looking to automate daily operations
- Cross-functional teams with varied tasks
- Users who want AI inside their existing workspace
Контактна інформація:
- Website: clickup.com
- Facebook: www.facebook.com/clickupprojectmanagement
- Twitter: x.com/clickup
- LinkedIn: www.linkedin.com/company/12949663
- Instagram: www.instagram.com/clickup

7. Devin
Devin is positioned as an AI agent focused on software development work. Instead of assisting with small tasks, it’s designed to handle larger pieces of engineering work – writing code, debugging, testing, and managing parts of the development process. The idea is closer to an autonomous contributor that can take a task and work through it step by step.
What makes it different is the scope. It’s not limited to generating snippets or suggestions, but operates across the full workflow – planning, executing, and refining code. At the same time, it still fits into existing development environments, interacting with tools and processes that engineers already use.
Основні моменти:
- AI agent for software development tasks
- Handles coding, debugging, and testing
- Works across full development workflows
- Operates with some level of autonomy
- Integrates with developer tools and environments
- Focus on task execution, not just suggestions
Who It’s Best For:
- Engineering teams and developers
- Companies building software products
- Teams with repetitive or structured coding tasks
- Organizations exploring AI-assisted development
Контактна інформація:
- Website: devin.ai
- Twitter: x.com/cognition
- LinkedIn: www.linkedin.com/company/cognition-ai-labs

8. Intercom (Fin AI Agent)
Intercom builds its AI agent, Fin, directly into a customer support platform. Instead of adding AI as a separate layer, it’s part of the helpdesk itself, working alongside human agents in the same system. Conversations, tickets, and customer data all live in one place, which means the agent and the team operate with the same context.
Another part of the setup is how the system improves over time. Interactions are analyzed, patterns are tracked, and the agent adjusts based on previous conversations and human input. There’s also a strong connection between automation and manual support, where tasks can move between AI and human agents without losing context.
Основні моменти:
- AI agent integrated into a helpdesk platform
- Shared workspace for AI and human agents
- Omnichannel communication in one system
- Automated ticketing and routing
- Insights from conversation data
- Continuous improvement based on interactions
Who It’s Best For:
- Customer support teams using helpdesk systems
- Companies handling ongoing customer conversations
- Teams needing both automation and human support
- Organizations focused on structured support workflows
Контактна інформація:
- Website: www.intercom.com
- Email: press@intercom.com

9. Tableau
Tableau is built around data analysis and visualization, with a growing focus on what it calls agentic analytics. The platform connects to different data sources and turns that data into visual insights that people can explore and share. Alongside that, it introduces AI-driven features that help move from simply viewing data to acting on it, including systems that can suggest or trigger actions based on insights.
The setup is not limited to one environment. It can run in the cloud, on private infrastructure, or as part of a broader Salesforce ecosystem. Instead of replacing analysts, the platform leans toward supporting how people already work with data, while adding a layer where AI can assist with interpretation, exploration, and in some cases, automation of follow-up steps.
Основні моменти:
- Data visualization and analytics platform
- AI features for insight generation and actions
- Works across cloud and self-hosted environments
- Integration with multiple data sources
- Supports data exploration and reporting workflows
- Part of a broader analytics and CRM ecosystem
Who It’s Best For:
- Data analysts and business intelligence teams
- Organizations working with large datasets
- Teams needing visual reporting and dashboards
- Companies building data-driven workflows
Контактна інформація:
- Веб-сайт: www.tableau.com
- Facebook: www.facebook.com/Tableau
- Twitter: x.com/tableau
- LinkedIn: www.linkedin.com/company/tableau-software
- Адреса: 415 Mission Street, 3-й поверх, Сан-Франциско, Каліфорнія, 94105, США
- Телефон: 1-800-270-6977

10. Hightouch
Hightouch positions itself around marketing workflows driven by data and AI agents. It sits on top of a company’s existing data warehouse and uses that data to power campaigns, personalization, and audience management. The agent layer is used to automate parts of marketing execution, from building segments to deciding what message should be sent to which user.
Rather than moving data into a separate system, it works directly with what already exists. This changes how marketing teams interact with data – less exporting and syncing, more direct usage. The platform also includes decisioning logic, where AI evaluates signals and adjusts messaging or timing based on user behavior across channels.
Основні моменти:
- AI agents for marketing workflows and campaigns
- Built on top of existing data warehouses
- Audience building and segmentation tools
- Real-time personalization across channels
- AI-based decisioning for messaging and timing
- Integration with a wide range of external tools
Who It’s Best For:
- Marketing and lifecycle teams
- Companies with established data warehouses
- Organizations running multi-channel campaigns
- Teams focused on personalization at scale
Контактна інформація:
- Website: hightouch.com
- Twitter: x.com/HightouchData
- LinkedIn: www.linkedin.com/company/hightouchio

11. Lindy
Lindy is designed as a general-purpose AI assistant that works across everyday business tools like email, calendar, and messaging platforms. It handles tasks such as drafting emails, scheduling meetings, and pulling information from different sources. The idea is to reduce small, repetitive actions that tend to fill up the day.
What makes it a bit different is how it behaves proactively. It doesn’t just wait for instructions but can surface reminders, prepare context for meetings, or suggest next steps based on ongoing activity. Over time, it adapts to user preferences, which shifts it from a simple assistant to something closer to a lightweight operational layer across personal workflows.
Основні моменти:
- AI assistant for email, meetings, and scheduling
- Drafts messages and manages communication
- Connects across multiple work tools
- Provides proactive reminders and context
- Learns user preferences over time
- Supports day-to-day task automation
Who It’s Best For:
- Individuals managing busy schedules
- Teams handling frequent communication
- Professionals juggling multiple tools
- Roles with repetitive coordination tasks
Контактна інформація:
- Website: www.lindy.ai
- Email: support@lindy.ai
- Twitter: x.com/getlindy
- LinkedIn: www.linkedin.com/company/lindyai
![]()
12. Relevance AI
Relevance AI focuses on building AI agents for go-to-market work, including sales, marketing, and customer operations. It introduces the idea of an AI workforce, where multiple agents handle tasks like research, outreach, lead qualification, and follow-ups. These agents can be triggered by events, such as changes in a sales pipeline or incoming leads.
There’s a progression in how automation is applied. It can start with simple assistance, then move toward more autonomous workflows as processes become clearer. The system connects with common tools like CRM, email, and messaging platforms, allowing agents to operate within existing workflows instead of requiring a full rebuild.
Основні моменти:
- AI agents for sales and go-to-market workflows
- Automation of research, outreach, and follow-ups
- Multi-agent setup for different tasks
- Integration with CRM and communication tools
- Event-based triggers for automation
- Gradual shift from assisted to autonomous workflows
Who It’s Best For:
- Sales and revenue teams
- Companies with structured pipelines
- Organizations scaling outbound and inbound efforts
- Teams looking to automate repetitive GTM tasks
Контактна інформація:
- Website: relevanceai.com
- Twitter: x.com/RelevanceAI_
- LinkedIn: www.linkedin.com/company/relevanceai

13. CrewAI
CrewAI is built around the idea of multiple AI agents working together as a coordinated system. Instead of focusing on a single assistant, it allows users to create groups of agents that can divide and complete tasks across workflows. These agents can interact with tools, follow defined roles, and operate with some level of autonomy.
The platform provides different ways to build and manage these systems, from visual interfaces to APIs. There is also a focus on control and monitoring – tracking how agents perform, adjusting behavior, and ensuring outputs stay consistent. It’s designed more as an infrastructure layer for building agent-based workflows than a ready-made tool for one specific use case.
Основні моменти:
- Multi-agent system for complex workflows
- Visual builder and API-based setup
- Agents interact with tools and external systems
- Workflow tracing and monitoring
- Training and guardrails for agent behavior
- Scalable deployment across teams
Who It’s Best For:
- Engineering and technical teams
- Companies building custom AI workflows
- Organizations needing multi-step automation
- Teams experimenting with agent-based systems
Контактна інформація:
- Website: crewai.com
- Twitter: x.com/crewaiinc
- LinkedIn: www.linkedin.com/company/crewai-inc

14. Sierra
Sierra focuses on AI agents for customer experience, covering interactions across channels like chat, voice, and messaging. The platform is designed to handle conversations while also connecting them to actions, such as booking, account updates, or service requests. It aims to keep interactions consistent regardless of where they happen.
Another part of the system is how agents are built and improved. There are tools for defining behavior, testing scenarios, and adjusting performance over time. The platform also tracks interactions and extracts insights, which helps refine how agents respond and operate in future conversations.
Основні моменти:
- AI agents for customer communication across channels
- Supports chat, voice, email, and messaging platforms
- Tools for building and testing agent behavior
- Інтеграція із зовнішніми системами та джерелами даних
- Continuous improvement based on interaction data
- Focus on consistent customer experience
Who It’s Best For:
- Customer support and service teams
- Companies with multi-channel communication
- Organizations handling frequent customer interactions
- Teams looking to automate service workflows
Контактна інформація:
- Website: sierra.ai
- Email: security@sierra.ai
- Twitter: x.com/sierraplatform
- LinkedIn: www.linkedin.com/company/sierra

15. Moveworks
Moveworks is built as an AI assistant platform for internal business operations. It connects to different systems across a company – HR, IT, finance, and others – and allows employees to search for information or trigger actions through a single interface. The agent layer is used to handle requests, automate tasks, and reduce manual back-and-forth between teams.
Instead of focusing on one department, it spreads across the organization. The system combines search and execution, so a request can move from a question to an action without switching tools. It also supports multiple languages and integrates with a wide range of business applications, which makes it easier to apply across different teams.
Основні моменти:
- AI assistant for internal workflows and operations
- Combines search and task execution
- Works across HR, IT, finance, and other systems
- Інтеграція з кількома бізнес-додатками
- Supports multilingual environments
- Centralized interface for employee requests
Who It’s Best For:
- Large organizations with multiple internal systems
- Teams handling internal service requests
- Companies aiming to streamline operations
- Organizations with distributed or global teams
Контактна інформація:
- Website: www.moveworks.com
- Email: support@moveworks.com
- Twitter: x.com/moveworks
- LinkedIn: www.linkedin.com/company/moveworksai
- Address: 1400 Terra Bella Avenue, Mountain View, CA 94043
Висновок
If you step back and look at all of this, AI agents don’t really come across as some big, unified thing. They show up in different corners of the business, doing very different jobs. In one place, it’s handling support tickets. In another, it’s helping marketing teams push campaigns or pulling answers from internal data. Same idea underneath, but applied in very practical, sometimes quite narrow ways.
There’s also a bit of a pattern in how they’re being used. Most of these tools aren’t trying to replace how companies work. They sit on top of what’s already there – existing systems, existing processes, existing data. And when things are structured enough, they tend to fit in without much friction. When they’re not, you start to see where the limits are.
So it’s less about “using AI agents” as a concept, and more about figuring out where they actually help in everyday work. Usually, it’s the repetitive, slightly annoying tasks that no one really wants to spend time on. That’s where they seem to land first. Everything else still takes a bit more thought.